数据清洗
是整个数据分析过程中不可缺少的一个环节,其结果质量直接关系到模型效果和最终结论。在实际操作中,数据清洗通常会占据分析过程的50%—80%的时间。
预处理阶段
一是将数据导入处理工具。通常来说,建议使用数据库,单机跑数搭建MySQL环境即可
二是看数据。这里包含两个部分:一是看元数据,包括字段解释、数据来源、代码表等等一切描述数据的信息;二是抽取一部分数据,使用人工查看方式,对数据本身有一个直观的了解,并且初步发现一些问题,为之后的处理做准备。
第一步:缺失值清洗
缺失值是最常见的数据问题,处理缺失值也有很多方法,我建议按照以下四个步骤进行:
1、确定缺失值范围:对每个字段都计算其缺失值比例,然后按照缺失比例和字段重要性,分别制定策略
2、去除不需要的字段:这一步很简单,直接删掉即可……但强烈建议清洗每做一步都备份一下,或者在小规模数据上试验成功再处理全量数据,不然删错了会追悔莫及(多说一句,写SQL的时候delete一定要配where!)。
3、填充缺失内容:某些缺失值可以进行填充,方法有以下三种:
以业务知识或经验推测填充缺失值
以同一指标的计算结果(均值、中位数、众数等)填充缺失值
以不同指标的计算结果填充缺失值
前两种方法比较好理解。关于第三种方法,举个最简单的例子:年龄字段缺失,但是有屏蔽后六位的身份证号,so……
4、重新取数:如果某些指标非常重要又缺失率高,那就需要和取数人员或业务人员了解,是否有其他渠道可以取到相关数据。
第二步:格式内容清洗
如果数据是由系统日志而来,那么通常在格式和内容方面,会与元数据的描述一致。而如果数据是由人工收集或用户填写而来,则有很大可能性在格式和内容上存在一些问题,简单来说,格式内容问题有以下几类:
1、时间、日期、数值、全半角等显示格式不一致
这种问题通常与输入端有关,在整合多来源数据时也有可能遇到,将其处理成一致的某种格式即可。
2、内容中有不该存在的字符
某些内容可能只包括一部分字符,比如身份证号是数字+字母,中国人姓名是汉字(赵C这种情况还是少数)。最典型的就是头、尾、中间的空格,也可能出现姓名中存在数字符号、身份证号中出现汉字等问题。这种情况下,需要以半自动校验半人工方式来找出可能存在的问题,并去除不需要的字符。
3、内容与该字段应有内容不符
姓名写了性别,身份证号写了手机号等等,均属这种问题。 但该问题特殊性在于:并不能简单的以删除来处理,因为成因有可能是人工填写错误,也有可能是前端没有校验,还有可能是导入数据时部分或全部存在列没有对齐的问题,因此要详细识别问题类型。
格式内容问题是比较细节的问题,但很多分析失误都是栽在这个坑上,比如跨表关联或VLOOKUP失败(多个空格导致工具认为“陈丹奕”和“陈 丹奕”不是一个人)、统计值不全(数字里掺个字母当然求和时结果有问题)
第三步:逻辑错误清洗
这部分的工作是去掉一些使用简单逻辑推理就可以直接发现问题的数据,防止分析结果走偏。主要包含以下几个步骤:
1、去重
建议把去重放在格式内容清洗之后,如果数据不是人工录入的,那么简单去重即可。
2、去除不合理值
一句话就能说清楚:有人填表时候瞎填,年龄200岁,年收入100000万(估计是没看见”万“字),这种的就要么删掉,要么按缺失值处理
3、修正矛盾内容
有些字段是可以互相验证的,举例:身份证号是1101031980XXXXXXXX,然后年龄填18岁。在这种时候,需要根据字段的数据来源,来判定哪个字段提供的信息更为可靠,去除或重构不可靠的字段。
我们能做的是使用工具和方法,尽量减少问题出现的可能性,使分析过程更为高效。
第四步:非需求数据清洗
这一步说起来非常简单:把不要的字段删了。
建议:如果数据量没有大到不删字段就没办法处理的程度,那么能不删的字段尽量不删。其次,请勤备份数据
第五步:关联性验证
如果你的数据有多个来源,那么有必要进行关联性验证。比如,线上/线下收集的数据不一致
大数据基础面试
1.hdfs上传文件的流程。
答:这里描述的 是一个256M的文件上传过程
① 由客户端 向 NameNode节点节点 发出请求
②NameNode 向Client返回可以可以存数据的 DataNode 这里遵循机架感应原则
③客户端 首先 根据返回的信息 先将 文件分块(Hadoop2.X版本 每一个block为 128M 而之前的版本为 64M
④然后通过那么Node返回的DataNode信息 直接发送给DataNode 并且是 流式写入 同时 会复制到其他两台机器
⑤dataNode 向 Client通信 表示已经传完 数据块 同时向NameNode报告 ⑥依照上面(④到⑤)的原理将 所有的数据块都上传结束 向 NameNode 报告 表明 已经传完所有的数据块 。
2.讲述一下mapreduce的流程(shuffle的sort,partitions,group)
首先是 Mapreduce经过SplitInput 输入分片 决定map的个数在用Record记录 key value。然后分为以下三个流程:
Map:
输入 key(long类型偏移量) value(Text一行字符串)
输出 key value
Shuffle:、
合并(merge)map输出时先输出到环形内存,当内存使用率达到60%时开始溢出写入到文件,溢出文件都是小文件,所以就要合并他们,在这个构成中就会排序,根据key值比较排序
排序(sort)如果你自定义了key的数据类型要求你的类一定是WriteableCompartor的子类,不想继承WriteableCompartor,至少实现Writeable,这时你就必须在job上设置排序比较器job.setSortCmpartorClass(MyCompartor.class);
而MyCompartor.class必须继承RawCompartor的类或子类
