关系型数据库工作原理-数据结构(3)
本文翻译自Coding-Geek文章:《 How does a relational database work》。
原文链接:http://coding-geek.com/how-databases-work/#Buffer-Replacement_strategies
本文翻译了如下章节:
一、Array、Tree and Hash table
通过前面的章节, 我们已经理解了时间复杂和归并排序的概念,接下来我要介绍三种数据结构。这三种数据结构非常重要,它们是现代数据库系统的基石。我也会讲一讲数据库索引的概念。
二、Array-数组
二位数组是一种最简单的数据结构,一张数据库表就可以看成是一个二维数组。例如:
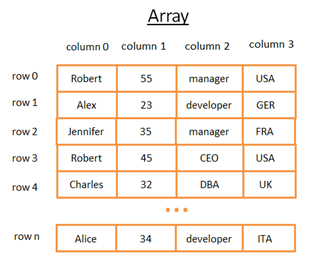
这个二维数组就代表一张有行和列的表结构:
- 每一行代表一个对象
- 每一行所有列的数据代表了一个对象的所有属性
- 每一列固定存储某一种类型的数据(如:integer、string、date…)。
尽管,二维数组用于存储表数据非常好,但是当你需要从数组中根据某个条件查询数据时,性能无法接受。
例如:你想找出在英国工作的所有人,你需要遍历每一行数据,判断他是否属于英国。这个过程需要执行N步操作(N取决于表的行数)。听起来,性能也不算太差,但有更快的方法吗?
肯定有,接下来就应该树结构登场了。
备注:现代数据库使用更高级的数组结构来存储表数据,如heap-organized tables或者index-organized tables。但是都没有解决如何在数组中根据一些列的过滤条件快速筛选数据的问题。
三、Tree and database index – 树和数据库索引
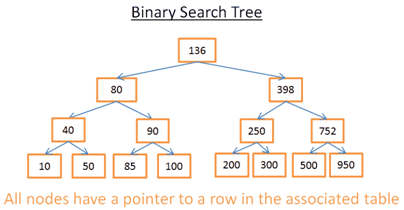
这棵树有15个节点。我们看一下如何从中找到208这个元素:
- 从根节点开始查找,根节点是136。因为 136<208,所以在136的右子树中查找。
- 398>208,在398的左子树中继续查找。
- 250>208,在250的左子树种继续查找。
- 200<208,在200的右子树中查找。但是200没有右子树。没有找到208(因为如果能找到的话,它应该在200的右子树上)。
接着看一下如何查找40这个元素:
- 也是从根节点136开始查询。因为136>40,所以在136的左子树中查询。
- 80>40,在80的左子树中查找
- 40=40, 元素找到了!提取40这个节点中存储的对应数组的行号索引。
- 有了这个行号索引,想拿这行的数据,就能立即获取到(数组的下标访问)。
最终,两次查询的操作步骤数都是树的高度。如果,你仔细阅读过merge sort章节,应该知道树的高度是log(N),所以该查找算法的时间复杂度是O(log(N))。还不错。
(一)Back to our problem – 回到问题上来
文章内容非常抽象,让我们回到问题上来。除了简单的整数型数据,考虑一下字符串,它是用于在前面的表中表示某个人的所属国家信息的。假设,你已经构建了一个树,包含前面表中的“country”字段数据。
- 你想知道哪些人在UK工作
- 你需要查找树,找到UK的节点。
- 在UK节点内,你能找到所有在UK工作人的对应数组行号索引信息。
这个查询操作仅耗费了Log(N)步操作,而不是直接在数组中查询所需要的N步。现在你也能猜到数据库索引是什么东西了吧?
你能为任意多列数据建立索引(一列字符串,一列整型数,2列字符串,一列整型 + 一列字符串,一列日期类型等等)。只要你对这些列实现了比较函数,你就能控制主键在树中的排列顺序(数据库已经为基本数据类型实现了比较函数)。
(二)B+ tree index – B+树索引
尽管上面的二叉树在查询某个固定值时工作得很好,但是如果要查询某个范围内的所有数据,性能就非常低。它需要花费N步操作,因为需要比较树中的每一个节点以判断它是否在指定的范围内。此外,这种方式也很耗费I/O资源,因为要读取整个索引树。我们需要找到一种高效的范围查询方法(range query)。为了解决这个问题,现代数据库使用B+树,B+树是前面二叉查询树的优化。在B+树里面:
- 只有叶子节点存储关联表的每一行数据对象的指针(译者注:这里的指针是指能快速找到数据本身的数组行号,哈希表的key等索引,不仅是C 语言中的pointer, 下同)。
-
其它节点的用途只在查询的时候,帮助路由到想找的叶子节点。
如上图所示,B+树存储了更多冗余的节点(2倍)。树内部多出了一些附属节点,这些“decision nodes”的作用是帮助你找到正确想要的叶子节点(存储了表数据指针的节点)。B+树的查询时间复杂度仍然是Log(N), 树仅仅只是多出了一层。最大的差异是,叶子节点中存储了指向下一个节点的指针。
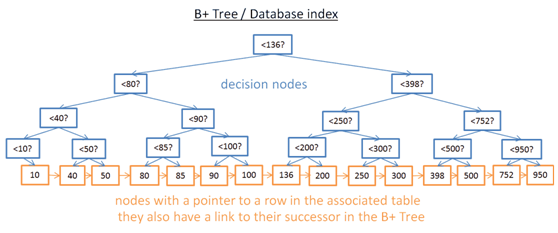
在这个B+树里面,如果你查找40到100之前的数据:
- 你只需要查询值为40的节点(或者比40稍大的节点,如果40的节点不存在的话)。查询方式跟之前的二叉树一样。
- 收集40后继的节点,通过它存储的指向后继结点的指针,直到遇到100(或者比100少大的数).
