Array & String
大纲
1. 入门题 string match
2. Array 中 HashTable 的应用
3. C/C++ 中的 string
4. 例题分析
part 1 入门题
在 source(母串)中,寻找 target(子串) 是否出现。


/* Returns the position of the first occurrence of string target in string source, or -1 if target is not part of source.*/ int strStr(String source, String target) { //… }
字符串匹配
两种比较易于实现的字符串比较算法:
假设在长度为 n 的母串中匹配长度为 m 的子串。(http://en.wikipedia.org/wiki/String_searching_algorithm)。
1. Brute-Force 算法: 顺序遍历母串,将每个字符作为匹配的起始字符,判断是否匹配子串。时间复杂度 O(m*n)
char* strStr(const char *str, const char *target) { if(!*target) return str; char *p1 = (char*)str; while(*p1) { char *p1Begin = p1, *p2 = (char*)target; while(*p1 && *p2 && *p1 == *p2) { p1++; p2++; } if(!*p2) return p1Begin; p1 = p1Begin + 1; } return NULL; }
2.Rabin-Karp 算法 :将每一个匹配子串映射为一个hash值。例如,将子串看做一个多进制数,比较它的值与母串中相同长度子串的hash值,如果相同,再细致地按字符确认字符串是否确实相同。顺序计算母串hash值的过程中,使用增量计算的方法:扣除最高位的hash值,增加最低位的hash值。因此能在平均情况下做到O(m+n)。
#include <string> #include <iostream> #include <functional> using namespace std; size_t Rabin_karp_StrStr(string &source, string &target) { hash<string> strHash; size_t targetHash = strHash(target); for (size_t i = 0; i < source.size() - target.size() + 1; i++) { string subSource = source.substr(i, target.size()); if (strHash(subSource) == targetHash) { if (subSource == target) return i; } } return 0; } int main() { string s1 = "abcd"; string s2 = "cd"; cout << Rabin_karp_StrStr(s1, s2); return 0; }
part 2 Array
int array[arraySize]; //在Stack上定义长度为arraySize的整型数组 int *array = new int[arraySize]; //在Heap上定义长度为arraySize的整型数组 delete[] array; //使用完后需要释放内存:
注意,在旧的编译器中,不能在Stack上定义一个长度不确定的数组,即只能定义如下:
int array[10];
新的编译器没有如上限制。但是如果数组长度不定,则不能初始化数组:
int array[arraySize] = {0}; //把不定长度的数组初始化为零,编译报错。
part 3 工具箱:Stack Vs. Heap
Stack主要是指由操作系统自动管理的内存空间。当进入一个函数,操作系统会为该函数中的局部变量分配储存空间。事实上,系统会分配一个内存块,叠加在当前的stack上,并且利用指针指向前一个内存块的地址。
函数的局部变量就存储在当前的内存块上。当该函数返回时,系统“弹出”内存块,并且根据指针回到前一个内存块。所以,Stack总是以后进先出(LIFO)的方式工作
Heap是用来储存动态分配变量的空间。对于heap而言,并没有像stack那样后进先出的规则,程序员可以选择随时分配或回收内存。这就意味着需要程序员自己用命令回收内存,否则会产生内存泄露(memory leak)。
在C/C++中,程序员需要调用free/delete来释放动态分配的内存。在JAVA,Objective-C (with Automatic Reference Count)中,语言本身引入垃圾回收和计数规则帮助用户决定在什么时候自动释放内存。
part 4 二维数组
//在Stack上创建: int array[M][N]; //传递给子函数: void func(int arr[M][N]) { /* M可以省略,但N必须存在,以便编译器确定移动内存的间距 */ } //在Heap上创建: int **array = new int*[M]; // 或者 (int**)malloc( M * sizeof(int*) ); for( int i = 0; i < M; i++) array [i] = new int[N]; // 或者 (int*)malloc( N * sizeof(int) ); //传递给子函数: void func( int **arr, int M, int N ){} //使用完后需要释放内存: for( int i = 0; i < M; i++) delete[] array[i]; delete[] array;