分区(partition)会根据map输出的结果分成几个文件为reduce准备,有几个reducetask就分成几个文件,在job上设置分区器job.setPartitionerClass(MyPartition.class)Myrtition.class要继承Partitioner这个类
分组(group)分区时会调用分组器,把同一分区中的相同key的数据对应的value制作成一个iterable,并且会在sort。在job上设置分组器。Job.setGroupCompartorClass(MyGroup.class)MyGroup.class必须继承RawCompartor的类跟子类
上面的结果储存到本地文件中,而不是hdfs上
上面只要有完成结果,reduce就开始复制上面的结果,通过http方式
Reduce
输入key时map输出时的key value是分组器分的iterable
输出 key value
输出结果保存在hdfs上而不是本地文件中
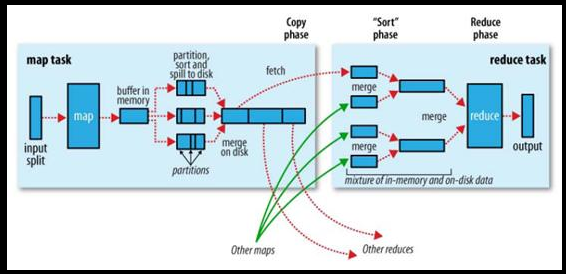
https://www.cnblogs.com/gwgyk/p/3997849.html
3.了解zookeeper吗?介绍一下它,它的选举机制和集群的搭建。
ZooKeeper 是一个开源的分布式协调服务,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁
和分布式队列等功能。我们公司使用的flume集群,Kafka集群等等,都离不开ZooKeeper。每个节点上我们都要搭建ZooKeeper服务。首先我们要在每台pc上配置zookeeper环境变量,
在cd到zookeeper下的conf文件夹下在zoo_simjle.cfg文件中添加datadir路径,再到zookeeper下新建data文件夹,创建myid,在文件里添加上server的ip地址。在启动zkserver.sh start便ok了。
4.mysql,rides的端口。
mysql:3306,rides:6379。
5.yarn的理解:
YARN是Hadoop2.0版本引进的资源管理系统,直接从MR1演化而来。
核心思想:将MR1中的JobTracker的资源管理和作业调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现。
ResourceManager:负责整个集群的资源管理和调度 ApplicationMaster:负责应用程序相关事务,比如任务调度、任务监控和容错等。
YARN的出现,使得多个计算框架可以运行在同一个集群之中。 1. 每一个应用程序对应一个ApplicationMaster。 2. 目前可以支持多种计算框架运行在YARN上面,比如MapReduce、storm、Spark、Flink。
MapReduce1.0本身存在着一些问题:
1)JobTracker单点故障问题;如果Hadoop集群的JobTracker挂掉,则整个分布式集群都不能使用了。
2)JobTracker承受的访问压力大,影响系统的扩展性。
3)不支持MapReduce之外的计算框架,比如Storm、Spark、Flink等。
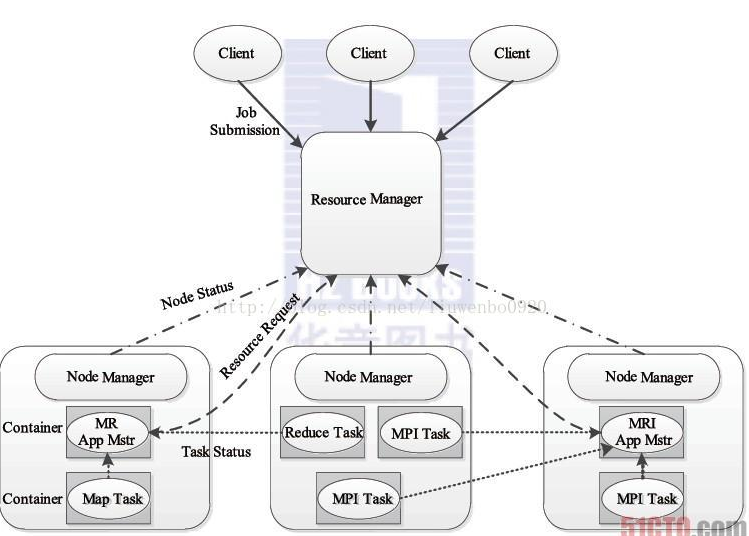
步骤1 用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
步骤2 ResourceManager为该应用程序分配第一个Container,并与对应的Node-Manager通信,要求它在这个Container中启动应用程序的ApplicationMaster。
步骤3 ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
步骤4 ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
步骤5 一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
步骤6 NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
步骤7 各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的运行状态。
步骤8 应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
6.数据来源的方式:
1.webServer :用户访问我们的网站,对日志进行收集,记录在反向的日志文件里 tomcat下logs
2js代码嵌入前端页面(埋点):js的sdk会获取用户行为,document会得到元素调用function,通过ngix集群进行日志收集。
7.MapReduce工作流程
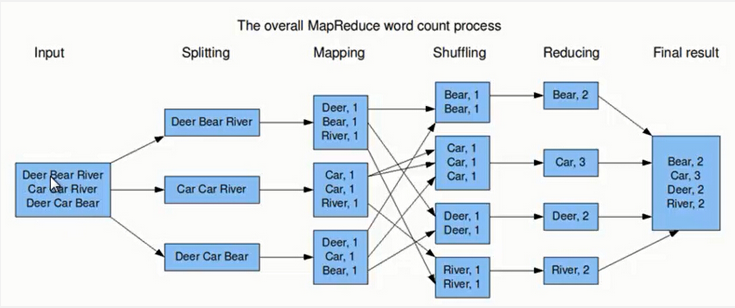
上图的流程大概分为以下几步。
第一步:假设一个文件有三行英文单词作为 MapReduce 的Input(输入),这里经过 Splitting 过程把文件分割为3块。分割后的3块数据就可以并行处理,每一块交给一个 map 线程处理。
第二步:每个 map 线程中,以每个单词为key,以1作为词频数value,然后输出。
第三步:每个 map 的输出要经过 shuffling(混洗),将相同的单词key放在一个桶里面,然后交给 reduce 处理。
第四步:reduce 接受到 shuffling 后的数据, 会将相同的单词进行合并,得到每个单词的词频数,最后将统计好的每个单词的词频数作为输出结果。
hadoop的核心思想是MapReduce,但shuffle又是MapReduce的核心。shuffle的主要工作是从Map结束到Reduce开始之间的过程

8.MR程序运行的时候会有什么比较常见的问题?
