一、HDFS 架构
Hadoop 主要由HDFS(Hadoop Distributed File System)和MapReduce 引擎两部分组成。最底部是HDFS,它存储Hadoop 集群中所有存储节点上的文件。
HDFS 可以执行的操作有创建、删除、移动或重命名文件等,架构类似于传统的分级文件系统,HDFS 包括唯一的NameNode,它在HDFS 内部提供元数据服务;
DataNode 为HDFS 提供存储块。

HDFS 采用Master/Slave的架构来存储数据,这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode
Client:就是客户端。
1、切分文件:文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
2、与 NameNode 交互,获取文件的位置信息。
3、与 DataNode 交互,读取或者写入数据。
4、Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
5、Client 可以通过一些命令来访问 HDFS。
NameNode:就是 master,它是一个主管、管理者。
NameNode 负责管理整个分布式系统的元数据
1、管理 HDFS 的名称空间(namespace)。
Namenode维护文件系统的namespace,一切对namespace和文件属性进行修改的都会被namenode记录下来
2、管理数据块(Block)映射信息。
Namenode全权管理block的复制,它周期性地从集群中的每个Datanode接收心跳包和一个Blockreport。心跳包的接收表示该Datanode节点正常工作,而Blockreport包括了该
Datanode上所有的block组成的列表
3. DataNode 的状态监控
两者通过一段时间间隔的心跳来传递管理信息和数据信息,通过这种方式的信息传递,NameNode 可以获知每个 DataNode 保存的 Block 信息、DataNode 的健康状况、
命令 DataNode 启动停止等(如果发现某个 DataNode 节点故障,NameNode 会将其负责的 block 在其他 DataNode 上进行备份)。
4、文件系统元数据的持久化。
两个元数据管理文件:fsimage 和 editlog。
- fsimage:是内存命名空间元数据在外存的镜像文件;
- editlog:则是各种元数据操作的 write-ahead-log 文件,在体现到内存数据变化前首先会将操作记入 editlog 中,以防止数据丢失。
Namenode在内存中保存着整个文件系统namespace和文件Blockmap的映像。这个关键的元数据设计得很紧凑,因而一个带有4G内存的 Namenode足够支撑海量的文件
和目录。当Namenode启动时,它从硬盘中读取Editlog和FsImage,将所有Editlog中的事务作用(apply)在内存中的FsImage ,并将这个新版本的FsImage从内存中flush
到硬盘上,然后再truncate这个旧的Editlog,因为这个旧的Editlog的事务都已经作用在FsImage上了,这个过程称为checkpoint,checkpoint只发生在Namenode启动时。
5、配置副本策略,
6、处理客户端读写请求。
DataNode:就是Slave,NameNode 下达命令,DataNode 执行实际的操作。
1、存储实际的数据块。
2、执行数据块的读/写操作。
Secondary NameNode:并非 NameNode 的热备份(两个节点同时运行,一个挂掉了切换另一个)。
当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
1、辅助 NameNode,分担其工作量。
2、定期合并 fsimage和fsedits,并推送给NameNode。
3、在紧急情况下,可辅助恢复 NameNode。
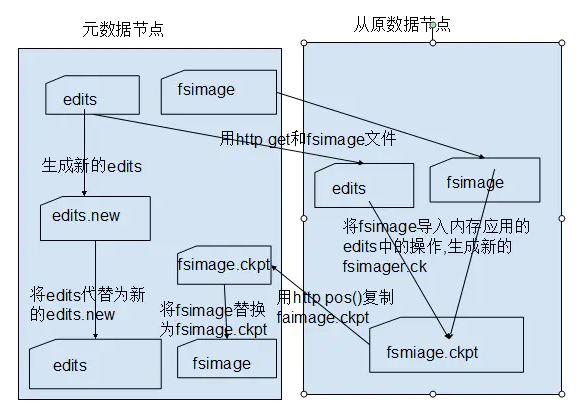
由于数据操作越多edits文件膨胀越大,但不能让他无限的膨胀下去,所以要把日志过程转换出来 放到fsimage中。由于NameNode要接受用户的操作请求,必须能够快速响应
用户请求,为了保证NameNode的快速响应给用户,所以将此项工 作交给了 SecondaryNode ,所以他也备份一部分fsimage的一部分内容。
执行过程:
从NameNode上 下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,同时重置NameNode的edits.默认在安装在
NameNode节点上。
三、hdfs的读写流程
参见:https://www.cnblogs.com/feiyumo/p/12541296.html
四、hdfs常用命令
hadoop fs -ls /
hadoop fs -lsr
hadoop fs -mkdir /user/hadoop
hadoop fs -put a.txt /user/hadoop/
hadoop fs -get /user/hadoop/a.txt /
hadoop fs -cp src dst
hadoop fs -mv src dst
hadoop fs -cat /user/hadoop/a.txt
hadoop fs -rm /user/hadoop/a.txt
hadoop fs -rmr /user/hadoop/a.txt
hadoop fs -text /user/hadoop/a.txt
hadoop fs -copyFromLocal localsrc dst 与hadoop fs -put功能类似。
hadoop fs -moveFromLocal localsrc dst 将本地文件上传到hdfs,同时删除本地文件。
五、HA
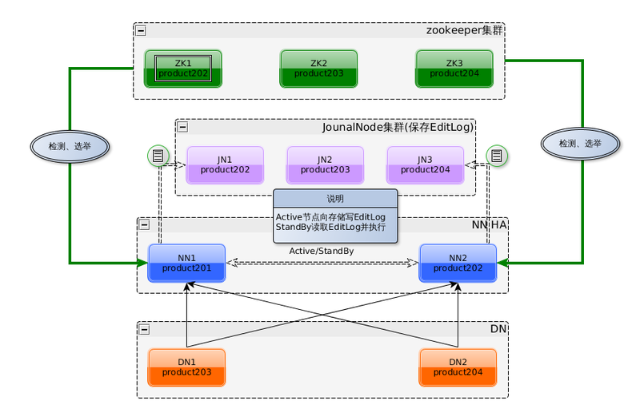
1、Active NameNode 和 Standby NameNode:两台 NameNode 形成互备,一台处于 Active 状态,为主 NameNode,另外一台处于 Standby 状态,为备 NameNode,
只有主 NameNode 才能对外提供读写服务;
2、ZKFailoverController(主备切换控制器,FC):ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到
NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换(当然 NameNode 目前也支持不依赖于 Zookeeper 的手动主备切换);
3、Zookeeper 集群:为主备切换控制器提供主备选举支持;
4、共享存储系统:共享存储系统是实现 NameNode 的高可用最为关键的部分,共享存储系统保存了 NameNode 在运行过程中所产生的 HDFS 的元数据。主 NameNode 和
备 NameNode 通过共享存储系统实现元数据同步。在进行主备切换的时候,新的主 NameNode 在确认元数据完全同步之后才能继续对外提供服务。
5、DataNode 节点:因为主 NameNode 和备 NameNode 需要共享 HDFS 的数据块和 DataNode 之间的映射关系,为了使故障切换能够快速进行,DataNode 会同时向
主 NameNode 和备 NameNode 上报数据块的位置信息。