
1.
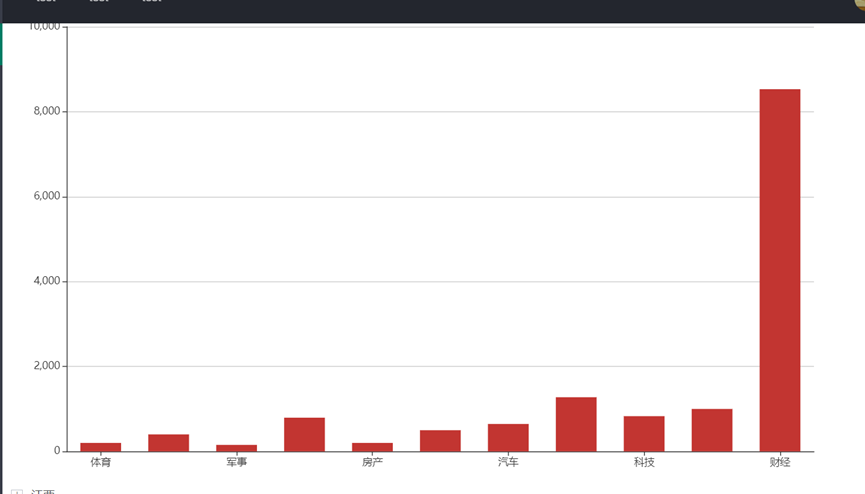
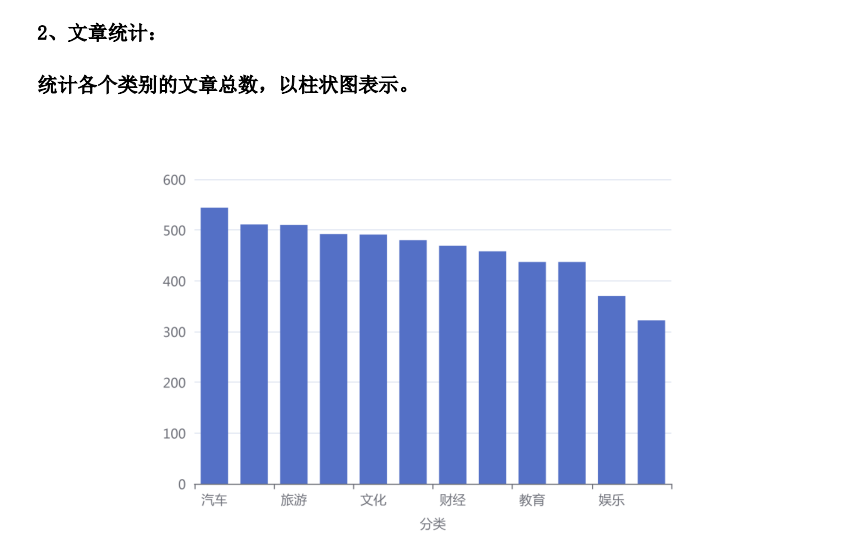
#各类文章数统计 def class_text_num(): sql="SELECT count(channelName) as num,channelName FROM new_class.newdata group by channelName;" res=query_mysql(sql) return res Echarts //获取格式设置 var chartDom = document.getElementById('bar'); var myChart = echarts.init(chartDom); var option; option = { tooltip: { trigger: 'axis', axisPointer: { type: 'shadow' } }, grid: { left: '3%', right: '4%', bottom: '3%', containLabel: true }, xAxis: [ { type: 'category', data: ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'], axisTick: { alignWithLabel: true } } ], yAxis: [ { type: 'value' } ], series: [ { name: 'Direct', type: 'bar', barWidth: '60%', data: [10, 52, 200, 334, 390, 330, 220] } ] }; myChart.setOption(option); window.onresize = myChart.resize; $.ajax({ type: "GET", url: "/bar", dataType: "json", success: function(data){ option.xAxis[0].data=data.name option.series[0].data=data.values myChart .setOption(option) } });
三。四
全部文章统计与各类文章统计原理一样。
使用jieba进行进行词频统计
先将文章都提取出来转换为txt格式

体育 a
综合体育最新 b
军事c
娱乐d
体育焦点e
房产f
教育g
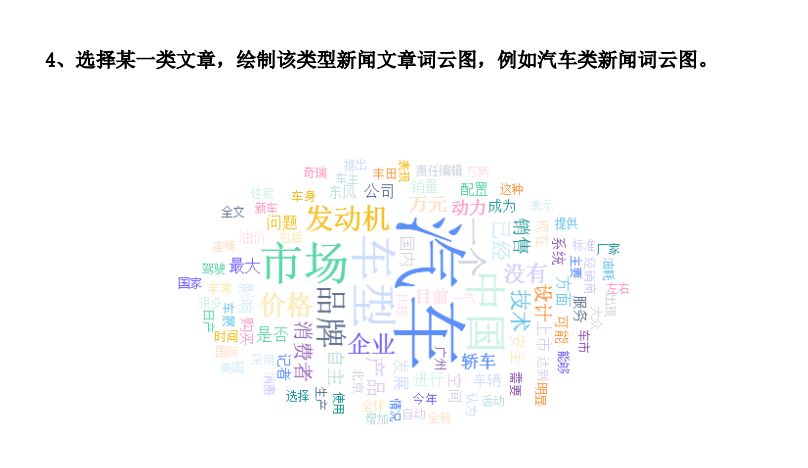
汽车h
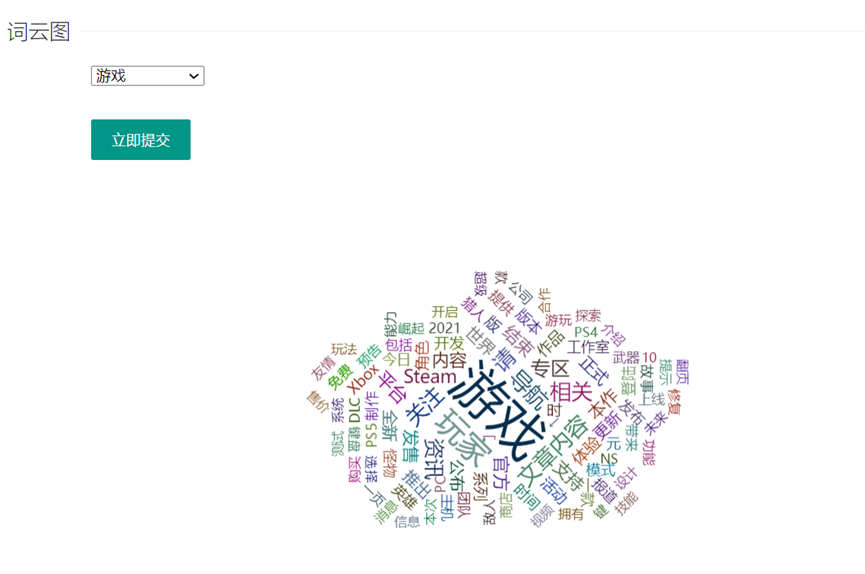
游戏i
科技j
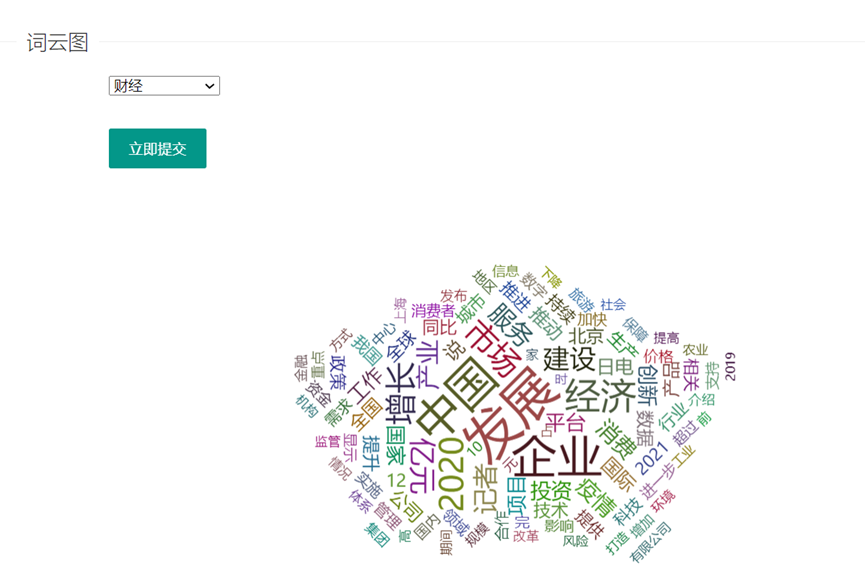
财经k
然后读取文件进行分词统计
article = open('data/'+str+'.txt', 'r',encoding='utf-8').read()
dele = {'。','!','?','的','“','”','(',')',' ','》','《',',','你们','自己','我们','他们'}
words = list(jieba.cut(article))
articleDict = {}
articleSet = set(words)-dele
for w in articleSet:
if len(w)>1:
articleDict[w] = words.count(w)
articlelist = sorted(articleDict.items(),key = lambda x:x[1], reverse = True)
return articlelist
将结果存入数据库
从数据库查询到前端展示
通过下拉框选择全部或各个分类的词频统计情况