比如说作业中大部分都完成了,但是总有几个reduce一直在运行。
这是因为这几个reduce中的处理的数据要远远大于其他的reduce,可能是对键值对任务划分的不均匀造成的数据倾斜。
解决的方法可以在分区的时候重新定义分区规则对于value数据很多的key可以进行拆分、均匀打散等处理,或者是在map端的combiner中进行数据预处理的操作。
解决数据倾斜问题
常用优化手段
设置合理的map reduce的task数,能有效提升性能。
适当减少Map数:当一个任务有很多小文件(远远小于块大小128m),会产生很多Map,而一个Map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费,而且同时可执行的map数是受限的。
适当增加Map数:当有一个小于128M的文件(其中有上千万的数据,字段少并且数据单位小),如果map处理的逻辑比较复杂,用一个map任务去做,耗时比较大。
Map端聚合:set hive.map.aggr=true ;(默认为true) 对小文件进行合并,是行至有效的提高调度效率的方法。
合并小文件 文件数目过多,会给 HDFS 带来压力,并且会影响处理效率,可以通过合并 Map 和 Reduce 的结果文件来消除这样的影响
数据量较大的情况下,慎用count(distinct)。
数据类型方面的优化
按照一定规则分区(例如根据日期)。通过分区,查询的时候指定分区,会大大减少在无用数据上的扫描, 同时也非常方便数据清理。
JOIN 原则
在使用写有 Join 操作的查询语句时有一条原则:应该将条目少的表/子查询放在 Join 操作符的左边
原因是在 Join 操作的 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生 OOM (内存溢出)错误的几率
join和count(distinct) 数据量大时容易出现倾斜问题
join
1. 空值数据倾斜 join的key值发生倾斜,key值包含很多空值或是异常值,这种情况可以对异常值赋一个随机值来分散key。
select * from log l
left outer join user u on
case when (l.user_id is null or I.user_id='-' or I.user_id='0')
then concat(‘sql_hive’,rand() ) else l.user_id end = u.user_id;
大表和小表Join
解决方式:业务削减。
count(distinct)
count distinct 聚 合 时 存 在 大 量 特 殊 值
产生原因: 做count distinct时,该字段存在大量值为NULL或空的记录。
解决方式: 做count distinct时,将值为空的情况单独处理
select cast(count(distinct user_id)+1 as bigint) as user_cnt
from user
where user_id is not null and user_id <> '';
在Hive中,经常遇到count(distinct)操作,这样会导致最终只有一个reduce,我们可以先group 再在外面包一层count,就可以了。
select count(id)from (select id from bigtable groupby id) a;
group by 产生倾斜的问题 set hive.map.aggr=true Map端进行聚合,默认为True
9.hive中存放的是什么?
表。
存的是和hdfs的映射关系,hive是逻辑上的数据仓库,实际操作的都是hdfs上的文件,HQL就是用SQL语法来写的MR程序。
hive是数据仓库,不能和数据库一样进行实时的CRUD操作。是一次写入多次读取的操作,可以看成是ETL的工具。
10.Flume的工作机制是什么?
核心概念是agent,里面包括source,channel和sink三个组件。
Source运行在日志收集节点进行日志采集,之后临时存储在channel中,sink负责将channel中的数据发送到目的地。
只有发送成功channel中的数据才会被删除。
首先书写flume配置文件,定义agent、source、channel和sink然后将其组装,执行flume-ng命令。
11.请列出正常的hadoop集群中hadoop都分别需要启动 哪些进程,他们的作用分别都是什么。
namenode:负责管理hdfs中文件块的元数据,响应客户端请求,管理datanode上文件block的均衡,维持副本数量
Secondname:主要负责做checkpoint操作;也可以做冷备,对一定范围内数据做快照性备份。
Datanode:存储数据块,负责客户端对数据块的io请求
Jobtracker :管理任务,并将任务分配给 tasktracker。
Tasktracker: 执行JobTracker分配的任务。
Resourcemanager、Nodemanager、Journalnode、Zookeeper、Zkfc
12.请说明hive中Sort By、Order By、Cluster By,Distribute By各代表什么意思?
order by:会对输入做全局排序,因此只有一个reducer(多个reducer无法保证全局有序)。只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
sort by:不是全局排序,其在数据进入reducer前完成排序。
distribute by:按照指定的字段对数据进行划分输出到不同的reduce中。
cluster by:除了具有 distribute by 的功能外还兼具 sort by 的功能。
13.hive表关联查询,如何解决数据倾斜的问题?
