Co-authors: Jon Lee and Wesley Wu
Apache Kafka is a core part of our infrastructure at LinkedIn. It was originally developed in-house as a stream processing platform and was subsequently open sourced, with a large external adoption rate today. While many other companies and projects leverage Kafka, few—if any—do so at LinkedIn’s scale. Kafka is used extensively throughout our software stack, powering use cases like activity tracking, message exchanges, metric gathering, and more. We maintain over 100 Kafka clusters with more than 4,000 brokers, which serve more than 100,000 topics and 7 million partitions. The total number of messages handled by LinkedIn’s Kafka deployments recently surpassed 7 trillion per day.
Running Kafka at such a large scale constantly raises various scalability and operability challenges for our overall Kafka ecosystem. To address such production issues, we maintain a version of Kafka that is specifically tailored to operations and scale at LinkedIn. This includes LinkedIn-internal release branches with patches for our production and feature requirements, and is the source of Kafka releases running in LinkedIn’s production environment.
We are pleased to announce that the code for LinkedIn’s Kafka release branches has been open sourced and is available at GitHub. Our branches are suffixed with -li after the base Apache release. In this post, we will share more details of the Kafka release that LinkedIn runs in production, the process workflow we follow to develop new patches, the way we upstream the changes we make, a brief summary of some of the patches we maintain in our branch, and how we generate releases.
Kafka ecosystem at LinkedIn
The streaming ecosystem built around Apache Kafka is a key part of our technology stack at LinkedIn. The ecosystem includes the following components:
- Kafka clusters, consisting of brokers
- Application with Kafka client
- REST proxy for serving non-Java client
- Schema registry for maintaining Avro schemas
- Brooklin for mirroring among clusters
- Cruise Control for Apache Kafka for cluster maintenance and self-healing
- Pipeline completeness audit and a usage monitor called “Bean Counter”
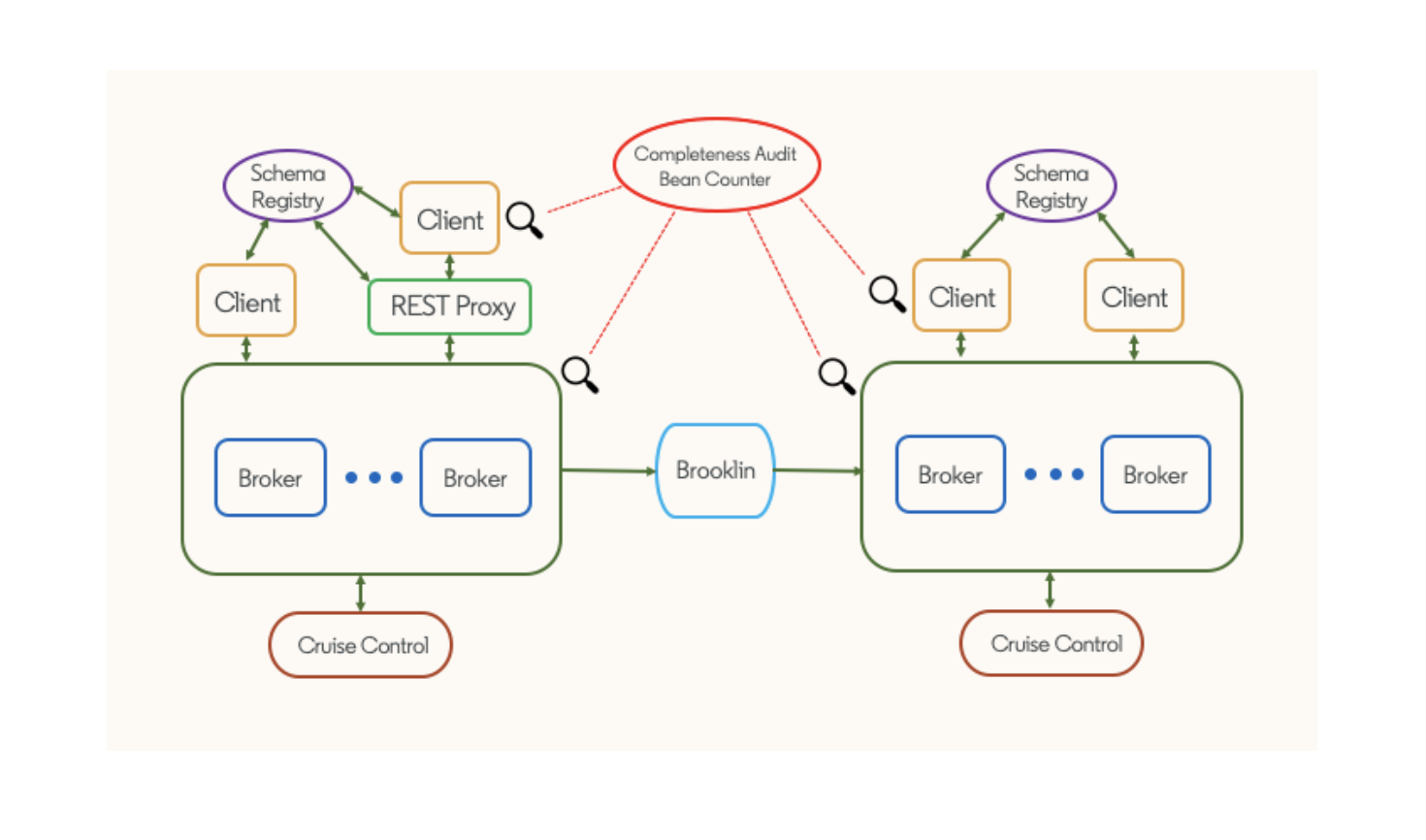
Kafka ecosystem at LinkedIn
LinkedIn Kafka release branches
