今日添加了数据清洗的部分,对原先的结构进行了修改。
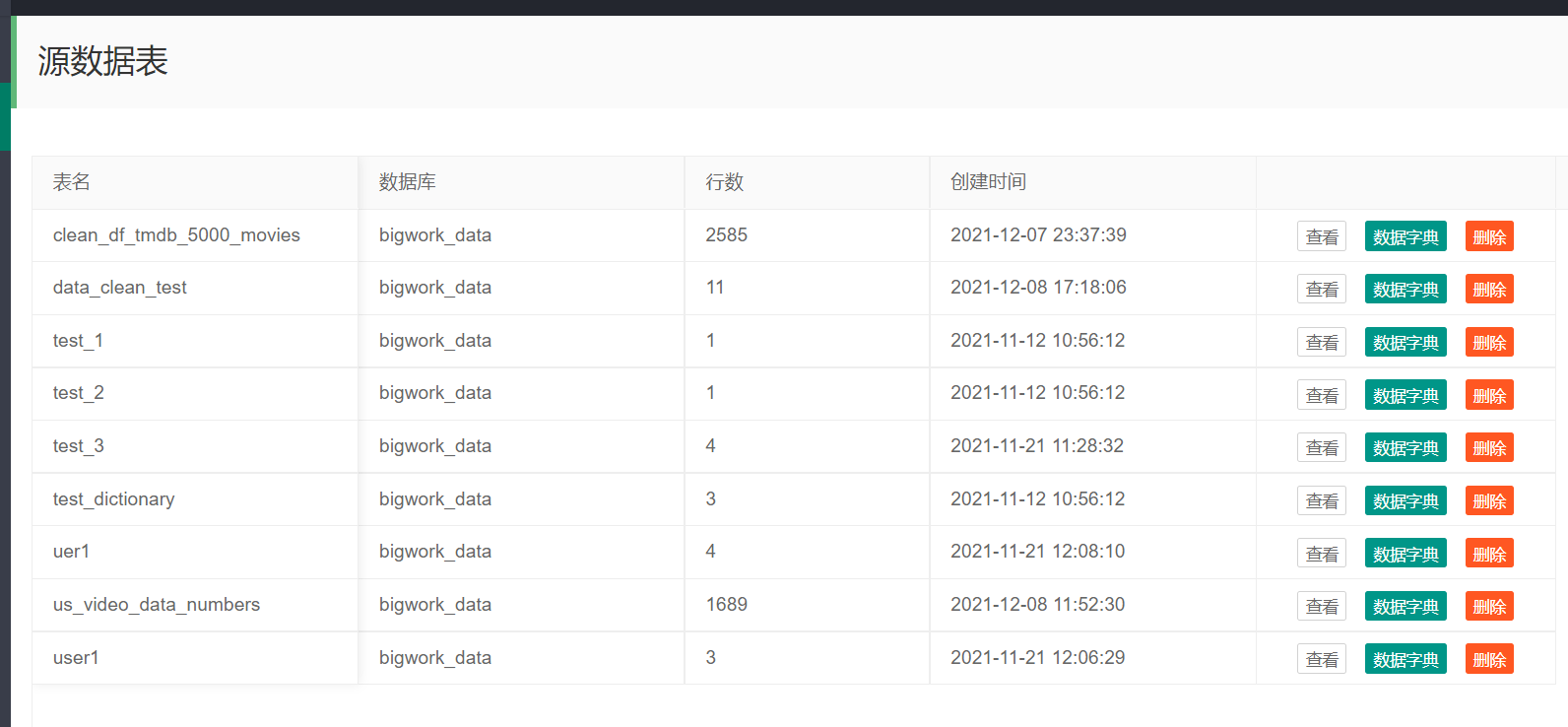
在查看已创建表部分增加了查看已清洗表:

现在还没表,数据清洗部分写完后就有表了,已经清洗表的操作与原始数据表一样:这一部分的代码实现重用,主要靠表名与数据库来区分原数据表与已清洗数据表。
今天主要完成了数据清洗的重复值去除与缺省值统计的功能:
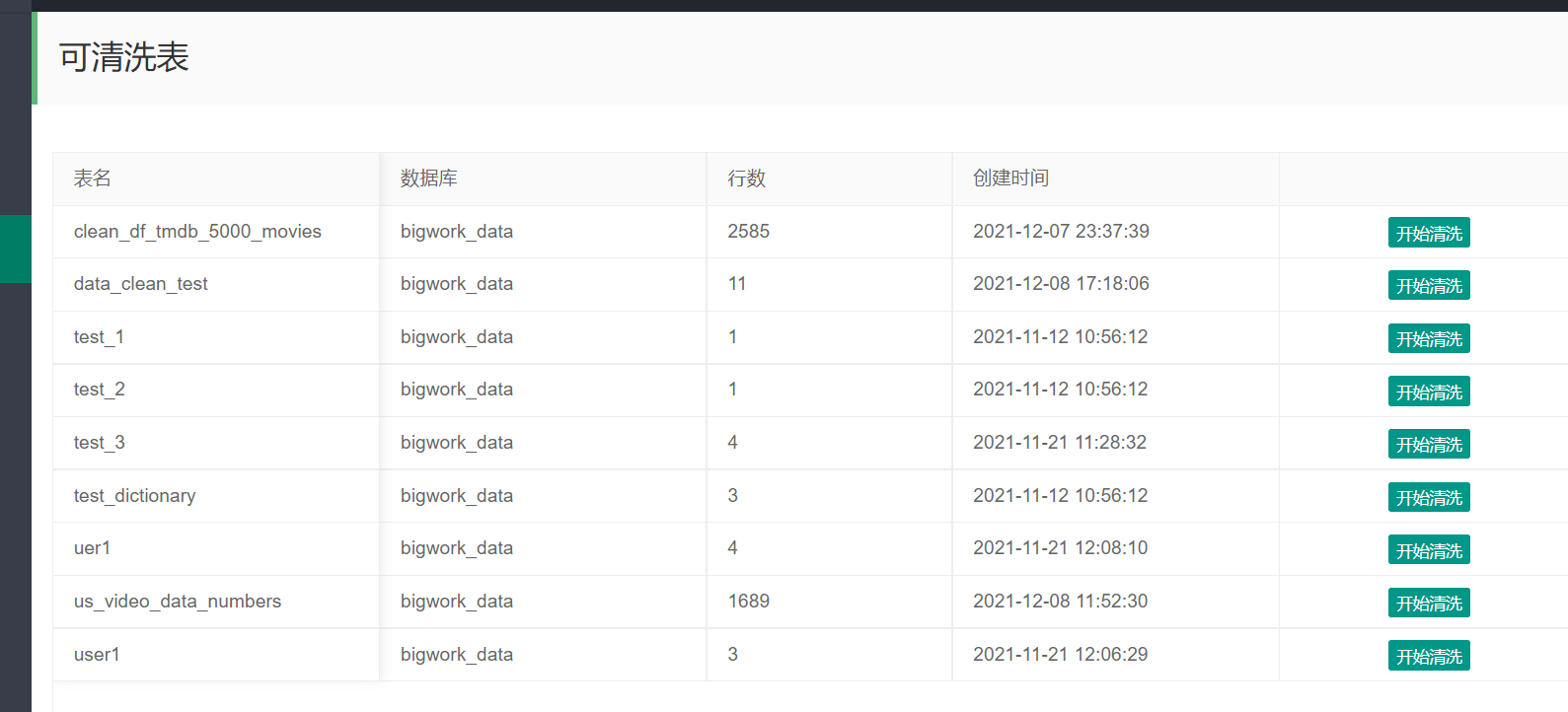
先显示可清洗的表
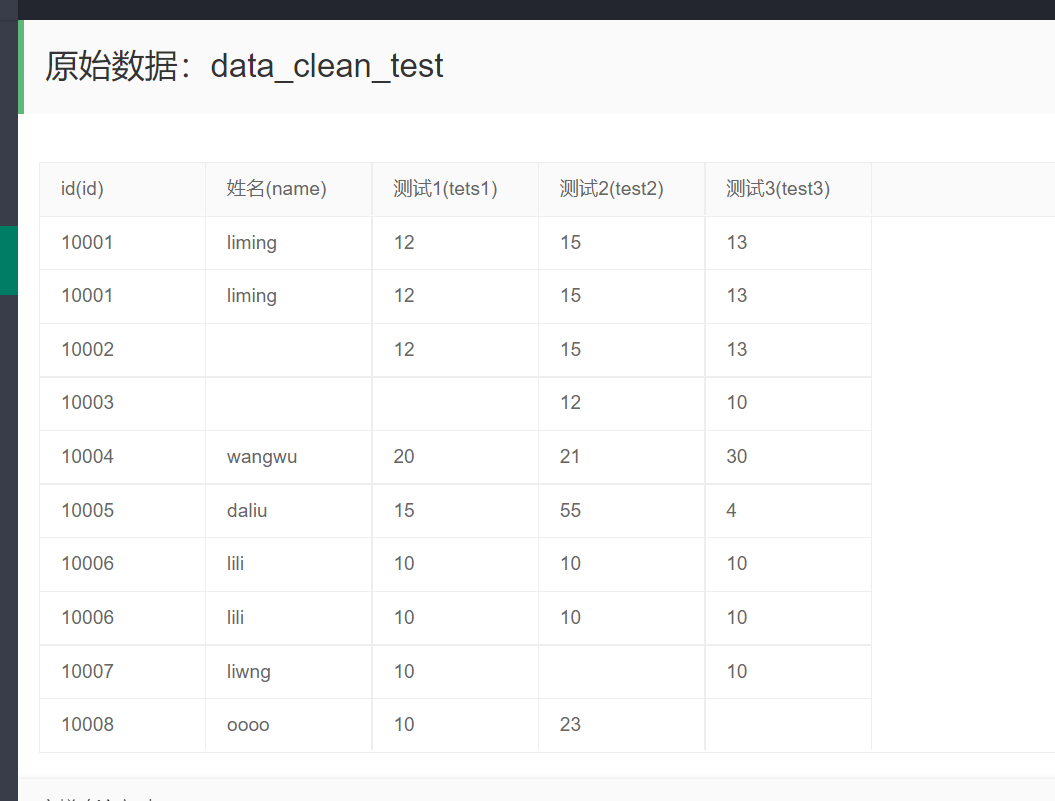
点击开始清洗 ,先显示原始数据
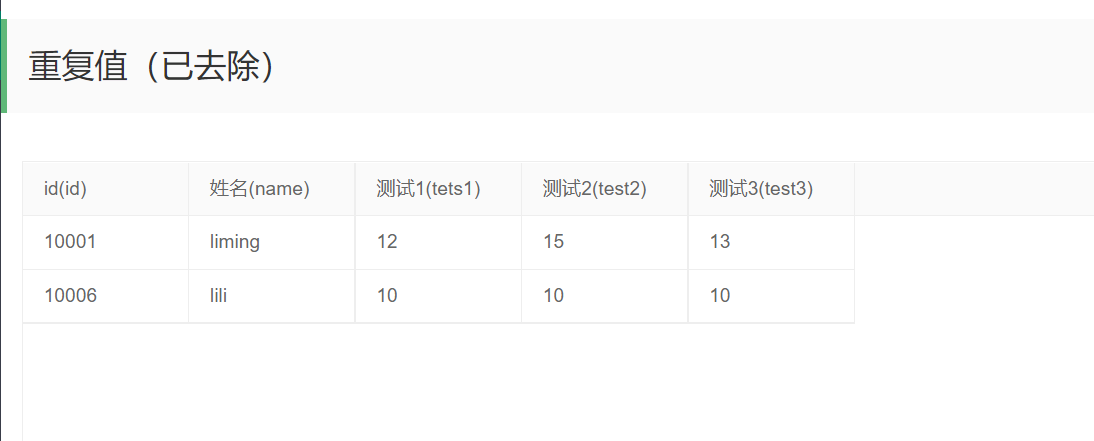
然后显示重复值,此时数据的重复值已经去除
然后显示缺省值的统计信息:

点击查看缺省值可以查看缺省值:

涉及的html代码较多,只把数据清洗的代码粘了过来
#数据清洗部分 #重复值 @app.route('/data_clean_scame') def data_clean_scame(): table_name = request.values.get("table_name") database_name = request.values.get("database_name") #data_came重复数据,data_remove_came去重后数据 都为pd类型 data_came, data_remove_came=dataclean.data_clean_came(table_name,database_name) global data_clean data_clean=data_remove_came#去重后的数据保存,为以后处理缺省值 