倾斜原因:
map输出数据按key Hash的分配到reduce中,由于key分布不均匀、业务数据本身的特点、建表时考虑不周、等原因造成的reduce 上的数据量差异过大。
1)、key分布不均匀;
2)、业务数据本身的特性;
3)、建表时考虑不周;
4)、某些SQL语句本身就有数据倾斜;
如何避免:对于key为空产生的数据倾斜,可以对其赋予一个随机值。
解决方案
1>.参数调节:
hive.map.aggr = true
hive.groupby.skewindata=true
有数据倾斜的时候进行负载均衡,当选项设定位true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个Reduce中),最后完成最终的聚合操作。
2>.SQL 语句调节:
1)、选用join key分布最均匀的表作为驱动表。做好列裁剪和filter操作,以达到两表做join 的时候,数据量相对变小的效果。
2)、大小表Join:
使用map join让小的维度表(1000 条以下的记录条数)先进内存。在map端完成reduce.
4)、大表Join大表:
把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null 值关联不上,处理后并不影响最终结果。
5)、count distinct大量相同特殊值:
count distinct 时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
使用索引:
hive.optimize.index.filter:自动使用索引
hive.optimize.index.groupby:使用聚合索引优化GROUP BY操作
14.hive内部表和外部表的区别
内部表:加载数据到hive所在的hdfs目录,删除时,元数据和数据文件都删除
外部表:不加载数据到hive所在的hdfs目录,删除时,只删除表结构。
15.hive的计算是通过什么实现的
hive是搭建在Hadoop集群上的一个SQL引擎,它将SQL语句转化成了MapReduce程序在Hadoop上运行,所以hive的计算引擎是MapReduce,而hive的底层存储采用的是HDFS,hive的底层实现是MapReduce,yarn可以作为MapReduce计算框架的资源调度系统
16.简单概括安装hadoop的步骤
1.创建 hadoop 帐户。
2.setup.改 IP。
3.安装 java,并修改/etc/profile 文件,配置 java 的环境变量。
4.修改 Host 文件域名。
5.安装 SSH,配置无密钥通信。
6.解压 hadoop。
7.配置 conf 文件下 hadoop-env.sh、core-site.sh、mapre-site.sh、hdfs-site.sh。
8.配置 hadoop 的环境变量。
9.Hadoop namenode -format
10.Start-all.sh
17.三个 datanode,当有一个 datanode 出现错误会怎样?
第一不会给储存带来影响,因为有其他的副本保存着,不过建议尽快修复,第二会影响运算的效率,机器少了,reduce在保存数据时选择就少了,一个数据的块就大了所以就会慢。
18.hive保存元数据的方式以及各有什么特点?
1、Hive有内存数据库derby数据库,特点是保存数据小,不稳定
2、mysql数据库,储存方式可以自己设定,持久化好,一般企业开发都用mysql做支撑
19.Hive中追加导入数据的4种方式是什么?请写出简要语法
从本地导入: load data local inpath ‘/home/1.txt’ (overwrite)into table student;
从Hdfs导入: load data inpath ‘/user/hive/warehouse/1.txt’ (overwrite)into table student;
查询导入: create table student1 as select * from student;(也可以具体查询某项数据)
查询结果导入:insert (overwrite)into table staff select * from track_log;
20.分区和分桶的区别
分区
是指按照数据表的某列或某些列分为多个区,区从形式上可以理解为文件夹,比如我们要收集某个大型网站的日志数据,一个网站每天的日志数据存在同一张表上,由于每天会生成大量的日志,导致数据表的内容巨大,在查询时进行全表扫描耗费的资源非常多。
那其实这个情况下,我们可以按照日期对数据表进行分区,不同日期的数据存放在不同的分区,在查询时只要指定分区字段的值就可以直接从该分区查找
分桶
分桶是相对分区进行更细粒度的划分。
分桶将整个数据内容安装某列属性值得hash值进行区分,如要按照name属性分为3个桶,就是对name属性值的hash值对3取摸,按照取模结果对数据分桶。
如取模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件
21.Hive优化
通用设置
hive.optimize.cp=true:列裁剪
hive.optimize.prunner:分区裁剪
hive.limit.optimize.enable=true:优化LIMIT n语句
hive.limit.row.max.size=1000000:
hive.limit.optimize.limit.file=10:最大文件数
并发执行
hive.exec.parallel=true ,默认为false
hive.exec.parallel.thread.number=8
多个group by合并
hive.multigroupby.singlemar=true:当多个GROUP BY语句有相同的分组列,则会优化为一个MR任务
Hive是基于hadoop的数据仓库工具,可以将结构化的数据文件映射成一张数据表,并且提供sql查询。相当于mapreduce的客户端,可以将sql语句转换为MapReduce任务进行运行。
其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
22.数据发散(找到多条记录)
通过查询表的关联字段,group by 关联字段 having count(关联字段)>1,进行统计,就可以判定是否有一对多的发散情况。
收敛就是:如果你用group by 关联字段 进行统计,然后统计金额的话,就会group by 字段相同的情况下多条记录的金额就会加在一起,合成一条记录
23.Hadoop的调度机制
1.先入先出FIFO
Hadoop 中默认的调度器,它先按照作业的优先级高低,再按照到达时间的先后选择被执行的作业。
2.公平调度器(相当于时间片轮转调度)
为任务分配资源的方法,其目的是随着时间的推移,让提交的作业获取等量的集群共享资源,让用户公平地共享集群。具体做法是:当集群上只有一个任务在运行时,它将使用整个集群,当有其他作业提交时,
系统会将TaskTracker节点空间的时间片分配给这些新的作业,并保证每个任务都得到大概等量的CPU时间。
配置公平调度器
3.容量调度器
支持多个队列,每个队列可配置一定的资源量,每个队列采用 FIFO 调度策略,为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。调度时,首先按以下策略选择一个合适队列:
计算每个队列中正在运行的任务数与其应该分得的计算资源之间的比值,选择一个该比值最小的队列;然后按以下策略选择该队列中一个作业:按照作业优先级和提交时间顺序选择 ,同时考虑用户资源量限制和内存限制。但是不可剥夺式。
24.Hadoop的二次排序
第一种方法是,Reducer将给定key的所有值都缓存起来,然后对它们再做一个Reducer内排序。但是,由于Reducer需要保存给定key的所有值,可能会导致出现内存耗尽的错误。
第二种方法是,将值的一部分或整个值加入原始key,生成一个组合key。这两种方法各有优势,第一种方法编写简单,但并发度小,数据量大的情况下速度慢(有内存耗尽的危险),
第二种则是将排序的任务交给MapReduce框架shuffle,更符合Hadoop/Reduce的设计思想。我们将编写一个Partitioner,确保拥有相同key(原始key,不包括添加的部分)的所有数据被发往同一个Reducer,
还将编写一个Comparator,以便数据到达Reducer后即按原始key分组。
25.所有的hive任务都会有reducer的执行吗?