As mentioned above, we maintain LinkedIn-internal release branches, where we commit patches to and create releases which can be deployed in LinkedIn’s production environment. Each release branch is branched off of the corresponding release branch of Apache Kafka (i.e., upstream). Please note that our version of Kafka is not a fork of Apache Kafka. We intend to maintain our releases as close as possible to upstream.
Having said that, we have two different ways to commit Kafka patches developed at LinkedIn:
Upstream first.
- Commit the patch to upstream first. We file a Kafka Improvement Proposal (KIP) if necessary.
- Cherry-pick the patch onto the current LinkedIn release branch or pick it up when a new release branch is created past the commit in upstream.
- Since the turnaround time for a patched LinkedIn release is longer if we upstream first, this is suitable for patches with low to medium urgency.
LinkedIn first (i.e., hotfix approach).
- Commit to the LinkedIn branch first.
- Attempt to double-commit to upstream. Note that the patch may not be accepted in upstream for various reasons. (More information below).
- Since the patch is immediately available for a LinkedIn release, it is suitable for patches with high urgency.
In addition to our own patches, we often need to cherry-pick other upstream patches for our releases. Therefore, you can find the following types of patches in a LinkedIn release branch:
- Apache Kafka patches: upstream patches committed up to the branch point.
- Cherry-picks: patches committed to upstream after the branch point, which were then cherry-picked to the release branch. They could be either our own “upstream first” patches or external patches.
- Hotfix patches: patches committed to the internal release branch first, and on their way to upstream.
- LinkedIn-only patches: hotfix patches that are of no interest to upstream, either truly internal to LinkedIn or else we attempted to commit them to upstream, but were rejected by the open source community. We do our best to avoid this, and strongly prefer patches with a clear exit criteria.
In other words, past the branch point of each LinkedIn release branch, there are two types of patches: cherry-picks and hotfixes. Among hotfix patches, we distinguish LinkedIn-only patches from the others that we intend to commit to upstream. The diagram below depicts this. Although the example below shows an internal release is created off every patch committed to the LinkedIn release branch, we create a release on an as-needed basis and thus each release may contain more than one patch since the previous release.
