问题导读
1.在Standalone部署模式下,Spark运行过程中会创建哪些临时性目录及文件?
2.在Standalone部署模式下分为几种模式?
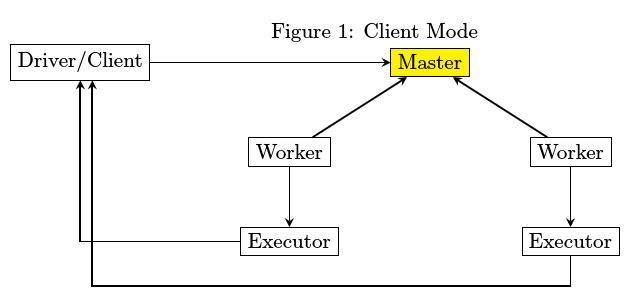
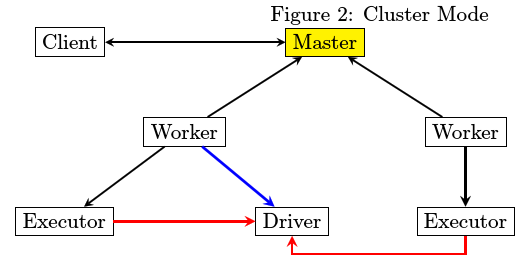
3.在client模式和cluster模式下有什么不同?
![]()
概要
部署时的第三方依赖
 spark访问cassandra
spark访问cassandra
- Master进程最为简单,除了spark jar包之外,不存在第三方库依赖
- Driver和Executor在运行的时候都有可能存在第三方包依赖,分开来讲
- Driver比较简单,spark-submit在提交的时候会指定所要依赖的jar文件从哪里读取
- Executor由worker来启动,worker需要下载Executor启动时所需要的jar文件,那么从哪里下载呢。

实验1

运行中的临时文件
实验2:不进行RDD Cache

进入spark-shell之后运行
- spark-shell>sc.textFile(“README.md”).flatMap(l=>l.split(“ “)).map(w=>(w,1)).reduceByKey(_ + _).foreach(println)
实验3: 进行RDD Cache
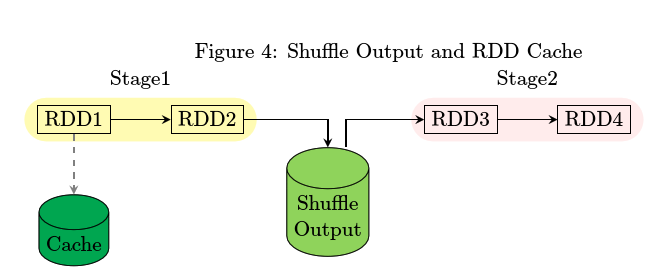
- spark-shell>val rdd1 = sc.textFile(“README.md”).flatMap(l=>l.split(“ “)).map(w=>(w,1)).reduceByKey(_ + _)
- spark-shell> rdd1.persist(MEMORY_AND_DISK_SER)
- spark-shell>rdd1.foreach(println)
配置项
文件的清理
- find $SPARK_LOCAL_DIRS -max-depth 1 -type f -mtime 1 -exec rm -- {} ;
而SPARK_WORK_DIR目录下的形如app-timestamp-seqid的文件夹默认不会自动清除。
那么可以设置哪些选项来自动清除已经停止运行的application的文件夹呢?当然有。
在spark-env.sh中加入如下内容
- SPARK_WORKER_OPTS=”-Dspark.worker.cleanup.enabled=true”
实验4
- import org.apache.spark._
- import org.apache.spark.{SparkConf, SparkContext}
- import org.apache.spark.SparkContext._
- import java.util.Date
- object HelloApp {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf()
- val sc = new SparkContext()
- val fileName = "$SPARK_HOME/README.md"
- val rdd1 = sc.textFile(fileName).flatMap(l => l.split(" ")).map(w => (w, 1))
- rdd1.reduceByKey(_ + _).foreach(println)
-
- var i: Int = 0
- while ( i < 10 ) {
- Thread.sleep(10000)
- i = i + 1
- }
- }
- }
提交运行
- spark-submit –class HelloApp –master spark://127.0.0.1:7077 --deploy-mode cluster HelloApp.jar
小结
相关文章
Spark技术实战之1 -- KafkaWordCount
http://www.aboutyun.com/thread-9580-1-1.html
Spark技术实战之2 -- Spark Cassandra Connector的安装和使用
http://www.aboutyun.com/thread-9582-1-1.html
Spark技术实战之3 -- 利用Spark将json文件导入Cassandra
http://www.aboutyun.com/thread-9583-1-1.html
Apache Spark技术实战之4 -- SparkR的安装及使用
http://www.aboutyun.com/thread-10082-1-1.html
Apache Spark技术实战之5 -- spark-submit常见问题及其解决
http://www.aboutyun.com/thread-10083-1-1.html
Apache Spark技术实战之6 --Standalone部署模式下的临时文件清理
http://www.aboutyun.com/thread-11862-1-1.html
http://www.tuicool.com/articles/RV3MFz