用户画像
营销推荐 邮件-短信-push信息(任务栏推荐)
有用的规律以支持决策
喜欢什么的东西的人往往喜欢什么
做了这个事的人一般接下来会做什么 啤酒与尿布

建模
客户消费订单
客户消费的情况来提取的客户标签
用于了解用户的消费总体情况,以根据用户消费习惯与消费能力做营销
订单表/退货表/退货表/购物车表
第一次消费时间/最近一次消费时间/首单距今时间
最小金额/累计消费次数/最大金额/累计使用代金券
客单价/近90天客单价
常用收货地区/常用支付方式
次数/商品件数/放弃件数
退货数量/金额/据收
反馈购物时间与地点习惯(上下班/早中晚)
客户购买类目表
根据客户购买类目的情况提取的客户标签
用于了解类目的购买人群情况和针对某一类目的营销等
类目维表/订单表
三级类目/购买次数/金额/累计金额
类目购物车次数/金额/累计金额/累计次数/最后一次购买时间/最后一次购买距今时间
客户购买商店表
根据客户购买商店的情况提取的客户标签
用于了解商店及品牌的购买人群情况
常用于针对某一品牌的营销,某店铺活动的营销
订单表/购物车表/商店表/退货表
商店id/名称/品牌名称/品牌id 一个商店包含多个品牌
客户基本属性表
根据客户所填的属性标签与推算出来的标签
用于了解用户的人口属性的基本情况和按属性统计
按人口属性营销,比如营销80后,对金牛的优惠,生日营销
用户表/用户调查表/孕妇模型表/马甲模型表/用户价值模型表
客户id/生日/省份/加密手机/登录来源/已使用积分
客户登录名/年龄/城市/注册时间/邀请人/会员等级名称
性别/大区域/邮箱/登录ip地址/会员积分/客户黑名单
根据多填信息得到
星座/箱运营商/城市等级/手机前几位/手机运营商
婚姻状况/月收入/是否有小孩/学历/职业/是否有车/使用手机品牌
得到数据:
性别模型/孩子性别/潜在汽车用户概率/使用多少种不同的手机/用户忠诚度/是否孕妇/孩子年龄概率
更换手机频率/用户购物类型/是否有小孩/是否有车/使用手机品牌档次/疑似马甲标志/身高/身材
性别模型
用户自己也填了性别,但仍然要使用算法算一次
用户性别 1男,0女,-1未识别 商品性别得分/用户购买上述商品计算用户性别得分/最优算法训练阈值
孩子性别 0仅有男孩 1仅有女孩 2男女均有 3无法识别 -1未识别 选择男童女童商品/购买商品的男女性别比例/训练阈值
性别验证方法
随机抽样几千条让客服电话确认/与用户自己填的性别做对比,确认百分比
用户汽车模型
用户是否有车 1有 -1未识别 根据用户购买车相关产品
潜在汽车用户 1有 -1未识别 用户浏览或搜索汽车/用户数据判断
用户忠诚度
忠诚度越高的用户越多,对网站的发展有利
1忠诚型用户 2偶尔型用户 3投资型用户 4浏览型用户 -1未识别
总体规则是判断+聚类算法
1浏览型 只浏览没购买
2购买天数大于一定天数的直接判断为忠诚型
3购买天数小于一定天数,大部分都是有优惠才购买的
4其他类型根据购买天数,购买最后一次距今时间,购买金额进行聚类
用户购物类型
归类方法很多,参考如下两种,对于营销参考意义比较大
1购物冲动型 2海涛犹豫型 3理性比较型 4目标明确型 -1未识别
计算用户在对三级品类购物前浏览时间和浏览SKU数量
1乐于尝试型 2价格敏感型 3消费冲动型 4昙花一现型 5重度消费型 -1未识别
计算用户对不同类型的商品的购买 频次与购买数量
用户身高尺码模型
方便根据身高与尺码控制进货与营销
男/女身高尺码 1身高断 -1未识别
男/女身材 1偏瘦 2标准 3偏胖 4肥胖 -1未识别
疑似马甲标志模型
马甲:一个用户注册多个账号
多次访问ip地址相同的相同账号是同一个所有
同一台手机登录多次的用户账号是同一个人所有
收货手机号相同的账号是同一个人所有
手机相关标签模型
对于手机营销参考意义比较大
使用手机品牌:最常用手机直接得到
使用手机品牌档次
使用多少种不同的手机
更换手机频率 :按时间看手机登录情况
客户营销信息表
将用户营销相关的常用标签放到一张表中,方便使用
用户表/订单表/活动表/购物车表/客户品类/用户价值
分群模型:品类分群,计算用户在各一级品类的购买金额
客户活跃状态模型:客户一般的活跃度 (注册未购买/活跃 高频/低频/中频) 沉默
用户价值模型:
体现用户对于网站的价值,用于提高用户留存率
使用RFM实现及用户价值模型参考指标
最近一次消费时间或者最后一次消费至今时间
消费频率
消费金额
计算方法:
使用指标:最近一次购买时间,近180天购买订单量,近180天购买金额,分5段(自定义)做分数计算
没有分数就是最近半年没有消费的用户,属于流失用户,即无价值用户,基本不会回来
区分 重要价值客户/重要保持客户/重要发展客户/重要挽留客户/一般.../无价值
购买频次高,金额大/很久没买/最近来购买,且金额大/金额大,频次低/.....