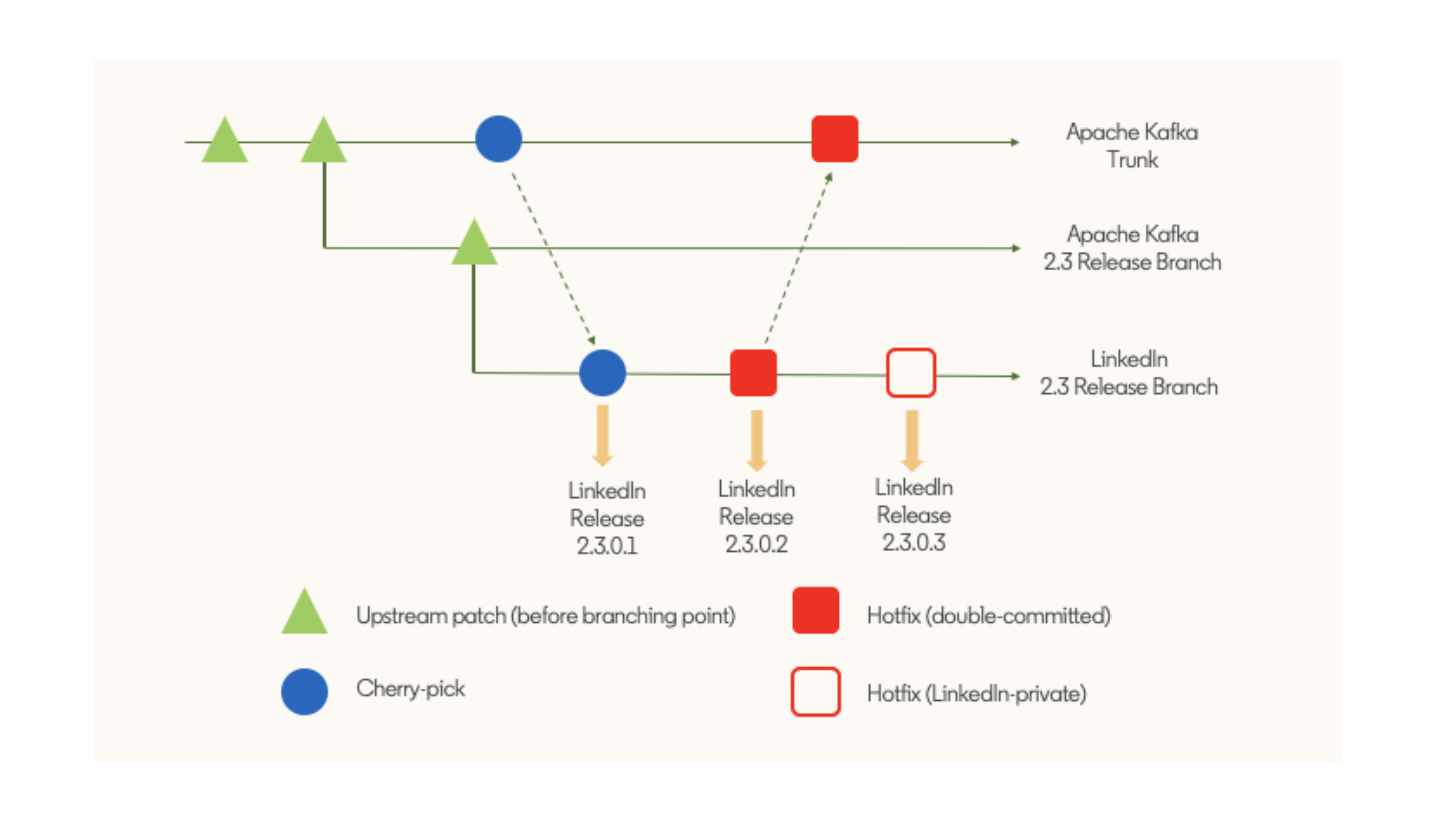
A closer look at a LinkedIn Kafka release branch
Development workflow
At LinkedIn, we follow the development workflow shown below for different patching processes.
