爬虫的不同抓取策略,就是利用不同的方法确定待抓取URL队列中URL优先顺序的。
爬虫的抓取策略有很多种,但不论方法如何,基本目标一致:优先选择重要网页进行抓取。
网页的重要性,评判标准不同,大部分采用网页的流行性进行定义。
效果较好或有代表性的抓取策略:
1、宽度优先遍历策略
2、非完全PageRank策略
3、OCIP策略
4、大站优先策略
1、宽度优先策略(Breath First)
基本思想:将新下载网页包含的链接直接追加到待抓取URL队列末尾。
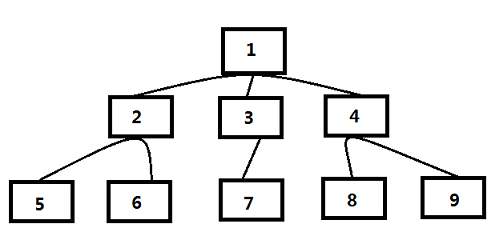
上图即为此策略示意图:
假设队头的网页是1号网页,从1号网页中抽取出3个链接指向2号、3号和4号网页,于是按照编号顺序依次放入待抓取URL队列,图中网页的编号就是在待抓取URL队列中的顺序编号,之后爬虫以此顺序进行下载。
实验表明,这种策略效果很好,虽然看似机械,但实际上的网页抓取顺序基本上是按照网页的重要性排序。之所以如此,有研究人员认为:如果某个网页包含很多入链,那么更有可能被宽度优先遍历策略早早抓到,入链个数从侧面体现了网页的重要性,即实际上宽度优先遍历策略隐含了一些网页优先级假设。
2、非完全PageRank策略(Partial PageRank)
基本思路:对于已经下载的网页,加上待抓取URL队列中的URL一起,形成网页集合,在此集合内进行PageRank计算,计算完成后,将待抓取URL队列里的网页按照PageRank得分由高到低排序,形成的序列就是爬虫接下来应该依次抓取的URL列表。
如果每次新抓取到一个网页,就进行重新计算新的非完全PageRank,明显效率太低。折中办法是网页攒够K个计算一次。 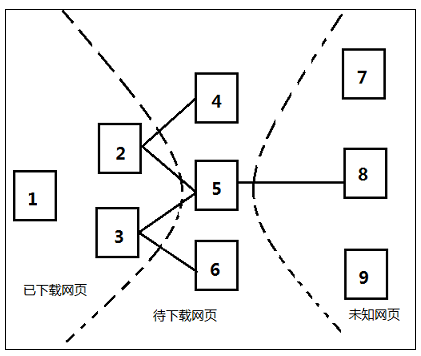
上图即为非完全PageRank策略示意图:
设定每下载3个网页进行新的PageRank计算,此时已经有{1,2,3}3个网页下载到本地。这三个网页包含的链接指向{4,5,6},即待抓取URL队列,如何决定下载顺序?
将这6个网页形成新的集合,对这个集合计算PageRank的值,这样4、5、6就获得自己对应的PageRank值,由大到小排序,即可得出下载顺序。假设顺序为5,4,6,当下载55页面后抽取出链接,指向页面8,此时赋予8临时PageRank值,如果这个值大于4和6的PageRank,则接下来优先下载页面8,如此不断循环,即形成了非完全PageRank策略的计算思路。
3、OCIP策略(Online Page Importance Computation)
OCIP字面意思即“在线页面重要性计算”,可以将其看做是一种改进的PageRank算法。
基本思路:
在算法开始之前,每个互联网页面都给予相同的“现金”,每当下载了某个页面P后,P就将自己拥有的现金平均分配给页面中包含的链接页面,把自己的“现金”清空。而对于待爬取URL队列中的网页,则根据其手头拥有的“现金”金额多少排序,优先下载“现金”最多的网页,OPIC从大的框架上与PageRank思路基本一致。
与PageRank的区别在于:PageRank每次需要迭代计算,而OPIC策略不需要迭代过程。所以计算速度远远快与PageRank,适合实时计算使用。同时,PageRank在计算时,存在向无链接关系网页的远程跳转过程,而OPIC没有这一计算因子。实验结果表明,OPIC是较好的重要性衡量策略,效果略优于宽度优化遍历策略。
4、大站优先策略(Larger Sites First)
大站优先策略思路:
以网站为单位来选题网页重要性,对于待爬取URL队列中的网页,根据所属网站归类,如果哪个网站等待下载的页面最多,则优先下载这些链接,其本质思想倾向于优先下载大型网站。因为大型网站往往包含更多的页面。鉴于大型网站往往是著名企业的内容,其网页质量一般较高,所以这个思路虽然简单,但是有一定依据。实验表明这个算法效果也要略优先于宽度优先遍历策略。
ref: 《这就是搜索引擎-核心技术详解》
form lesliefish