part 5 工具箱:Vector
vector可以用运算符[]直接访问元素。请参考http://www.cplusplus.com/reference/vector/vector/
size_type size() const; // Returns the number of elements in the vector. void push_back (const value_type& val); void pop_back(); iterator erase (iterator first, iterator last); // Removes from the vector either a singleelement (position) or a range of elements ([first,last)). for (vector<int>::iterator it = v.begin(); it != v.end(); ) { if (condition) { it = v.erase(it); } else { ++it; } }
part 6 Hash Table
Hash table 几乎是最为重要的数据结构,主要用于基于“key”的查找,存储的基本元素是 key-value 的 pair。逻辑上,数组可以作为 Hash table 的一个特例:key是一个非负整数。
Operations
- Insert - O(1)
- Delete - O(1)
- Find - O(1)
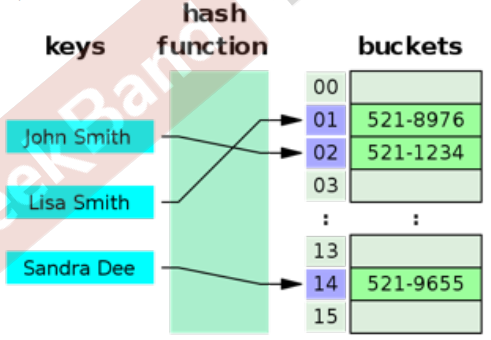
哈希碰撞 - Open Hashing(再哈希法) vs Closed Hashing(链地址法)

part 7 C++标准库
提供map容器,可以插入,删除,查找key-value pair,底层以平衡二叉搜索树的方式实现,根据key进行了排序。
在C++11中,标准库添加了unordered_map,更符合Hash table的传统定义,平均查找时间O(1)
part 8 String
在C语言中,字符串指的是一个以’�’结尾的char数组。关于字符串的函数通常需要传入一个字符型指针。
在C++中,String是一个类,并且可以通过调用类函数实现判断字符串长度,子串等等操作。
part 9 工具箱:C语言中String常用函数
char *strcpy ( char *destination, const char *source ); //copy source string to destination string char *strcat ( char *destination, const char *source ); //Appends a copy of the source string to the destination string. int strcmp ( const char *str1, const char *str2 ); char *strstr (char *str1, const char *str2 ); // Returns a pointer to the first occurrence of str2 in str1, or a NULL pointer if str2 is not part of str1. size_t strlen ( const char *str ); // Returns the length of the C string str. double atof (const char *str); // convert char string to a double int atoi (const char *str); // convert char string to an int
part 10 工具箱:C++中String类常用函数
String类重载了+, <, >, =, ==等运算符,故复制、比较、判断是否相等,附加子串等都可以用运算符直接实现。请参考( http://www.cplusplus.com/reference/string/string/)
size_t find (const string& str, size_t pos = 0) const; // Searches the string for the first occurrence of the str, returns index string substr (size_t pos = 0, size_t len = npos) const; // Returns a newly constructed string object with its value initialized to a copy of a substring starting at pos with length len. string &erase (size_t pos = 0, size_t len = npos); // erase characters from pos with length len size_t length(); // Returns the length of the string, in terms of bytes
Section 1, String
模式识别
当遇到某些题目需要统计一个元素集中元素出现的次数,应该直觉反应使用 Hash Table,即使用 std::unordered_map 或 std::map:key 是元素,value 是出现的次数。特别地,有一些题目仅仅需要判断元素出现与否(相当于判断 value 是0还是1),可以用 bitvector,即 bitset,利用一个bit来表示当前的下标是否有值。
例子1 Determine if all characters of a string are unique.