采用聚类算法,高/中/低/无价值
客户活动信息表
根据客户参与活动的情况提取的客户标签
用于了解用户对活动的参与情况,以进行活动策划或者根据对活动不同敏感的人群做营销
订单表/活动表/用户表/活动订单表
促销敏感度模型
根据用户购买的活动类型订单数与金额数以判断其属于哪类人群
单品促销高度/中/低/未识别 计算各类促销优惠的订单和金额占比
套装/团购/满返
用户购买力
购物车金额/客单价
败家指数/冲动指数
客户访问信息表
根据客户访问的情况提取客户标签
用于了解用户的访问总体情况,以根据用户浏览习惯做营销活动
PC端/APP端
访问日期/ip/城市/操作系统
注意:经常使用的聚类算法是 kmeans
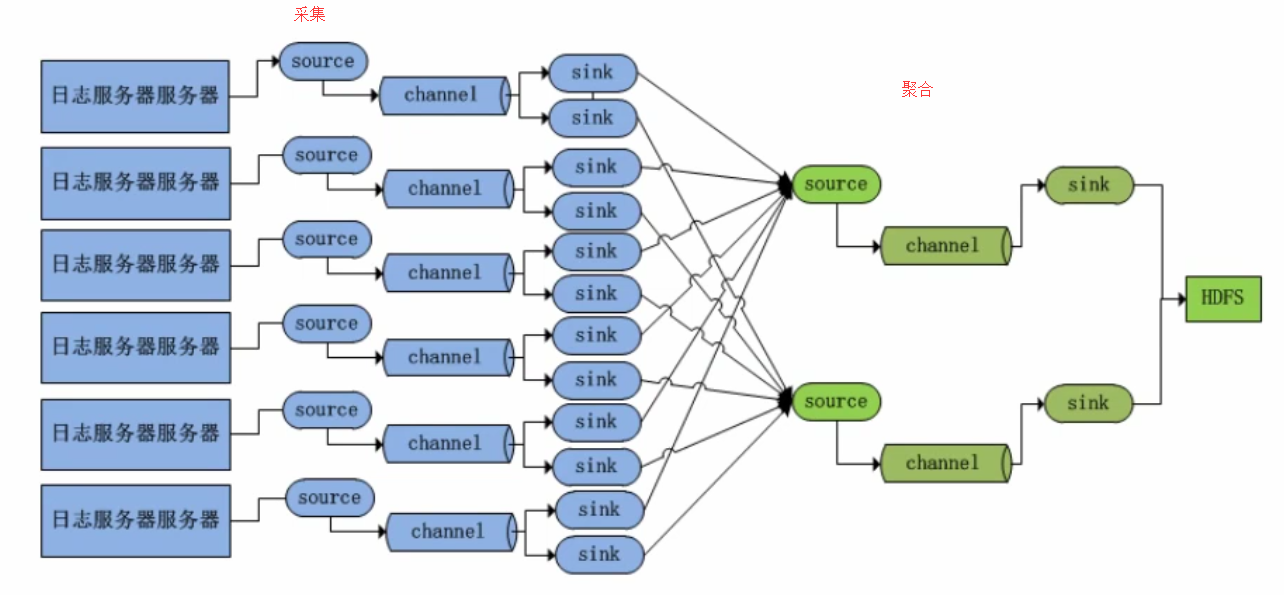
数据仓库已经做好的工作
数据已经从源数据库抽取装载到BDM层
FDM层根据BDM层已经填入按天分区的数据
没有每天的调度,也没有辅助的系统,都是手动生成
数据是造的测试数据,只有DT=2015-01-01的
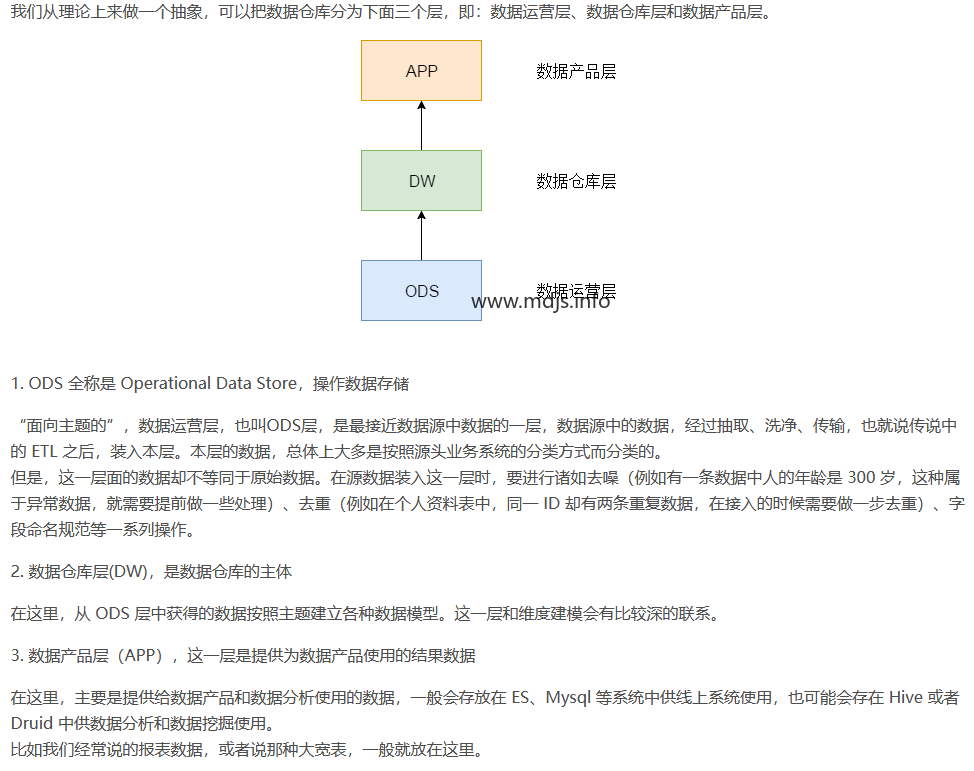
BDM层数据表 贴源的缓冲表
FDM层数据表 拉链表,或者按天区的表 根据BDM表处理转换而来
GDM层数据表 通用数据模型层 我们需要使用的数据
数据开发的前置依赖
需求确定
建模确定表结构
实现方案确定
数据开发的过程
表落地
按表写sql代码生成数据
部署代码 xxx.sh
数据测试
试运行与上线
date_sub
concat
coalesce 空转 0等
datediff 时间差距
to_date
row_number over distributed by sort by
FROM_UNIXTIME(unix_timestamp,format)
UNIX_TIMESTAMP()
用户画像基础知识
用户标签指标体系
搭建开发环境
标签数据存储
标签数据开发
开发性能调优
作业流程调度
用户画像产品化
用户画像应用
开发流程
目标解读 任务分解与需求调研 需求场景讨论与明确 应用场景与数据口径确认
特征选取与模型数据落表 线下模型数据验收与测试 线上模型发布与效果追踪
需要掌握的模块
数据开发 spark
数据存储和查询 hbase hive mysql
作业调度(ETL) crontab airflow
流式计算 kafka spark steaming
开发语言 hiveSql shell
需要知道开发哪些标签
这些标签的调度流是如何构成的
如何对每天的调度作业进行监控
哪些数据库可用于存储标签,为何用这些数据库进行存储