答:不是,由于当前hive的优化,使得一般简单的任务不会去用reducer任务;只有稍微复杂的任务才会有reducer任务
举例:使用select * from person ; 就不会有reducer
26.列举你知道的常用的hadoop管理和监控的命令
-ls -cat -text -cp -put -chmod -chown
-du -get -copyFromLocal -copyToLocal
-mv -rm - tail -chgrp
27. 在mr环节中,那些环节需要优化,如何优化,请详细说明。
1、 setNumReduceTasks 适当的设置reduce的数量,如果数据量比较大,那么可以增加reduce的数量
2、适当的时候使用 combine 函数,减少网络传输数据量
3、压缩map和reduce的输出数据
4、使用SequenceFile二进制文件。
5、通过application 的ui页面观察job的运行参数
6、太多小文件,造成map任务过多的问题,应该可以先合并小文件,或者有一个特定的map作为处理小文件的输入
28.HDFS存储大量的小文件会有什么问题,如何解决?
(1)HDFS不适合大量小文件的存储,因namenode将文件系统的元数据存放在内存中,因此存储的文件数目受限于 namenode的内存大小。HDFS中每个文件、目录、数据块占用150Bytes。如果存放的文件数目过多的话会占用很大的内存
(2)HDFS适用于高吞吐量,而不适合低时间延迟的访问。如果同时存入大量的小文件会花费很长的时间
(3) 流式读取的方式,不适合多用户写入,以及任意位置写入。如果访问小文件,则必须从一个datanode跳转到另外一个datanode,这样大大降低了读取性能。
29.Hadoop的压缩算法
Hadoop 对于压缩格式的是自动识别。如果我们压缩的文件有相应压缩格式的扩展名(比如 lzo,gz,bzip2 等)。
Hadoop 会根据压缩格式的扩展名自动选择相对应的解码器来解压数据,此过程完全是 Hadoop 自动处理,我们只需要确保输入的压缩文件有扩展名。
Hadoop 对每个压缩格式的支持, 详细见下表:
压缩格式 工具 算法 扩展名 多文件 可分割性
DEFLATE 无 DEFLATE .deflate 不 不
GZIP gzip DEFLATE .gzp 不 不
ZIP zip DEFLATE .zip 是 是,在文件范围内
BZIP2 bzip2 BZIP2 .bz2 不 是
LZO lzop LZO .lzo 不 是
如果压缩的文件没有扩展名,则需要在执行 MapReduce 任务的时候指定输入格式。
Bzip2 压缩效果明显是最好的,但是 bzip2 压缩速度慢,可分割。
Gzip 压缩效果不如 Bzip2,但是压缩解压速度快,不支持分割。
LZO 压缩效果不如 Bzip2 和 Gzip,但是压缩解压速度最快!并且支持分割!
30..Hive UDF编写错误从哪方面调错?
首先查日志,UDF的日志是保存在Hadoop MR的日志文件中,
其次通过错误提示通过管道符grep |查找问题所在,并针对问题进行改进,在日志文件过大的情况下,可以通过head tail sed 等指令进行分段查找
31.请简述mapreduce中的combine和partition的作用
答:combiner是发生在map的最后一个阶段,其原理也是一个小型的reducer,主要作用是减少输出到reduce的数据量,缓解网络传输瓶颈,提高reducer的执行效率。
partition的主要作用将map阶段产生的所有kv对分配给不同的reducer task处理,可以将reduce阶段的处理负载进行分摊
32.hbase内部机制是什么
Hbase是一个能适应联机业务的数据库系统
物理存储:hbase的持久化数据是存放在hdfs上
存储管理:一个表是划分为很多region的,这些region分布式地存放在很多regionserver上
33.hive底层与数据库交互原理
Hive的查询功能是由hdfs + mapreduce结合起来实现的,Hive与mysql的关系:只是借用mysql来存储hive中的表的元数据信息,称为metastore
34.datanode在什么情况下不会备份数据
答:在客户端上传文件时指定文件副本数量为1
35.sqoop在导入数据到mysql中,如何不重复导入数据,如果存在数据问题,sqoop如何处理?
答:FAILED java.util.NoSuchElementException
此错误的原因为sqoop解析文件的字段与MySql数据库的表的字段对应不上造成的。因此需要在执行的时候给sqoop增加参数,告诉sqoop文件的分隔符,使它能够正确的解析文件字段。
hive默认的字段分隔符为’�01’
36.请列举出曾经修改过的/etc/下面的文件,并说明修改要解决什么问题?
答:/etc/profile这个文件,主要是用来配置环境变量。让hadoop命令可以在任意目录下面执行。
/ect/sudoers
/etc/hosts
/etc/sysconfig/network
/etc/inittab
37.假设公司要建一个数据中心,你会如何处理?
先进行需求调查分析
设计功能划分
架构设计
吞吐量的估算
采用的技术类型
软硬件选型
成本效益的分析
项目管理
扩展性
安全性,稳定性
38.hadoop单机模式、伪分布模式、集群模式的区别是什么?