提示:一般来说,一旦出现 “unique”,就落入使用 hash table 或者 bitset 来判断元素出现与否的范畴。
代码如下:
#include <bitset> #include <string> #include <iostream> using namespace std; bool isUnique(string &s) { bitset<256> hashMap; //ASCII码总共256个 for (string::size_type i = 0; i < s.length(); i++) { if (hashMap[(int)s[i]]) return false; else hashMap[(int)s[i]] = 1; } return true; } int main() { string s = "fengyubo"; if (isUnique(s)) cout << 1; else cout << 0; return 0; }
例子2 : Given two strings, determine if they are permutations of each other.
解法1:置换的特性:无论如何变化,每个字符出现的次数一定相同。一旦需要统计一个元素集中元素出现的次数,我们就应该想到hash table。
hash table 需要扫描整个 string,平均时间复杂度都是 O(n)。最后比较两个 hash 是否相同,每个合法字符都有可能出现,假设字符集大小为 m,则需要的时间复杂度是 O(m),故总的时间复杂度 O(m+n)。空间上,平均空间是 O(m)。
代码:
#include <unordered_map> #include <iostream> #include <string> using namespace std; bool isPermutation(string &s1, string &s2) { if (s1.length() != s2.length()) return false; unordered_map<char, unsigned> hashMap1; unordered_map<char, unsigned> hashMap2; for (string::size_type i = 0; i < s1.length(); i++) hashMap1[s1[i]]++; for (string::size_type i = 0; i < s2.length(); i++) hashMap2[s2[i]]++; if (hashMap1 == hashMap2) return true; return false; } int main() { string s1 = "feng"; string s2 = "yubo"; if (isPermutation(s1, s2)) cout << 1; else cout << 0; return 0; }
解法2:对每个 string 中的字符按照 ASCII 编码顺序进行排序。如果是一个置换,那么排序完的两个string应该相等。这样做的时间复杂度是 O(n log n),空间复杂度是O(n)。
注:实际的操作中发现,首席需要把 string 中的字符逐个转换成 ASCII 码,转换一个字符串的时间复杂度是 O(n);转换两个字符串,再加上两次排序工作,总体的时间复杂度是 O(n + m + n log n + m log m)。又因为如果n != m 时会提前退出循环,所以时间复杂度应该是 O(2n + 2 n log n)。——可能是我对时间复杂度的概念了解的还不够深入,需要回过头来读一读《数据结构与算法分析》。
代码:
#include <iostream> #include <string> #include <vector> #include <algorithm> using namespace std; bool isPermutation(string &s1, string &s2) { if (s1.length() != s2.length()) return false; vector<int> v1; vector<int> v2; for (string::size_type i = 0; i < s1.length(); i++) v1.push_back((int)s1[i]); for (string::size_type i = 0; i < s2.length(); i++) v2.push_back((int)s2[i]); sort(v1.begin(), v1.end()); sort(v2.begin(), v2.end()); if (v1 == v2) return true; return false; } int main() { string s1 = "feng"; string s2 = "gnef"; if (isPermutation(s1, s2)) cout << "1"; else cout << "0"; return 0; }
经验:quick sort 和 merge sort 等排序的时间复杂度都是 O(n log n)。
例子 3 :Given a newspaper and message as two strings, check if the message can be composed using letters in the newspaper.
解题分析:message 中用到的字符必须出现在 newspaper 中。其次,message 中任意字符出现的次数一定少于其在 newspaper 中出现的次数。统计一个元素集中元素出现的次数,我们就应该想到 hash table
复杂度分析:假设 message 长度为 m,newspaper 长度为 n,我们的算法需要 hash 整条 message 和整个 newspaper,故时间复杂度 O(m + n)。假设字符集大小为c,则平均空间是O(c)。
代码:
#include <iostream> #include <string> #include <unordered_map> using namespace std; bool canCompose(string newspaper, string message) { if (newspaper.length() < message.length()) return false; unordered_map<char, unsigned> hashTable; for (string::size_type i = 0; i < newspaper.length(); i++) hashTable[newspaper[i]]++; for (string::size_type i = 0; i < message.length(); i++) { if (hashTable[message[i]] == 0) return false; --hashTable[message[i]]; } return true; } int main() { string s1 = "fengyubo yingzhe"; string s2 = "fengyingzhe"; cout << (int)canCompose(s1, s2); return 0; }
Anagram
Write a method anagram(s,t) to decide if two strings are anagrams or not.
