这个系列的文章是一只试图通过产品角度出发去理解复杂庞大搜索引擎的汪写出来的,不足之处很多,欢迎广大技术、非技术同学阅读后指正错误,我们一起探讨共同进步。
本篇主要介绍搜索引擎的架构、网络爬虫、及索引建立。
一、搜索引擎基本信息
1.1 什么是搜索引擎
通俗来讲就是从互联网海量信息中捞出用户感兴趣的内容提供给用户。
1.2 发展历程
分类目录的:纯人工收集整理,代表是导航,如yahoo和hao123
—> 文本检索:采用信息检索模型查询关键词与网页文本的相关程度
—> 链接分析:利用网页间的链接关系分析网页重要性,代表技术google的pageRank
—>用户中心:理解用户需求为核心,典型千人千面--淘宝推出的商品推荐算法(比如电商平台)。
1.3搜索引擎基本架构
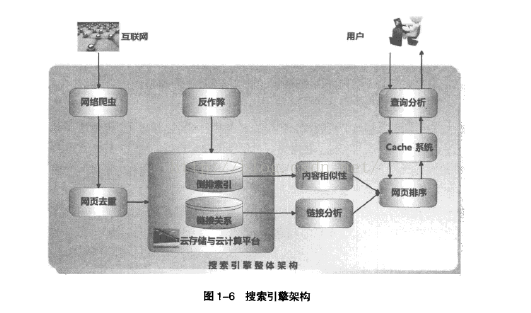
来源这就是搜索引擎
该架构主要有三方面的作用:
1、通过爬虫获得互联网上的海量网页信息,存储在本地并建立索引方便查找;
2、用户输入查询query,解析查询意图,并将query分发进行查询;
3、使用query通过各种算法对索引中的文档(网页)排序,返回最符合意图的若干条结果。
本篇主要从第一方面作用来介绍搜索引擎。
二、网络爬虫
2.1通用爬虫框架
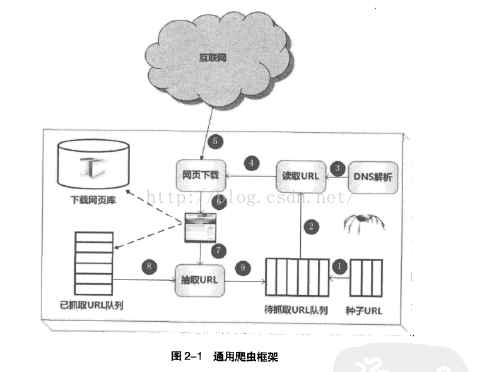
爬取流程:
选取部分网页作为种子url,放入待抓取url队列
—>读取待抓取url通过DNS解析,下载网页
—>将下载的url存储到本地页面库并建立索引,url放入已抓取url队列
—>解析已下载url,抽取所有链接,与已抽取url队列去重后放入待抓取url
—>继续下载待抓取url队列
—>形成循环,直至待抓取url队列为空。
2.2 爬虫类型
批量型爬虫(batch crawler):有明确抓取范围和目标,达到目标即停止。
增量型爬虫(incremental crawler):持续不断抓取,对抓到的网页定期更新。
垂直型爬虫(focused crawler):抓取阶段识别网页是否与主题相关,判断是否抓取。
2.3 爬虫抓取策略
目的:优先选择重要网页进行抓取。
宽度优先遍历策略(breathfirst):将新下载网页包含的链接直接追加到待抓取URl队列末尾。该策略隐含了一些网页优先级假设。
非完全pagerank策略(partial pagerank):已下载和待抓取url一起形成网页集合,在集合内进行pagerank计算,将待抓取url按照pagerank排序。为提升效率,当新下载网页数超过K 个重新计算一遍pagerank,对于新抽取出的且没有pagerank值的网页,将该网页所有入链传到pagerank值汇总,作为临时pagerank值进行比较。
OCIP策略(online pageimportance computation):每个页面给予相同现金(cash),下载某个页面P后,页面p的cash均分到包含的每个链接上,最终根据链接cash大小排序下载。
大站优先策略(larger sites first):优先下载等待下载页面最多的网站。
2.4 网页更新策略
目的:决定何时更新已下载的网页,使得本地数据与互联网原始页面内容一致。
历史参考策略:过去频繁更新的网页未来也会频繁更新。
用户体验策略:保存网页的多个版本,根据每次内容变化对搜索质量影响得到平均值,作为判断抓取更新的依据。
聚类抽样策略:网页聚类。具有相同属性的网页更新时间相同
2.5 暗网抓取方法
对于存储于数据库的无法获得的网页信息,采用富含信息查询模板方式来抓取。
判断是否是富含信息查询模板的方法是ISIT算法。基本思想是从一维模板开始逐个考察,若是富含信息查询模板,则扩展到二维模板,如此类推逐步增加维数,直至无法再找到富含信息查询模板。
爬虫的目的就是尽量获得最新、最全的网页信息存储到本地。
三、建立索引
爬虫将文档(即网页)信息下载到本地后,需要对文档建立倒排索引。倒排索引就是抽取文档中的单词,建立单词与文档的对应关系,这样就能通过关键词的匹配查找到相应的文档。
3.1名词解释
TF:单词频率
DF:文档频率
单词词典:维护文档集合中出现的所有单词相关信息,同时记录单词对应的倒排列表在倒排文件中的位置信息。
文档编号(document id):文档集合内每个文档赋予一个唯一的内部编号,在存储时为压缩数据使用文档编号差值(D-gap)来存储。