开发的标签服务于业务上的哪些应用
需要开发的表
用户属性维度 用户行为维度 用户消费维度 用户风控维度
用户人群表 业务系统表 监控系统表 用户行为明细表 用户偏好 群体偏好
用户画像及其应用项目规划说明书
项目名称 项目背景及概要 项目目标 项目适用范围
系统功能及模型架构
系统功能 底层数据源采集和存储 画像标签模型构建 数据模型应用
模型架构 原始数据统计分析 统计标签建模分析 模型标签预测分析
需求设计
用户画像模型 人口属性 行为属性 疾病问诊 订单消费 用户偏好 客户满意度
接口封装 push推送
UI设计
场景应用及流程
运行环境
网络与硬件设备
软件平台
用户标签应用实施方案说明书
标签开发内容
疾病标签 科室标签 医生标签 医院标签
应用实施流程
逻辑模型
数据字典
权重配置
时间衰减系数
执行结果
hive的查询注意事项以及优化总结
一、控制Hive中Map和reduce的数量
Hive中的sql查询会生成执行计划,执行计划以MapReduce的方式执行,那么结合数据和集群的大小,map和reduce的数量就会影响到sql执行的效率。
除了要控制Hive生成的Job的数量,也要控制map和reduce的数量。
1、 map的数量,通常情况下和split的大小有关系,之前写的一篇blog“map和reduce的数量是如何定义的”有描述。
hive中默认的hive.input.format是org.apache.hadoop.hive.ql.io.CombineHiveInputFormat,对于combineHiveInputFormat,它的输入的map数量
由三个配置决定,
mapred.min.split.size.per.node, 一个节点上split的至少的大小
mapred.min.split.size.per.rack 一个交换机下split至少的大小
mapred.max.split.size 一个split最大的大小
它的主要思路是把输入目录下的大文件分成多个map的输入, 并合并小文件, 做为一个map的输入. 具体的原理是下述三步:
a、根据输入目录下的每个文件,如果其长度超过mapred.max.split.size,以block为单位分成多个split(一个split是一个map的输入),每个split的长度都大于mapred.max.split.size, 因为以block为单位, 因此也会大于blockSize, 此文件剩下的长度如果大于mapred.min.split.size.per.node, 则生成一个split, 否则先暂时保留.