单机模式:-默认情况下,Hadoop即处于该模式,用于开发和调式。
-不对配置文件进行修改。
-使用本地文件系统,而不是分布式文件系统。
-Hadoop不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程,Map()和Reduce()任务作为同一个进程的不同部分来执行的。
伪分布模式
在一台主机模拟多主机。
-Hadoop启动NameNode、DataNode、JobTracker、TaskTracker这些守护进程都在同一台机器上运行,是相互独立的Java进程。
-在这种模式下,Hadoop使用的是分布式文件系统,各个作业也是由JobTraker服务,来管理的独立进程。在单机模式之上增加了代码调试功能,允许检查内存使用情况,HDFS输入输出,
集群模式
-Hadoop的守护进程运行在一个集群上 -Hadoop的守护进程运行在由多台主机搭建的集群上,是真正的生产环境。
-在所有的主机上安装JDK和Hadoop,组成相互连通的网络。
39.什么是mapReduce?
1)MapReduce是面向大数据并行程序设计的模型和方法
2)MapReduce也是一个并行计算软件框架
40.partitioner 作用
对Mapper产生的中间结果进行分片,以便将同一个分组的数据交给同一个Reducer处理,它直接影响Reducer阶段的复杂均衡。
Partitioner只提供了一个方法:getPartition(Text key,Text value,int numPartitions),前两个参数是Map的Key和Value,numPartitions为Reduce的个数。
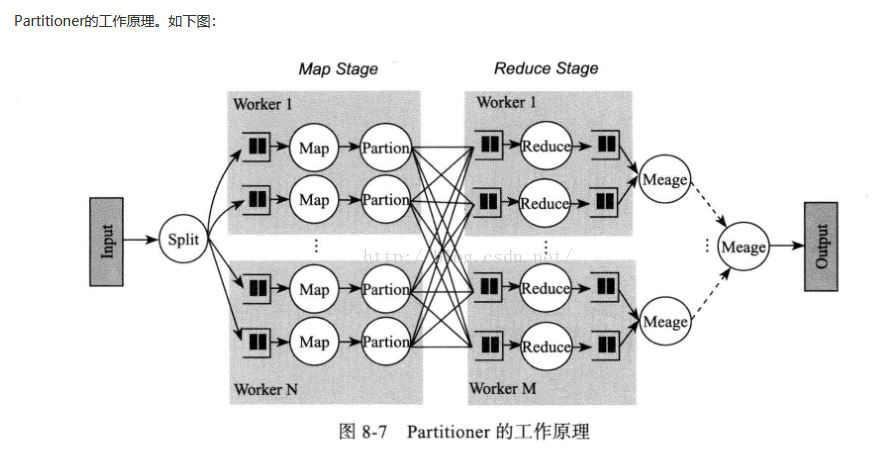
41.combiner 作用
MapReduce中的Combiner就是为了避免map任务和reduce任务之间的数据传输而设置的,Hadoop允许用户针对map task的输出指定一个合并函数。即为了减少传输到Reduce中的数据量。它主要是为了削减Mapper的输出从而减少网络带宽和Reducer之上的负载。
reduce的输入每个key所对应的value将是一大串1,但处理的文本很多时,这一串1已将占用很大的带宽,如果我们在map的输出给于reduce之前做一下合并或计算,那么传给reduce的数据就会少很多,减轻了网络压力。此时Combiner就排上用场了。我们现在本地把Map的输出做一个合并计算,把具有相同key的1做一个计算,然后再把此输出作为reduce的输入,这样传给reduce的数据就少了很多。Combiner是用reducer来定义的,多数的情况下Combiner和reduce处理的是同一种逻辑,所以job.setCombinerClass()的参数可以直接使用定义的reduce.
42.如何决定一个job中需要多少个maptask和reducetask?
一、影响map个数,即split个数的因素主要有:
1)HDFS块的大小,即HDFS中dfs.block.size的值。如果有一个输入文件为1024m,当块为256m时,会被划分为4个split;当块为128m时,会被划分为8个split。
2)文件的大小。当块为128m时,如果输入文件为128m,会被划分为1个split;当块为256m,会被划分为2个split。
3)文件的个数。FileInputFormat按照文件分割split,并且只会分割大文件,即那些大小超过HDFS块的大小的文件。如果HDFS中dfs.block.size设置为64m,而输入的目录中文件有100个,则划分后的split个数至少为100个。
4)splitsize的大小。分片是按照splitszie的大小进行分割的,一个split的大小在没有设置的情况下,默认等于hdfs block的大小
二、reduce端的个数取决于用户的需求,默认是有一个reduce,可以在代码中声明reduce的输出个数
43.hdfs的优点与缺点
HDFS的优点:
1)数据冗余、硬件容错
文件以block的方式,多副本存储在集群的节点上,保证硬件的容错,当某一机器损坏时,不至于数据丢失
2)处理流式的数据访问
流式:一次写入,多次读取的操作
3)适合存储大文件
4)可构建在廉价的机器上
缺点:
1)低延迟的数据访问
数据大,想在秒级别做数据的检索不现实
2)小文件索引
不管数据在1M还是127M,都应该对应元数据存放在NameNode上,如果小文件很多,也就意味着所占用的内存信息也越大,那么对于hdfs的NameNode的压力也就越大
44.Hive的动态分区和静态分区有什么区别?