Example:
Given s="abcd", t="dcab", return true.
Challenge:
O(n) time, O(1) extra space
代码:
#include <string> #include <iostream> using namespace std; bool isAnargram(string s, string t) { if (s.length() != s.length()) return false; int sum = 0; for (string::size_type i = 0; i < s.length(); i++) { sum += (int)s[i]; sum -= (int)t[i]; } if (sum == 0) return true; return false; } int main() { cout << (int)isAnargram("feng", "gnef"); return 0; }
模式识别
当处理当前节点需要依赖于之前的部分结果时,可以考虑使用 hash table 记录之前的处理结果。其本质类似于 Dynamic Programming,利用 hash table 以 O(1) 的时间复杂度获得之前的结果。
例子 4 :Find a pair of two elements in an array, whose sum is a given target number.
最直观的方法是再次扫描数组,判断 target – array[i] 是否存在在数组中。这样做的时间复杂度是 O(n^2)
如何保存之前的处理结果?可以使用 hash table 。询问 hash table ,target – array[i] 是否存在在数组中,把 target – array[i] 作为 key。
复杂度分析:数组中的每个元素进行上述 hash 处理,从头至尾扫描数组,判断对应的另一个数是否存在在数组中,时间复杂度O(n)。
代码:
#include <vector> #include <iostream> #include <unordered_map> using namespace std; template<typename T> pair<T, T> find2Target(vector<T> &v, T target) { unordered_map<T, T> hashTable; for (vector<T>::iterator it = v.begin(); it != v.end(); it++) { //unordered_map.count(k) 返回关键字等于 k 的元素的数量。对于不允许重复关键字的容器,返回值永远都是 0 或 1 if (hashTable.count(target - *it)) return make_pair(*it, target - *it); hashTable.insert(make_pair(*it, target - *it)); } return make_pair(0, 0); } int main() { vector<int> v = { 1, 2, 3, 4, 5, 6, 7 }; pair<int, int> par = find2Target<int>(v, 10); cout << par.first << " " << par.second; return 0; }
例子 5: Get the length of the longest consecutive elements sequence in an array. For example, given [31, 6, 32, 1, 3, 2],the longest consecutive elements sequence is [1, 2, 3]. Return its length: 3.
解题思路:判断 array[i] – 1,array[i] + 1 是否存在于数组中。如何保存之前的处理结果?可以使用 hash table 由于序列是一系列连续整数,所以只要序列的最小值以及最大值,就能唯一确定序列。而所谓的“作为后继加入序列”,“作为前驱加入序列”,更新最大最小值。hash table 的 value 可以是一个记录最大/最小值的 structure,用以描述当前节点参与构成的最长序列。
该解法的时间复杂度O(n),附加空间O(n)
示范代码:
#include <vector> #include <unordered_map> #include <iostream> using namespace std; struct Bound { int high; int low; Bound(int h = 0, int l = 0) : high(h), low(l) {} }; int longestConsecutive(vector<int> &num) { unordered_map<int, Bound> table; int local; int maxLen = 0; for (vector<int>::size_type i = 0; i < num.size(); i++) { if (table.count(num[i])) //遇到重复出现的元素则跳过 continue; local = num[i]; int low = local, high = local; if (table.count(local - 1)) low = table[local - 1].low; if (table.count(local + 1)) high = table[local + 1].high; table[low].high = table[local].high = high; table[high].low = table[local].low = low; if (high - low + 1 > maxLen) maxLen = high - low + 1; } return maxLen; } int main() { vector<int> v = {31, 6, 32, 1, 3, 2}; cout << longestConsecutive(v); return 0; }
Longest Common Substring
Given two strings, find the longest common substring. Return the length of it.