b、现在剩下的都是一些长度效短的碎片,把每个rack下碎片合并, 只要长度超过mapred.max.split.size就合并成一个split, 最后如果剩下的碎片比mapred.min.split.size.per.rack大, 就合并成一个split, 否则暂时保留.
c、把不同rack下的碎片合并, 只要长度超过mapred.max.split.size就合并成一个split, 剩下的碎片无论长度, 合并成一个split.
举例: mapred.max.split.size=1000
mapred.min.split.size.per.node=300
mapred.min.split.size.per.rack=100
输入目录下五个文件,rack1下三个文件,长度为2050,1499,10, rack2下两个文件,长度为1010,80. 另外blockSize为500.
经过第一步, 生成五个split: 1000,1000,1000,499,1000. 剩下的碎片为rack1下:50,10; rack2下10:80
由于两个rack下的碎片和都不超过100, 所以经过第二步, split和碎片都没有变化.
第三步,合并四个碎片成一个split, 长度为150.
如果要减少map数量, 可以调大mapred.max.split.size, 否则调小即可.
其特点是: 一个块至多作为一个map的输入,一个文件可能有多个块,一个文件可能因为块多分给做为不同map的输入, 一个map可能处理多个块,可能处理多个文件。
2、 reduce数量
mapred.reduce.tasks(强制指定reduce的任务数量)
hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,默认为1000^3=1G)
hive.exec.reducers.max(每个任务最大的reduce数,默认为999)
计算reducer数的公式很简单N=min( hive.exec.reducers.max ,总输入数据量/ hive.exec.reducers.bytes.per.reducer )
对于Group操作,首先在map端聚合,最后在reduce端坐聚合,hive默认是这样的,以下是相关的参数
· hive.map.aggr = true是否在 Map 端进行聚合,默认为 True
· hive.groupby.mapaggr.checkinterval = 100000在 Map 端进行聚合操作的条目数目
5、数据的倾斜还包括,大量的join连接key为空的情况,空的key都hash到一个reduce上去了,解决这个问题,最好把空的key和非空的key做区分
空的key不做join操作。
· hive.merge.mapredfiles = false是否合并 Reduce 输出文件,默认为 False
· hive.merge.size.per.task = 256*1000*1000合并文件的大小
etl面试
问题1:假如有一个job突然失败了,那么你第一时间应该先去看哪里。
首先去看job history,看具体的错误信息,根据这个信息决定如何去解决问题。
如果在ETL中有自定义的日志输出,那么再去看自定义日志的内容。
问题2:假如一个job本来应该在凌晨两点跑完的,但是早上上班的时候发现还没有跑完,接下来会怎么做。
这么久的延迟最有可能是阻塞,比如下游报表或者客户端仍在数据仓库里查数,如果发现ETL进程被阻塞,kill掉阻塞的进程,确保ETL能正常进行下去。
问题3:接到用户抱怨说一个报表运行的很慢,如何处理
先跑一下这个报表,重现一下运行缓慢的现象。然后看看到底是卡在了哪条查询,把查询单独拿出来进行进一步分析和优化
问题4:如何进一步优化
看执行计划,查看几个关键点,比如索引缺失,SQL语句需要优化等问题。
问题5:如何快速的知道是由于索引缺失导致的
看执行计划,看是否有表扫描,如果有说明索引缺失,也可以先看执行计划里哪部分消耗的资源(百分比)最高,然后看里面所消耗的io数值是否很高,如果是的话说明索引也是有缺失,需要根据具体的情况添加索引。
同时查看WHERE条件添加顺序,第一个条件尽可能多的过滤数据
看join条件,再看有没有索引