一、静态分区
1、创建分区表
1 hive (default)> create table order_mulit_partition(
2 > order_number string,
3 > event_time string
4 > )
5 > PARTITIONED BY(event_month string, step string)
6 > row format delimited fields terminated by ' ';
2、加载数据到分区表
1 load data local inpath '/opt/data/order_created.txt' overwrite into table order_mulit_partition PARTITION(event_month='201405', step='1');
order_created.txt内容如下
1 order_number event_time
2 10703007267488 2014-05-01 06:01:12.334+01
3 10101043505096 2014-05-01 07:28:12.342+01
4 10103043509747 2014-05-01 07:50:12.33+01
5 10103043501575 2014-05-01 09:27:12.33+01
6 10104043514061 2014-05-01 09:03:12.324+01
3、这种手动指定分区加载数据,就是常说的静态分区的使用。但是在日常工作中用的比较多的是动态分区。
二、动态分区
需求:按照不同部门作为分区导数据到目标表
以上需求如果用静态分区的话,数据量大你是不是很懵逼??所以这个需求一般采用动态分区来实现。
1、创建目标表

1 hive (default)> create table emp_dynamic_partition(
2 > empno int,
3 > ename string,
4 > job string,
5 > mgr int,
6 > hiredate string,
7 > sal double,
8 > comm double)
9 > PARTITIONED BY(deptno int)
10 > row format delimited fields terminated by ' ';
2、采用动态方式加载数据到目标表
加载之前先设置一下下面的参数
1 hive (default)> set hive.exec.dynamic.partition.mode=nonstrict
开始加载
1 insert into table emp_dynamic_partition partition(deptno)
2 select empno , ename , job , mgr , hiredate , sal , comm, deptno from emp;
上面加载数据方式并没有指定具体的分区,只是指出了分区字段。在select最后一个字段必须跟你的分区字段,这样就会自行根据deptno的value来分区。
3、验证一下
有值
1 hive (default)> select * from emp_dynamic_partition;
2 OK
3 emp_dynamic_partition.empno emp_dynamic_partition.ename emp_dynamic_partition.job emp_dynamic_partition.mgr emp_dynamic_partition.hiredate emp_dynamic_partition.sal emp_dynamic_partition.comm emp_dynamic_partition.deptno
4 7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
5 7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
6 7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
7 7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
8 7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
9 7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
10 7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
11 7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
12 7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
13 7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
14 7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
15 7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
16 7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
17 7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
18 8888 HIVE PROGRAM 7839 1988-1-23 10300.0 NULL NULL
有分区(自动分区)
1 hive (default)> show partitions emp_dynamic_partition;
2 OK
3 partition
4 deptno=10
5 deptno=20
6 deptno=30
7 deptno=__HIVE_DEFAULT_PARTITION__
8 Time taken: 0.29 seconds, Fetched: 4 row(s)
4、emp表的具体你内容如下
1 hive (default)> select * from emp;
2 OK
3 emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
4 7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
5 7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
6 7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7 7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
8 7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
9 7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
10 7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
11 7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
12 7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
13 7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
14 7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
15 7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
16 7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
17 7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