倒排列表(postinglist):记载出现过某个单词的所有文档的文档列表及单词在文档中出现的位置。每条记录称为一个倒排项(posting)。

倒排文件(inverted file):所有单词的倒排列表顺序地存在磁盘的某个文件里。
倒排索引(inverted index):实现单词-文档矩阵的一种具体存储形式。通过倒排索引,可以获得包含这个单词的文档列表。由两部分组成:单词词典、倒排文件。
3.2 索引建立
3.2.1 单词词典的建立
常用的数据结构是哈希表和树形词典结果
哈希加链表:主体为哈希表,每个表项保存指针,指向相同哈希值单词形成的冲突链表。
树形词典结构:词典项需要按照大小排序,属于层级查找结构。(说实话没弄明白)
3.2.2 索引建立
两遍文档遍历法(2-pass in-memory inversion 全内存索引创建):第一遍扫描统计信息(包括文档个数、单词个数、单词出现信息DF等)并分配内存等资源,做准备工作。第二遍扫描,填充第一遍扫描所分配的内存空间。
本方法需要内存足够大,且两遍扫描速度较慢。
排序法(sort-based inversion):分配固定大小空间用来存放词典信息和索引中间结果,空间被耗光时,中间结果写入磁盘清空内存,用作下一轮存放索引中间结果的存储区。
归并法(merge-based inversion):整体流程与排序法类似,但排序法在内存中放的是词典信息和三元组数据,二者间并没有直接联系,归并法是在内存中建立起目前处理文档子集的整套倒排索引;中间结果写入磁盘时,排序法将三元组数据排序后写入磁盘临时文件,词典一直保留在内存中,归并法将单词和对应倒排列表写入磁盘,随后彻底清空所占内存。
3.2.3 索引的更新
网页在不断变化,为保证索引能实时动态更新,还需要添加上临时索引、已删除文档列表。
临时索引:内存中实时建立的倒排索引。
已删除文档列表:存储已删除文档的id,形成文档ID列表。
文档被更改时,原先文档放入删除队列,解析更改后的文档内容放入临时索引中,通过该方式满足实时性。用户输入query查询时从倒排索引和临时索引中获得结果,然后利用删除文档列表过滤形成最终搜索结果。
临时索引的更新策略:
1、完全重建:新增文档超过一定数量,对新老文档合并后重新建立索引。
2、再合并策略:新增文档超过一定数量,临时索引合并到老索引中。
3、原地更新策略:增量索引的倒排列表追加到老索引相应位置的末尾。
4、混合策略:将单词根据不同性质分类,不同类别单词采取不同的索引更新策略。
3.2.4 索引的查询
常用的两种查询策略
一次一文档:以倒排列表中包含的文档为单位,将文档与查询的最终相似性得分计算完毕再计算另外一个文档的得分。
一次一单词:以单词为单位,计算文档对于搜索单词的得分,最后将所有单词得分相加。
3.3索引压缩
用户查询时需要将倒排列表信息从磁盘读取到内存中,搜索引擎的索引量都非常巨大,所以需要对索引进行压缩。索引主要包含两个部分:单词词典和对应的倒排列表,压缩也主要针对这两部分进行。
压缩算法指标(按重要性由高到低排列):解压速度、压缩率、压缩速度。
3.3.1 词典压缩
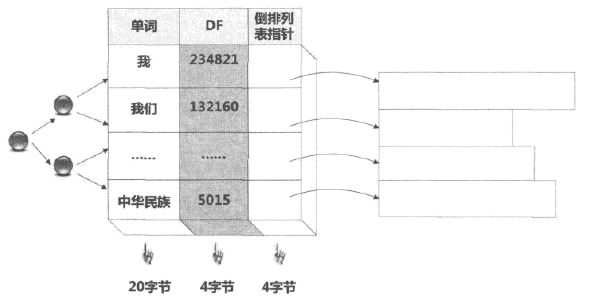
上图词典中DF和倒排列表指针都能用4个字节表示,但单词信息由于词长不同可能会造成存储空间浪费。
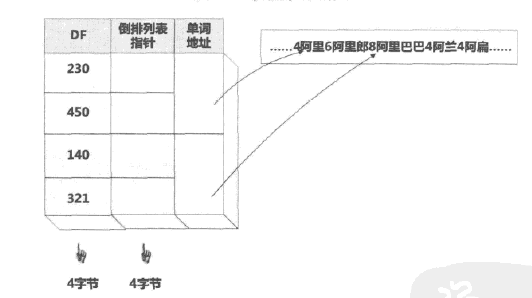
如上图的优化结构中,将连续词典分块,每个单词增加长度信息,多个单词共用指针信息。这样文档频率、倒排指针和单词地址都能固定大小。
3.3.2 文档编号重排
对文档ID重编号使得倒排列表中相邻两个文档的编号也尽可能相邻,使相邻文档的D-Gap值尽可能小,压缩算法效率会更高。具体算法不展开。
3.3.3 静态索引裁剪(static index pruning)
这是一种有损压缩,清除索引项中不重要的部分,同时尽可能保证搜索质量。常用的两种方法:以单词为中心的索引裁剪和以文档为中心的索引裁剪。
以单词为中心的索引裁剪需要计算单词与其对应的文档的相似性,据此判断是否保留索引项。索引建立好之后裁剪。
以文档为中心的裁剪计算单词的重要性,抛弃不重要的单词。建立索引之前裁剪。
至此,搜索引擎完成了网页数据的获取与存储,其余部分将在接下来的文章中介绍。
本文所有截图来自于《这就是搜索引擎:核心技术详解》,如有版权问题,我再重画 (-- 。 --) /