Example:
Given A="ABCD", B="CBCE", return 2.
Note:
The characters in substring should occur continuously in original string. This is different with subsequence.
代码:
#include <iostream> #include <string> #include <algorithm> using namespace std; size_t longestSubstring(const string &s1, const string &s2) { size_t subStrLength = 0; size_t longestLength = 0; string::size_type minStrLength = min(s1.length(), s2.length()); for (string::size_type i = 0; i < minStrLength; i++) { if (s1[i] != s2[i]) { subStrLength = 0; continue; } subStrLength++; if (subStrLength > longestLength) longestLength = subStrLength; } return longestLength; } int main() { string a = "ABCD"; string b = "CBCDE"; cout << longestSubstring(a, b); return 0; }
友情提示 : String相关问题的一些处理技巧。
通常,纯粹的字符串操作难度不大,但是实现起来可能比较麻烦、edge case比较多。例如把字符串变成数字,把数字变成字符串等等。
需要与面试官进行沟通,明确他们期望的细节要求,再开始写代码。
可以利用一些子函数,使得代码结构更加清晰。考虑到时间限制,往往有的时候面试官会让你略去一些过于细节的实现。
(注 edge case 的释义 from wikipedia : An edge case is a problem or situation that occurs only at an extreme (maximum or minimum) operating parameter.)
Reverse Words in String
Given input -> "I have 36 books, 40 pens2."; output -> "I evah 36 skoob, 40 2snep.”
解题分析:
每个以空格或符号为间隔的单词逆向输出,如果遇到纯数字,则不改变顺序。自然而然地,每次处理分为两个步骤:1)判断是否需要逆向 2)逆向当前单词。这样就可以分为两个子函数:一个负责判断,另一个负责逆向。然后进行分段处理。
代码:
#include <iostream> #include <string> using namespace std; bool needReverse(const string::iterator &chaser, const string::iterator &runner) { string::iterator it = chaser; while(it != runner) { if(*it < '0' || *it > '9') return true; it++; } return false; } void reverseWord(const string::iterator &chaser, const string::iterator &runner) { if(chaser > runner) return ; string::iterator c = chaser; string::iterator r = runner; while(c < r) swap(*c++, *r--); } void reverseSentence(string &sentence) { string::iterator runner = sentence.begin(); string::iterator chaser = sentence.begin(); while(runner != sentence.end()) { if( *(runner + 1) == ' ' || *(runner + 1) == ',' || *(runner + 1) == '.') { if(needReverse(chaser, runner + 1)) reverseWord(chaser, runner); runner++; //next letter while( *(runner) == ' ' || *(runner) == ',' || *(runner) == '.' ) runner++; chaser = runner; } else { runner++; } } } int main() { string s = "I have 36 books, 40 pens2."; reverseSentence(s); cout << s <<endl; return 0; }
Rotate String
Given a string and an offset, rotate string by offset. (rotate from left to right)
Example
Given "abcdefg"
for offset=0, return "abcdefg"
for offset=1, return "gabcdef"
代码:
#include <string> #include <iostream> using namespace std; string rotateString(string s, int offset) { offset = offset % s.length(); string s2 = s.substr(0, s.length() - offset); s2 = s.substr(s.length() - offset, s.length()) + s2; return s2; } int main() { string s = "abcdefg"; cout << rotateString(s, 3) <<endl; return 0; }
Section 2, Array
Remove Element
Given an array and a value, remove all occurrences of that value in place and return the new length. The order of elements can be changed, and the elements after the new length don't matter.