18 8888 HIVE PROGRAM 7839 1988-1-23 10300.0 NULL NULL
45.通常情况下集群模式的瓶颈在哪?
首先,瓶颈一般是指在整体中的关键限制因素,磁盘IO是指数据往磁盘读写,现在的科技速度最快的属固态硬盘了,读的速度很大有1G/秒左右,但是写入速度最快几百兆/秒,集群中数据在cpu和内存之间速度快的可以忽略,处理速度也可以忽略,相对这些速度,磁盘读写就显得慢了,现在好一点的数据库oracle存储数据都是写日志先暂存然后等机器空闲再写入到磁盘,这些都是为了提高效率,不然执行一条操作等半天
46.SecondaryNameNode的作用是什么?
SecondaryNameNode它的职责是合并NameNode的edit logs到fsimage文件中
首先,SecondaryNameNode定时到NameNode去获取edit logs,并更新到fsimage上。一旦它有了新的fsimage文件,SecondaryNameNode将其拷贝回NameNode中。NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
Secondary NameNode的整个目的是在HDFS中提供一个检查点。它只是NameNode的一个助手节点。这也是它在社区内被认为是检查点节点的原因。
ETL
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
通常情况下,在BI项目中ETL会花掉整个项目至少1/3的时间,ETL设计的好坏直接关接到BI项目的成败。
ETL的设计分三部分:数据抽取、数据的清洗转换、数据的加载。
ETL的实现有多种方法,常用的有三种。
一种是借助ETL工具(如Oracle的OWB、SQL Server 2000的DTS、SQL Server2005的SSIS服务、Informatic等)实现,
一种是SQL方式实现,另外一种是ETL工具和SQL相结合。前两种方法各有各的优缺点,借助工具可以快速的建立起ETL工程,屏蔽了复杂的编码任务,提高了速度,降低了难度,但是缺少灵活性。
SQL的方法优点是灵活,提高ETL运行效率,但是编码复杂,对技术要求比较高。第三种是综合了前面二种的优点,会极大地提高ETL的开发速度和效率。
一、 数据的抽取(Extract)
这一部分需要在调研阶段做大量的工作,首先要搞清楚数据是从几个业务系统中来,各个业务系统的数据库服务器运行什么DBMS,是否存在手工数据,手工数据量有多大,是否存在非结构化的数据等等,当收集完这些信息之后才可以进行数据抽取的设计。
1、对于与存放DW的数据库系统相同的数据源处理方法
这一类数据源在设计上比较容易。一般情况下,DBMS(SQLServer、Oracle)都会提供数据库链接功能,在DW数据库服务器和原业务系统之间建立直接的链接关系就可以写Select 语句直接访问。
2、对于与DW数据库系统不同的数据源的处理方法
对于这一类数据源,一般情况下也可以通过ODBC的方式建立数据库链接——如SQL Server和Oracle之间。如果不能建立数据库链接,可以有两种方式完成,
一种是通过工具将源数据导出成.txt或者是.xls文件,然后再将这些源系统文件导入到ODS中。另外一种方法是通过程序接口来完成。
3、对于文件类型数据源(.txt,.xls),可以培训业务人员利用数据库工具将这些数据导入到指定的数据库,然后从指定的数据库中抽取。或者还可以借助工具实现。
4、增量更新的问题
对于数据量大的系统,必须考虑增量抽取。一般情况下,业务系统会记录业务发生的时间,我们可以用来做增量的标志,每次抽取之前首先判断ODS中记录最大的时间,然后根据这个时间去业务系统取大于这个时间所有的记录。
利用业务系统的时间戳,一般情况下,业务系统没有或者部分有时间戳。
二、数据的清洗转换(Cleaning、Transform)
一般情况下,数据仓库分为ODS、DW两部分。通常的做法是从业务系统到ODS做清洗,将脏数据和不完整数据过滤掉,在从ODS到DW的过程中转换,进行一些业务规则的计算和聚合。
1、 数据清洗
数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。
不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。
(1)不完整的数据:这一类数据主要是一些应该有的信息缺失,如供应商的名称、分公司的名称、客户的区域信息缺失、业务系统中主表与明细表不能匹配等。对于这一类数据过滤出来,按缺失的内容分别写入不同Excel文件向客户提交,
要求在规定的时间内补全。补全后才写入数据仓库。
(2)错误的数据:这一类错误产生的原因是业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如数值数据输成全角数字字符、字符串数据后面有一个回车操作、日期格式不正确、日期越界等。
这一类数据也要分类,对于类似于全角字符、数据前后有不可见字符的问题,只能通过写SQL语句的方式找出来,然后要求客户在业务系统修正之后抽取。日期格式不正确的或者是日期越界的这一类错误会导致ETL运行失败,
这一类错误需要去业务系统数据库用SQL的方式挑出来,交给业务主管部门要求限期修正,修正之后再抽取。
(3)重复的数据:对于这一类数据——特别是维表中会出现这种情况——将重复数据记录的所有字段导出来,让客户确认并整理。
数据清洗是一个反复的过程,不可能在几天内完成,只有不断的发现问题,解决问题。对于是否过滤,是否修正一般要求客户确认,对于过滤掉的数据,写入Excel文件或者将过滤数据写入数据表,
在ETL开发的初期可以每天向业务单位发送过滤数据的邮件,促使他们尽快地修正错误,同时也可以做为将来验证数据的依据。数据清洗需要注意的是不要将有用的数据过滤掉,对于每个过滤规则认真进行验证,并要用户确认。
2、 数据转换
数据转换的任务主要进行不一致的数据转换、数据粒度的转换,以及一些商务规则的计算。
(1)不一致数据转换:这个过程是一个整合的过程,将不同业务系统的相同类型的数据统一,比如同一个供应商在结算系统的编码是XX0001,而在CRM中编码是YY0001,这样在抽取过来之后统一转换成一个编码。
(2)数据粒度的转换:业务系统一般存储非常明细的数据,而数据仓库中数据是用来分析的,不需要非常明细的数据。一般情况下,会将业务系统数据按照数据仓库粒度进行聚合。
(3)商务规则的计算:不同的企业有不同的业务规则、不同的数据指标,这些指标有的时候不是简单的加加减减就能完成,这个时候需要在ETL中将这些数据指标计算好了之后存储在数据仓库中,以供分析使用。
做数据仓库系统,ETL是关键的一环。说大了,ETL是数据整合解决方案,说小了,就是倒数据的工具。回忆一下工作这么长时间以来,处理数据迁移、转换的工作倒还真的不少。但是那些工作基本上是一次性工作或者很小数据量。
可是在数据仓库系统中,ETL上升到了一定的理论高度,和原来小打小闹的工具使用不同了。究竟什么不同,从名字上就可以看到,人家已经将倒数据的过程分成3个步骤,E、T、L分别代表抽取、转换和装载。
其实ETL过程就是数据流动的过程,从不同的数据源流向不同的目标数据。但在数据仓库中,
ETL有几个特点,
一是数据同步,它不是一次性倒完数据就拉到,它是经常性的活动,按照固定周期运行的,甚至现在还有人提出了实时ETL的概念。
二是数据量,一般都是巨大的,值得你将数据流动的过程拆分成E、T和L。
Hive中追加导入数据的4种方式是什么?请写出简要语法
从本地导入: load data local inpath ‘/home/1.txt’ (overwrite)into table student;
从Hdfs导入: load data inpath ‘/user/hive/warehouse/1.txt’ (overwrite)into table student;
查询导入: create table student1 as select * from student;(也可以具体查询某项数据)
查询结果导入:insert (overwrite)into table staff select * from track_log;
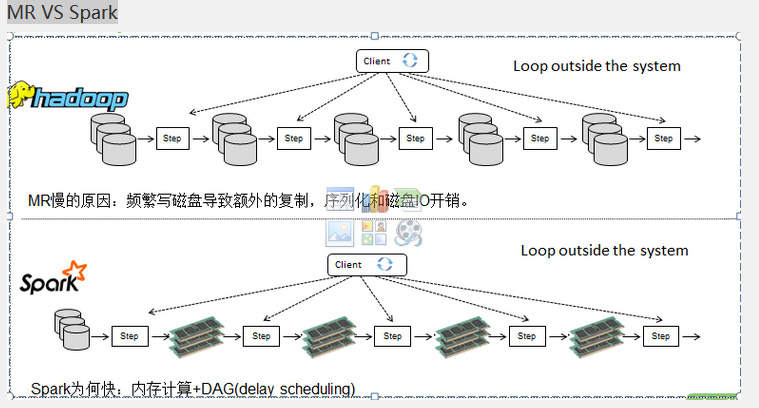
MR VS Spark