版权声明:本文为原创文章,转载请先联系并标明出处
我们之前做了一些性能测试的实例,也陆续发布到了社区中,这些实例主要讲解了性能测试相关的操作、技巧及一些方法论的东西,相信可以指导大家动手做性能测试了。可是,大家拿到第一份测试结果统计表的时候,是否会茫然?这些数据是从哪儿得来的?怎么统计的?如何解读这些数据?本文通过HyperPacer统计分析视图提供的测试结果综合统计表来进行讲解。
HyperPacer测试结果综合统计表如下(200用户并发,迭代2轮):
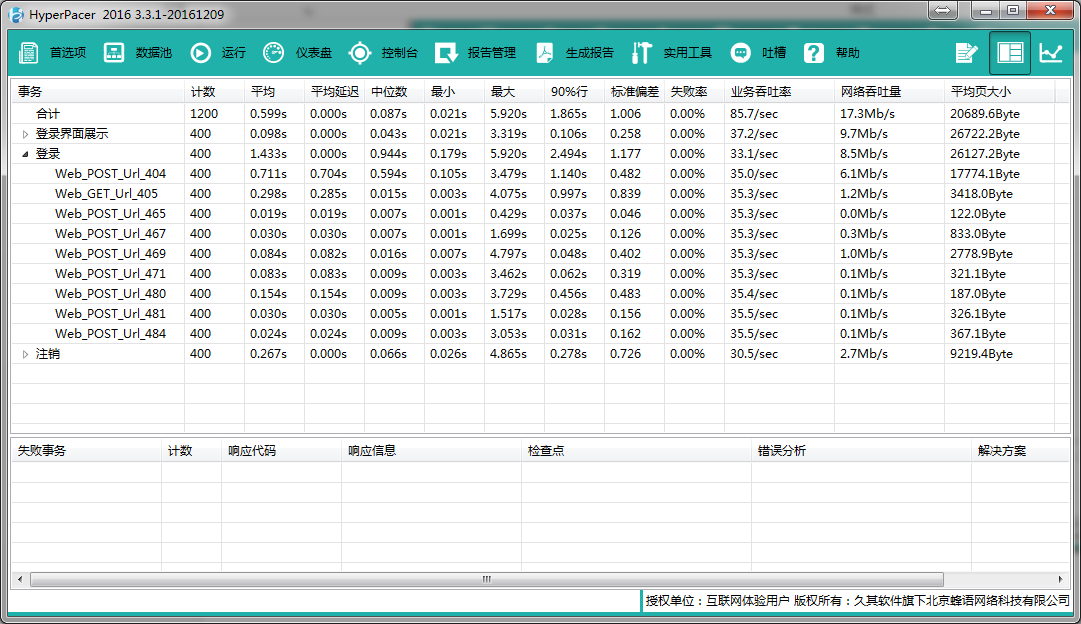
我们来简单解读一下这张表:行方向,是统计的各个信息项;栏方向,是性能测试脚本的树形结构,即事务-取样器树形,事务可以展开可以折叠。下方会统计失败的事务及其具体信息。
第一个问题,这些数据是从哪儿得来的?
Hyperpacer在脚本执行的时候,对每一个事务和子测试元件都记录了开始时间和结束时间,我们统计的时候是用这些数据做统计的。
第二个问题,数据是怎么统计的?
这个涉及到统计学上的一些方法,需要强调的一个问题是,事务的统计数据有两种计算方法,事务统计延迟时间的时候,是用事务的开始时间、结束时间来统计;事务不统计延迟时间的时候,使用事务下所有的子测试元件的数据求和再求平均。下面我们来看一下取数规则:
计数:取样器等测试元件被执行的次数。 平均:从发送请求到服务器响应完成的时间;所有样本数据求和后,再取平均值;验证性能是否符合预期的最主要依据。 平均延迟:发送请求到服务器开始响应的时间;所有样本数据求和后,再取平均值。 中位数:所有数据从小到大排列,取最中间的数据,如果样本数是偶数,则用中间两个数据求和再取平均数。 最小:所有数据从小到大排列,取最小的数据。 最大:所有数据从小到大排列,取最大的数据。 90%:所有数据从小到大排列,取第90%个数据,即:假如是100个样本,从小到大排列,取第90个数据。 标准偏差:标准差(Standard Deviation),在概率统计中最常使用作为统计分布程度(statistical dispersion)上的测量。标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的平方根。它反映组内个体间的离散程度。简单来说,标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。 失败率:测试元件失败的比率,计算方式为失败样本数/样本总数*100%。 业务吞吐率(TPS):应用系统每秒处理完成的请求数。它是衡量系统处理能力的重要指标。该值单独来看其实意义不大,对比着看更能反映系统性能差异。对于业务相似,复杂度也相似的的系统,业务吞吐率可以做对比,相同压力条件及测试场景下,业务吞吐率越大说明系统性能越高 网络吞吐量:指性能测试过程中网络上每秒传输的数据量。性能测试工具中的吞吐量只统计了服务器端返回的流量。 平均页大小:每一个响应页面的平均大小。
第三个问题,如何解读这些数据?
性能测试结果解读时,主要关注以下几个指标:平均响应时间、标准偏差、业务吞吐率(TPS)和事务失败率。
1、平均响应时间:
对于响应时间优先的系统,应该首先关注响应时间是否满足预期目标。因此,响应时间应该作为需要第一关注的监控指标。如果响应时间都不能够满足预期,则本次测试的结论应该是不能通过的。
平均响应时间:测试过程中该事务的所有监控到的响应时间的平均值,该指标常用来作为评估该测试事务点是否可满足预期的度量值;
2、标准偏差:
该值表示本次测试中该事务所有监控到的响应时间的分布情况,即离散程度,因此,该值常用来评估系统的稳定性。该值越小,表示响应时间分布越集中,即系统越稳定;反之,则表示响应时间离散度很大,如在测试后时段出现此现象,可认为从此时开始,系统运行开始出现不稳定的情况;如果整个测试时间段都有此问题可视为本次测试中响应时间异常数值太多,测试是无效的。
3、业务吞吐率(TPS)
有些系统对响应时间并不特别敏感,而对于系统的事务吞吐量则比较敏感。如报名系统、信息收集系统以及一些交易系统,本身并不要求响应时间必须多快,但是对于单位时间内能够处理的事务数、系统可以支持的最大交易量则比较关注,则此时就需要重点关注TPS指标了。
TPS,反映了系统在同一时间内能处理事务的最大能力,这个数据越高,说明系统处理能力越强。TPS通常会跟响应时间、并发用户数互相结合考虑,来确认当前压力下是否出现拐点,如出现拐点,表示拐点处即为当前系统能够处理事务的最大能力,当前的负载即为系统的最大可支撑值。
4、事务失败率
测试过程中,查看事务是否全部通过,如果有事务失败,就需要分析是否脚本设计的时候对于并发的处理未考虑充分导致部分事务失败,或者并发用户较大时系统出现了瓶颈。
同时,事务失败率本身也作为本次测试是否有效的考量指标,如果失败率高于20%,通常我们认为本次测试的测试结果是不能代表正常情况下系统的运行情况的。对于不同的系统,该限定值也是可以不同的。若是需要很高稳定性的系统,限定值就会是0.1%(即1000次交易只允许1次交易失败)甚至更低,该值可以根据实际需要定义。