1.元胞数组应用:
①将一个数组存储在一个元胞中,用以下代码(注意{}的使用)
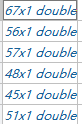
dri_ID_all1{1,1} = ones(67,1);
dri_ID_all1{2,1} = 2*ones(56,1);
dri_ID_all1{3,1} = 3*ones(57,1);
dri_ID_all1{4,1} = 4*ones(48,1);
dri_ID_all1{5,1} = 5*ones(45,1);
dri_ID_all1{6,1} = 6*ones(51,1);
变量如下:
小扩展:
①可以与find合用,根据对valid_index的条件索引,将不同类别数据的索引存储在不同的元胞中。
file_index = cell(file_num,1); %按照驾驶员对换道路段进行分类 file_index{1} = valid_index(find(valid_index>=1,1):find(valid_index>=15,1)); %驾驶员1的index:valid_index在[1:15]范围内的路段: file_index{2} = valid_index(find(valid_index>=16,1):find(valid_index>=28,1)); %驾驶员2的index:...[16:28]; file_index{3} = valid_index(find(valid_index>=29,1):find(valid_index>=49,1)); %驾驶员3的index:...[29:49]; file_index{4} = valid_index(find(valid_index>=50,1):find(valid_index>=69,1)); %驾驶员4的index:...[50:69]; file_index{5} = valid_index(find(valid_index>=70,1):find(valid_index>=76,1)); %驾驶员5的index:...[70:76]; file_index{6} = valid_index(find(valid_index>=77,1):find(valid_index>=80,1)); %驾驶员6的index:...[77:80];
变量如下:

②根据类别索引,提取出该段数据的其他属性值,存储在其他的元胞数组中。
根据每个类比的索引元胞值,提取表格中对应类别的某个属性值,属性值也按照类别分类,结果存储在6个元胞中。
for j = 1:file_num episode_start_set{j} = rawdata(file_index{j},6); %提取路段起始点(类别:第i名驾驶员,属性:路段起始时间点);6表示rawdata第六列是原始数据的起始时间点 episode_end_set{j} = rawdata(file_index{j},8); %提取路段终点(类别:第i名驾驶员,属性:路段结束时间点) ; %提取路段起始点(类别:第i名驾驶员,属性:路段起始时间点) sen_ID_set{j} = rawdata(file_index{j},4); %提取场景ID dri_ID_set{j} = cell2mat(rawdata(file_index{j},3)); %提取驾驶员ID end
③载入已经解析出的所有属性,将路段各个属性均按类别进行划分提取并存储。
if dri_index == 1
load more_lc_dri1_file1.mat;
else
load more_lc_dri1_file2.mat;
end
for j = 1:length(file_index{dri_index}) %length(file_index{dri_index})是每个驾驶员对应的有效路段的个数
veh_start(j) = find(TimeSpeed>episode_start_set{dri_index,1}{j,1},1); %veh_start存的都是第几个时间点,而不是准确时刻,两个时间点之间时间间隔为0.045s
veh_end(j) = find(TimeSpeed>episode_end_set{dri_index,1}{j,1},1);
Time_set{dri_index,j} = TimeSpeed(veh_start(j):veh_end(j));
AccPedalPos_short{dri_index,j} = AccPedalPos(veh_start(j):veh_end(j));
...
end
load more_lc_dri1_file1.mat;
else
load more_lc_dri1_file2.mat;
end
for j = 1:length(file_index{dri_index}) %length(file_index{dri_index})是每个驾驶员对应的有效路段的个数
veh_start(j) = find(TimeSpeed>episode_start_set{dri_index,1}{j,1},1); %veh_start存的都是第几个时间点,而不是准确时刻,两个时间点之间时间间隔为0.045s
veh_end(j) = find(TimeSpeed>episode_end_set{dri_index,1}{j,1},1);
Time_set{dri_index,j} = TimeSpeed(veh_start(j):veh_end(j));
AccPedalPos_short{dri_index,j} = AccPedalPos(veh_start(j):veh_end(j));
...