假如,你需要查询M个节点,树有N个节点。查询指定的值(40)的时间复杂度是Log(N), 跟之前的二叉树查询一样。但是,一但你找到了节点(40),你还需要通过M步操作,遍历收集M个后继结点。B+的range query的时间复杂度是O(M+Log(N)), 相比之前二叉树O(N)复杂度,性能提升很多。数据量越大,性能提升越明显。你不需要读取整颗树,这也意味着更小的磁盘I/O读取。
但是,这也带来了新的问题(再一次遇到问题)。如果你往数据库添加或者删除一行记录,同时也需要在B+树中更新数据:
- 你需要保证B+树中的节点顺序,否则你无法在一个混乱的树中查找节点。
- 你必须要保证叶子节点的从小到大的顺序排列,否则range query的时间复杂度将由O(Log(N))退化为O(N)。
换句话说,B+树必须要有自我调整树平衡性和节点顺序的能力。谢天谢地,智能化的数据删除和数据插入操作使得B+树的能保持以上特征。这也带来了成本:插入和删除数据的时间复杂度是O(Log(N)), 这也是为什么你经常会听到这样一种观点:索引太多不是什么好事。实际上,这会降低插入/更新/删除操作的效率,因为数据库需要同时更新表的索引,每个索引花费O(Log(N))的时间。
译者注:凡事都有两面,有利必有裨;选择什么样的数据结构,是根据你的应用场景来的。
另外,索引也会增加tansaction manager的复杂度(最后一张将讲到tansaction manager)。
更多的细节,你可以在维基百科上搜索B+ Tree。如果你想要一个B+树实现的样例,你可以读一下这篇文章(https://blog.jcole.us/2013/01/07/the-physical-structure-of-innodb-index-pages/), 这篇文章的作者是MySQL的核心开发人员。他详细讲述了innoDB(MySQL数据库引擎)是如何实现索引的。
四、Hash Table – 哈希表
最后一个重要的数据结构是hash table。当你需要快速查找一个数据时,hash table非常有用。另外,理解了hash table将帮助我们理解后面将提到的一种常用数据库连接技术:hash join。Hash table也经常用于存储一些数据库的内部管理数据,如lock table,buff pool等。这些概念在后面都会讲到。
Hash table是一种能根据关键字快速查找数据的数据结构类型。构建hash table需要定义如下一些内容:
1) 对象关键字
2) 为关键字定义的哈希函数(hash function)。对象的关键字用哈希函数计算的结果表示了对象存储的位置(称为buckets)。
3) 关键字比较函数。一旦找到了对象所在的bucket,接下来需要在bucket内部,通过比较函数找到对应的对象。
(一) A simple example - 一个hash table的样例
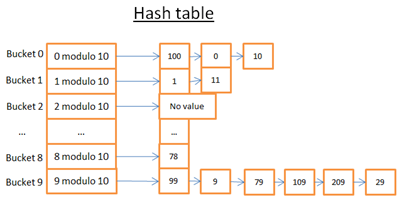
- 如果数字的最后一位是0,将数值存储到bucket 0中
- 如果数字最后一位是1,将数值存储到bucket 1中
- 如果数字最后一位是2,将数值存储到bucket 2中
- …..
比较函数我采用判断两个整型数值是否相等的方法比较。
我们看一下如何找到hash table中找到元素78:
- 通过哈希函数计算得到哈希值8
- 在bucket 8中查找元素,第一个元素就是78
- 返回元素78
- 查询只需要执行两个步骤:第一步是计算哈希值,确定bucket位置;第二步在bucket中查看元素。
我们再看一下如何查找元素59:
- 计算哈希值,得到9
- 在bucket中查找元素59。第一个元素是99,99!=59,99不是要查找的元素。
- 采用同样的方式,查找第二个元素(9),第三个元素(79),… 最后一个元素(29)。
- 不存在59这个元素
- 本次查询执行了7步操作
(二)A good hash function – 一个好的哈希函数
如你所见,查询不同的值,时间复杂度是不同的。
如果你将哈希函数改为除以1000000取模(取数字的最后6位数,作为bucket标识)。上面的第二次查询只需要一步(在bucket 59中没有任何数据)。找一个好的哈希函数,保证每个bucket中存储尽可能少的数据,是非常困难的。
在上面的例子中找一个好的hash function非常容易。但这仅仅是一个简单的样例,如果关键字是如下数据类型,将非常困难:
1. 一个字符串(例如表示人的名)
2. 两个字符串(例如同时表示人的姓和名)
3. 两个字符串 + 一个日期(例如表示人的姓、名及生日)
设计一个好的hash function,哈希表的查询时间为O(1)。
五、Array VS Hash table
为什么不使用数组? 问得好。
- Hash table支持将部分内容加载到内存,另一部分保存在磁盘上。不必把整颗树加载到内存,节省内存空间。
- 数组必须使用连续的内存空间。如果要加载一张大表数据到内存,很难找到一大片连续的内存空间。内存分配失败的风险很大。
- Hash table支持选择你想要的任意字段作为关键字(例如:人的所属国家,加上人的姓名。任意组合)。
想了解更多的信息,你可以读一下介绍Java如何实现hash map的文章,它是hash map高效实现的一个样例。理解本文中概念,你不需要懂JAVA。
https://blog.csdn.net/ylforever/article/details/51278954