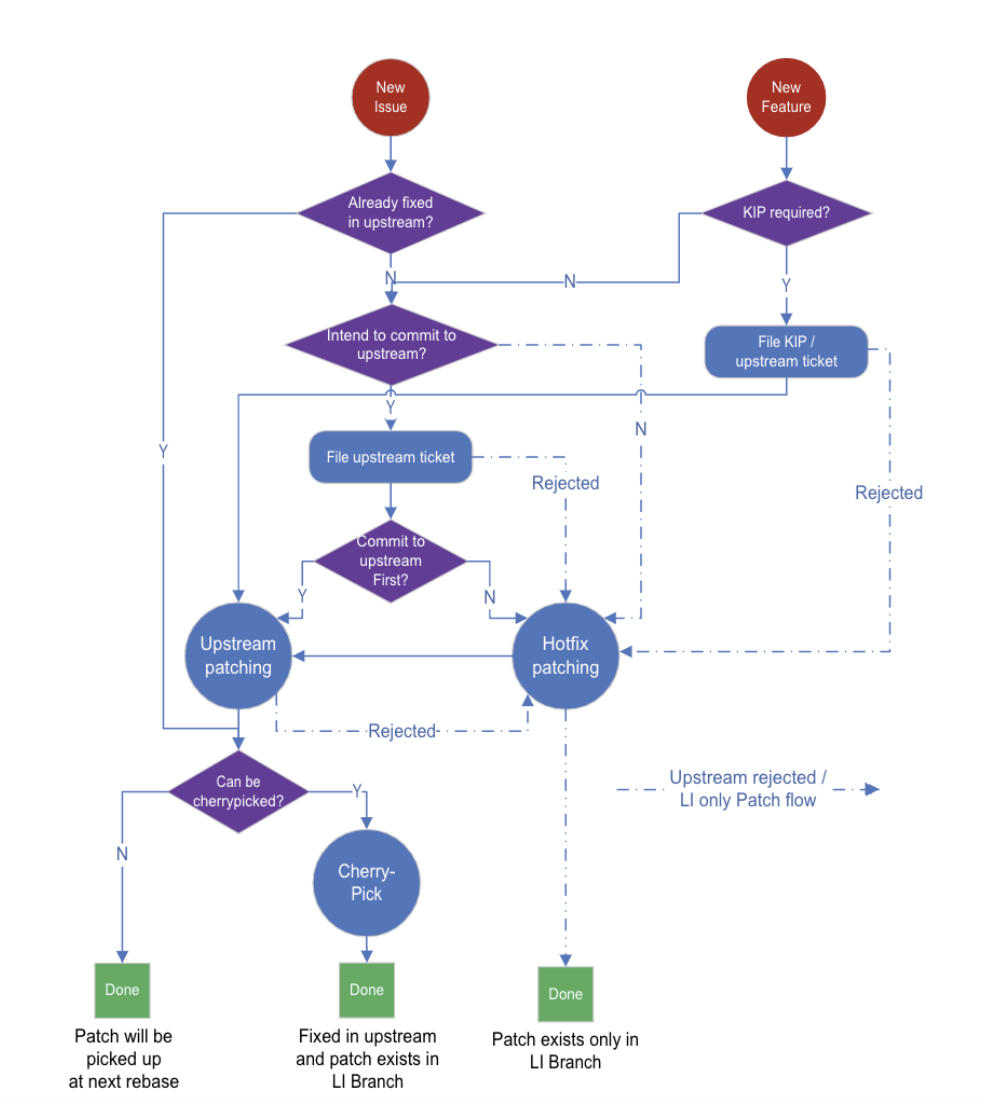
LinkedIn’s development workflow
The most important question to answer here is whether to choose the Upstream First route or LinkedIn First route (shown as “Commit to upstream first?” in the flowchart). Based on the urgency of the patch, the author should carefully assess the tradeoffs of both approaches. Typically, patches addressing production issues are committed as hotfixes first, unless they can be committed to upstream quickly (like within a week) and are small enough to be cherry-picked immediately. Feature patches for approved KIPs should go to the upstream branch first.