end
④在已经分好类的基础上再进一步进行分类重组(但是带上原来类别的tag)
dri_ID存储为成以下的元胞数组内,每一行为一个驾驶员,每个驾驶员对应的路段场景为[1:10],[82,80,88,87,74,71]分别表示有对应个数的路段;每个路段归属于10种场景中的一种,对应的场景编号存储在每个元胞的数组中。
82x1 cell 80x1 cell 88x1 cell 87x1 cell 74x1 cell 71x1 cell
⑤按照另一分类标准进行分类,但将原来类别的分类ID存储在某个元胞数组中。
示例:将已经按照驾驶员分好类的路段,按照场景进行重组。按按场景分类后,每个路段对应的驾驶员编号和路段序号存储在sen1,sen2,...sen10中。
one = 1;two = 1;thr = 1;fou = 1;fiv = 1; six = 1;sev = 1;eig = 1;nin = 1;ten = 1; for m = 1:6 for j = 1:length(sen_ID_all{m}) if cell2mat(sen_ID_all{m}(j))==1 sen1{one} = [m,j]; one = one+1; elseif cell2mat(sen_ID_all{m}(j))==2 sen2{two} = [m,j]; two = two+1; elseif cell2mat(sen_ID_all{m}(j))==3 sen3{thr} = [m,j]; thr = thr+1; elseif cell2mat(sen_ID_all{m}(j))==4 sen4{fou} = [m,j]; fou = fou+1; elseif cell2mat(sen_ID_all{m}(j))==5 sen5{fiv} = [m,j]; fiv = fiv+1; elseif cell2mat(sen_ID_all{m}(j))==6 sen6{six} = [m,j]; six = six+1; elseif cell2mat(sen_ID_all{m}(j))==7 sen7{sev} = [m,j]; sev = sev+1; elseif cell2mat(sen_ID_all{m}(j))==8 sen8{eig} = [m,j]; eig = eig+1; elseif cell2mat(sen_ID_all{m}(j))==9 sen9{nin} = [m,j]; nin = nin+1; elseif cell2mat(sen_ID_all{m}(j))==10 sen10{ten} = [m,j]; ten = ten+1; end end end
⑥元胞数组的索引:
示例:senN{m}(1),{m}为提取第m个元胞,(1)为提取该元胞的第1个数值。
if s_index ==1 % 根据想要提取的场景类别,设置s_index。若想提取场景1的属性数据,则设置s_index=1 senN = sen1; elseif s_index ==2 senN = sen2; elseif s_index ==3 senN = sen3; elseif s_index ==4 senN = sen4; elseif s_index ==5 senN = sen5; elseif s_index ==6 senN = sen6; elseif s_index ==7 senN = sen7; elseif s_index ==8 senN = sen8; elseif s_index ==9 senN = sen9; elseif s_index ==10 senN = sen10; end for m = 1:length(senN) a = senN{m}(1); %表示第a个驾驶员,b表示第a个驾驶员的第b个路段 b = senN{m}(2); dri_ID_mat{s_index,m} = senN{m}(1); %dri_ID_mat记录按场景分类的换道路段对应的驾驶员编号 Time_set_sen{s_index,m} = Time_set_all(a,b); AccPedalPos_short_sen{s_index,m} = AccPedalPos_all(a,b); Ay_short_sen{s_index,m} = Ay_all(a,b) ; BrakePedalPos_short_sen{s_index,m} = BrakePedalPos_all(a,b); ... TTC_short_sen{s_index,m} = TTC_all(a,b); TurnLeftLight_short_sen{s_index,m} = TurnLeftLight_all(a,b); TurnRightLight_short_sen{s_index,m} = TurnRightLight_all(a,b); end
⑦元胞数组的拼接
for j = 1:88 %67+21=88,两个表格的数据个数分别为67和21 for i = 1:6 %有6个驾驶员(第一种类别) if j>=1 && j<=67 %第一个表格的数据赋值 if j>=1 && j<=67 load episodeall_lc_minus5_6dri_biao1.mat; Time_set_all{i,j} = Time_set{i,j}; 。。。 elseif j>=68 && j<=88 load episodeall_lc_6dri_moreplus.mat; Time_set_all{i,j} = Time_set{i,j-67}; 。。。 end end end % 将sen_ID_all 改为和特征一样的拼接形式 sen_ID_all = sen_ID_all1(:,1); dri_ID_all = dri_ID_all1(:,1); for j = 1:6 for i = 68:67+length(sen_ID_all1{j,2}) % for i = 31:30+length(sen_ID_set_all{j,2}) sen_ID_all{j,1}{i,1} = sen_ID_all1{j,2}{i-67,1}; dri_ID_all{j,1}(i,1) = dri_ID_all1{j,2}(i-67,1); % dri_ID_all{j,1}{i,1} = sen_ID_set_all{j,2}{i-30,1}; end end % 如果有第三张表; 改为 % % sen_ID_all = sen_ID_set_all(:,1); % 只取第一列的ID % % for j = 1:6 % % for i = 68:67+length(sen_ID_set_all{j,2}) % % sen_ID_all{j,1}{i,1} = sen_ID_set_all{j,2}{i-67,1}; % % end % % for i = xx+1:xx+length(sen_ID_set_all{j,3}) % % sen_ID_all{j,1}{i,1} = sen_ID_set_all{j,2}{i-xx,1}; % % end % % % %xx为第三张表中max{单个驾驶员的换道路段个数} % % end
2.从两个数组中提取出两者共有的数据
a=[1,2,5,6,8]; b=[3,5,8,9,10]; % 实现步骤: c=[a,b]; d=sort(c); for i = 1:length(d)-1 if d(i+1)==d(i) d(i)=0; end end e = d(find(d));