Example:
Given an array [0,4,4,0,0,2,4,4], value=4
return 4 and front four elements of the array is [0,0,0,2]
代码:
#include <vector> #include <iostream> using namespace std; //删除元素 - 基于 vector 和迭代器实现 template<typename T> void removeElementsVector(vector<T> &v, T e) { vector<T>::iterator it = v.begin(); while (it != v.end()) { if (*it == e) { it = v.erase(it); } else { it++; } } } //删除元素 - 基于指针实现 template<typename T> size_t removeElementPointer(T arr[], size_t n, T e) { size_t i = 0; while(i < n) { if (arr[i] == e) { //向前倒后面的元素 for (size_t k = i; k < n - 1; k++) arr[k] = arr[k + 1]; n--; } else { i++; } } return n; } int main() { vector<int> v = { 0, 4, 4, 0, 0, 2, 4, 4 }; removeElementsVector<int>(v, 4); for (auto e : v) cout << e << " "; // C++中的 << 功能和语义上类似 unix >> 重定向追加符 cout << endl; int arr[] = { 0, 4, 4, 0, 0, 2, 4, 4 }; size_t len = removeElementPointer(arr, sizeof(arr) / sizeof(int), 4); for (size_t i = 0; i < len; i++) cout << arr[i] << " "; return 0; }
Remove Duplicates from Sorted Array I
Given a sorted array, remove the duplicates in place such that each element appear only once and return the new length.
Do not allocate extra space for another array, you must do this in place with constant memory.
For example:
Given input array nums = [1,1,2],
Your function should return length = 2, with the first two elements of nums being 1 and 2 respectively. It doesn't matter what you leave beyond the new length.
代码:
#include <vector> #include <iostream> using namespace std; template<typename T> size_t removeDuplicatesSortedArray1(vector<T> &v, const T e) { vector<T>::iterator it = v.begin(); while ((it + 1) != v.end()) { if (*it == *(it + 1)) { it = v.erase(it); } else { it++; } } return v.size(); } int main() { vector<int> v = {1, 1, 2, 3, 3, 3, 5}; cout << removeDuplicatesSortedArray1<int>(v, 1) << endl; for (auto e : v) cout << e << " "; return 0; }
Merge Sorted Array
1. Merge Two Sorted Array into a new Array. (务必要从后往前来拷贝!)
代码:
#include <iostream> using namespace std; int* mergeSortedArray(int A[], int m, int B[], int n) { int *p = (int*)malloc(sizeof(int) * (m + n)); int index = m + n; while ((m > 0) && (n > 0)) { if (A[m - 1] > B[n - 1]) { p[--index] = A[--m]; } else { p[--index] = B[--n]; } } while (m > 0) p[--index] = A[--m]; while (n > 0) p[--index] = B[--n]; return p; } int main() { int A[] = { 9, 10 }; int B[] = { 2, 4, 6 }; int *p = mergeSortedArray(A, 2, B, 3); for (int i = 0; i < 2 + 3; i++) cout << p[i] << " "; return 0; }
2. Merge Two Sorted Array A and B into A, assume A has enough space.
代码:
#include <iostream> using namespace std; void mergeSortedArray(int A[], int m, int B[], int n) { int index = n + m; while (m > 0 && n > 0) { if (A[m - 1] > B[n - 1]) { A[--index] = A[--m]; } else { A[--index] = B[--n]; } } while (n > 0) { A[--index] = B[--n]; } // is this necessary? while (m > 0) { A[--index] = A[--m]; } } int main() { int A[5] = { 9, 10 }; int B[] = { 2, 4, 6 }; mergeSortedArray(A, 2, B, 3); for (auto e : A) cout << e << " "; return 0; }
Partition
Given an array nums of integers and an int k, partition the array (i.e move the elements in "nums") such that:
All elements < k are moved to the left
All elements >= k are moved to the right
Return the partitioning index, i.e the first index i nums[i] >= k.
Example:
If nums=[3,2,2,1] and k=2, a valid answer is 1. If all elements in nums are smaller than k, then return nums.length challenge
Can you partition the array in-place and in O(n)?