Patch examples
In this section, we present some of our representative patches, either made to upstream or ones that remain as LinkedIn-internal hotfixes. For patches discussed in the sections below, we plan to attempt upstreaming these patches if this has not already occurred.
Scalability improvements
At LinkedIn, some larger clusters have more than 140 brokers and host one million replicas in a single cluster. With those large clusters, we experienced issues related to slow controllers and controller failure caused by memory pressure. Such issues have a serious impact on production and may cause cascading controller failure, one after another. We introduced several hotfix patches to mitigate those issues—for example, reducing controller memory footprint by reusing UpdateMetadataRequest objects and avoiding excessive logging.
As we increased the number of brokers in a cluster, we also realized that slow startup and shutdown of a broker can cause significant deployment delays for large clusters. This is because we can only take down one broker at a time for deployment to maintain the availability of the Kafka cluster. To address this deployment issue, we added several hotfix patches to reduce startup and shutdown time of a broker (e.g., a patch to improve shutdown time by reducing lock contention).
Operational improvements
These types of patches are developed to resolve operational issues that arise with Kafka deployments. For example, SREs frequently remove bad brokers (e.g., brokers with a slow/bad disk) from and add new brokers to clusters. During broker removal, we want to maintain the same level of data redundancy to avoid the risk of data loss. To achieve this goal, SREs need to move replicas out of the broker that is going to be removed, prior to the actual removal. However, moving all replicas out of a broker turns out to be very difficult, because new topics are constantly created and may assign replicas on that broker. To address this problem, we introduced the maintenance mode for brokers. When a broker becomes a maintenance broker, it does not get assigned new topic partitions/replicas anymore. This feature enables us to easily move all replicas from a broker to another, and then cleanly take down a broker.
New features and direct contributions to upstream
With the upstream-first approach mentioned above, we contribute directly to upstream and later bring patches back into LinkedIn when a new release branch including those patches is created. Some of the recent major contributions from LinkedIn to upstream include:
- KIP-219: Improve quota communication
- KIP-380: Detect outdated control requests and bounced brokers using broker generation
- KIP-291: Separating controller connections and requests from the data plane
- KIP-354: Add a Maximum Log Compaction Lag
We also have added several new features that do not already exist in Apache Kafka, including:
- Supporting accounting on produce/consume usage for billing purposes. We needed to do this because there are users who send data without our standard Avro envelopes that could have been used for billing purposes and we wanted 100% coverage for cost-to-serve data.
- Enforcing a minimum replication factor on topic creation to minimize data loss risk in case of broker failure.
- A new offset reset policy to reset consumer offset to the closest offset. We have customers that are not satisfied with existing offset reset policies, and we provide an additional choice for them.