print("去重后数据") print(data_clean.head()) num_0 = data_came.shape[0]#行数 num_1 = data_came.shape[1]#keys数 data_list = [];#json数组 for i in range(num_0): json_data = {} for j in range(num_1): json_data[data_came.keys()[j]] = data_came.values[i][j] data_list.append(json_data) return jsonify({"code": 0, "msg": "", "count": num_0, "data": data_list}) #缺省值 @app.route('/data_clean_nan') def data_clean_nan(): num_0 = data_clean.shape[0] num_1 = data_clean.shape[1] data_nan=[] json_data = {} for i in range(num_1): flag = 0 for j in range(num_0): if (data_clean.values[j][i] == ''): flag = flag + 1 data_nan.append({"keys":data_clean.keys()[i],"num":flag}) return jsonify({"code": 0, "msg": "", "count": num_1, "data": data_nan}) #查看缺省值 @app.route('/get_data_clean_nan') def get_data_clean_nan(): num_0 = data_clean.shape[0] num_1 = data_clean.shape[1] data = [] flag=0 for i in range(num_0): json_list = {} for j in range(num_1): if (data_clean.values[i][j] == ''): for k in range(num_1): json_list[data_clean.keys()[k]] = data_clean.values[i][k] data.append(json_list) flag=flag+1 break return jsonify({"code": 0, "msg": "", "count": flag, "data": data}) #数据清洗部分
def data_clean_came(table_name,database_name): conn,cursor=pymysql_conn(database_name) qu_sql = "SELECT * FROM "+ table_name df = pd.read_sql_query(qu_sql, conn) close_conn_mysql(conn,cursor) data1=df.drop_duplicates(keep=False) data2=df.drop_duplicates(keep='first') data_came=data2.append(data1).drop_duplicates(keep=False) data_remove_came=df.drop_duplicates() return data_came,data_remove_came pass