#include <vector> #include <iostream> using namespace std; size_t partition(const vector<int> &v, const int threshold) { vector<int>::const_iterator itLeft = v.cbegin(); vector<int>::const_iterator itRight = v.cbegin() + v.size() - 1; size_t index = 0; while (itLeft <= itRight) { if (*itLeft++ < threshold || *itRight-- < threshold) { index++; } } return index; } int main() { vector<int> v = { 3, 2, 2, 1 }; cout << partition(v, 2); return 0; }
Median
Given a unsorted array with integers, find the median of it. A median is the middle number of the array after it is sorted. If there are even numbers in the array, return the N/2-th number after sorted.
Example
Given [4, 5, 1, 2, 3], return 3
Given [7, 9, 4, 5], return 5
在O(N)的时间复杂度内解决。
#include <iostream> #include <map> #include <vector> using namespace std; int medium(vector<int>& v) { map<int, unsigned int> m; for (auto &e : v) { m[e]++; } size_t middle = v.size() / 2; if (v.size() % 2) { //odd middle = (v.size() + 1) / 2; } for( auto &e : m) { middle -= e.second; if (middle == 0) return e.first; } return -1; } int main() { vector<int> v = { 4, 5, 1, 2, 3 }; vector<int> v2 = { 7, 9, 4, 5 }; cout << medium(v) << endl; cout << medium(v2) << endl; return 0; }
Homework
Replace space with '%20'
Replace space in the string with “%20”. E.g. given "Big mac", return “Big%20mac”
解题思路:要求 in-place 的删除或修改,可以用两个 int 变量分别记录新 index 与原 index,不断地将原 index 所指的数据写到新 index 中。如果改动后 string 长度增大,则先计算新 string 的长度,再从后往前对新 string 进行赋值;反之,则先从前往后顺序赋值,再计算长度。
利用高级语言特性,轻松地以 O(n) 的时间复杂度解决。
#include <iostream> #include <string> using namespace std; string replaceSpace(const string& str) { string strURL; string::const_iterator it = str.begin(); while (it != str.end()) { if (*it == ' ') { strURL += "%20"; } else { strURL += *it; } it++; } return strURL; } int main() { cout << replaceSpace("Big mac") << endl; return 0; }
使用 C 语言字符、指针以及手动控制内存。
#include <stdio.h> #include <string.h> #include <stdlib.h> #include <iostream> using namespace std; char* replaceSpace(const char* s) { int spaceNum = 0; const size_t sLen = strlen(s); const char* r = "%20"; const size_t rLen = strlen(r); for (size_t i = 0; i < sLen; i++) if (s[i] == ' ') spaceNum++; size_t j = sLen + spaceNum * (rLen - 1); char* str = (char*)malloc(sizeof(char) * (j + 1)); str[j] = '�'; for (size_t i = sLen; i > 0; i--, j--) { if (s[i - 1] == ' ') { for (size_t i = strlen(r); i > 0 ; i--, j--) str[j - 1] = r[i - 1]; j++; } else { str[j - 1] = s[i - 1]; } } return str; } int main() { char *s = replaceSpace("Big Mac"); printf("%s ", s); free(s); return 0; }
Anagrams of string array
Given an array of strings, return all groups of strings that are anagrams.
Example
Given ["lint", "intl", "inlt", "code"], return ["lint", "inlt", "intl"].
Given ["ab", "ba", "cd", "dc", "e"], return ["ab", "ba", "cd", "dc"].
Note
All inputs will be in lower-case
时间复杂度 O(n) 的解法:
#include <iostream> #include <string> #include <algorithm> #include <initializer_list> #include <vector> #include <map> using namespace std; vector<string>* anagramArray(const initializer_list<string>& il) { vector<string>* pIL = new vector<string>; map<string, unsigned int> m; for (auto &e : il) { string temp = e; sort(temp.begin(), temp.end()); m[temp]++; } for (auto &e : il) { string temp = e; sort(temp.begin(), temp.end()); if (m[temp] > 1) pIL->push_back(e); } return pIL; } int main() { vector<string>* pIl = anagramArray({ "lint", "intl", "inlt", "code" }); for (auto &e : *pIl) { cout << e << " "; } delete pIl; }
实现HashTable