Creating a new release branch
So far, we have presented examples of patches or features that are included in the LinkedIn Kafka release branches. You may now wonder how LinkedIn creates a new release branch. We start with branching off from an Apache Kafka release branch (e.g., 2.3.0 branch to create LinkedIn Kafka 2.3.0.x branch). After that, we move hotfix patches from the previous LinkedIn release branch (e.g., 2.0.0.x branch) that are yet to be committed upstream, to the new LinkedIn Kafka branch. The diagram below depicts this process:
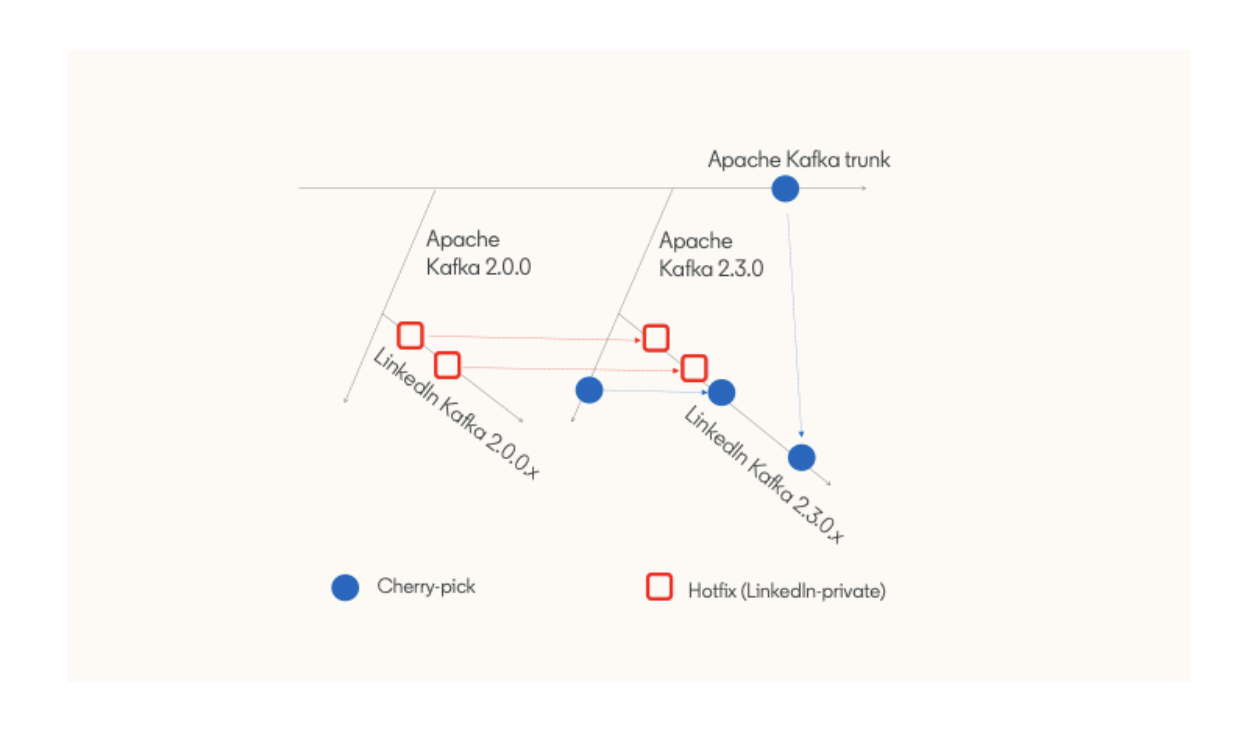
Creating a new LinkedIn release branch
During this process, we use a structured commit message to determine whether a hotfix patch needs to be moved to the new branch. For example, a structured commit message may contain an Apache Kafka ticket number, and we can use the ticket number to determine whether the hotfix patch is already merged to Apache Kafka branch. In addition, we periodically cherry-pick patches from the Apache Kafka branch to current LinkedIn Kafka branch.
Finally, we perform a certification process on the new release branch. We certify the new release against real production traffic using a dedicated certification framework, comparing a baseline version with the new release version under various tests. Certification covers tests such as rebalance, deployment, rolling bounce, stability, and downgrade. After the new version is certified, we release the new version for deployment. In short, each LinkedIn Kafka release is tested and validated for correctness and performance in a reasonably scaled cluster.
Conclusion
In this post, we have shared details about how LinkedIn customizes Apache Kafka to improve overall operability while addressing the ever-growing scalability requirements within the organization. We have been diligently contributing our patches upstream and have further made our release branches with internal patches publicly available. We encourage readers to try out our releases and report any issues. Although we do not accept external contributions nor do we offer support for our release at this time, we also encourage readers to directly contribute patches upstream.