9.Spring体系结构和jar用途
参考https://blog.csdn.net/sunchen2012/article/details/53939253
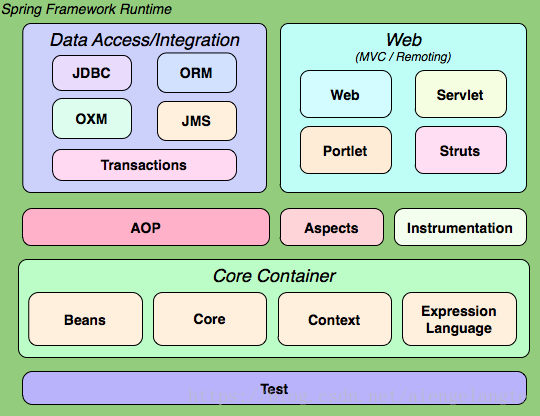
spring官网给出了一张spring3的结构图
图中将spring分为5个部分:core、aop、data access、web、test,图中每个圆角矩形都对应一个jar,如果在maven中配置,所有这些jar的“groupId”都是“org.springframework”,每个jar有一个不同的“artifactId”,另外,“instrumentation”有两个jar,还有一个“spring-context-support”图中没有列出,所以spring3的jar包一共是19个
下面介绍这5个部分的jar以及依赖关系
core
core部分包含4个模块
- spring-core:依赖注入IoC与DI的最基本实现
- spring-beans:Bean工厂与bean的装配
- spring-context:spring的context上下文即IoC容器
- spring-expression:spring表达式语言
它们的完整依赖关系

因为spring-core依赖了commons-logging,而其他模块都依赖了spring-core,所以整个spring框架都依赖了commons-logging,如果有自己的日志实现如log4j,可以排除对commons-logging的依赖,没有日志实现而排除了commons-logging依赖,编译报错
|
1 2 3 4 5 6 7 8 9 10 11 |
|
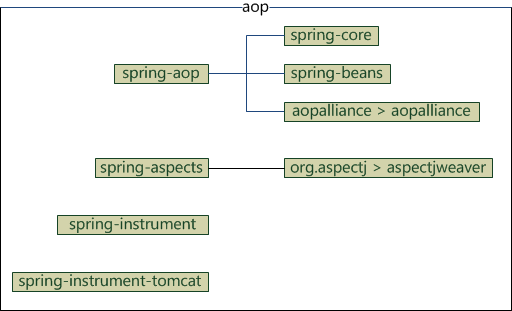
aop
aop部分包含4个模块
- spring-aop:面向切面编程
- spring-aspects:集成AspectJ
- spring-instrument:提供一些类级的工具支持和ClassLoader级的实现,用于服务器
- spring-instrument-tomcat:针对tomcat的instrument实现
它们的依赖关系
data access
data access部分包含5个模块
- spring-jdbc:jdbc的支持
- spring-tx:事务控制
- spring-orm:对象关系映射,集成orm框架
- spring-oxm:对象xml映射
- spring-jms:java消息服务
它们的依赖关系

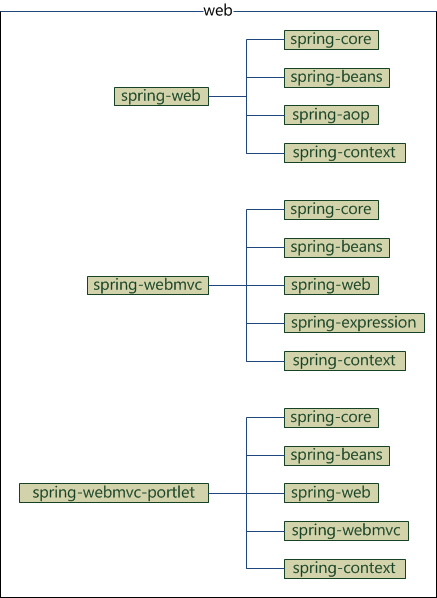
web
web部分包含4个模块
- spring-web:基础web功能,如文件上传
- spring-webmvc:mvc实现
- spring-webmvc-portlet:基于portlet的mvc实现
- spring-struts:与struts的集成,不推荐,spring4不再提供
它们的依赖关系
test
test部分只有一个模块,我将spring-context-support也放在这吧
- spring-test:spring测试,提供junit与mock测试功能
- spring-context-support:spring额外支持包,比如邮件服务、视图解析等
它们的依赖关系

到这里,spring3的介绍就完了,看着这些图我相信你在maven中配置spring依赖时不会再混乱了
下面介绍spring4,与spring3结构基本相同,下面是官网给出的结构图

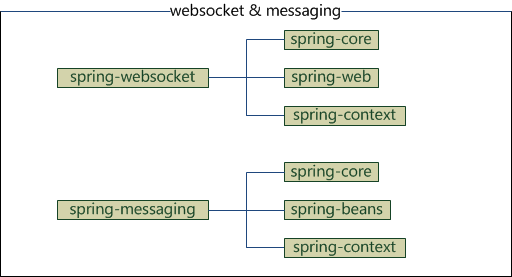
可以看到,图中去掉了spring3的struts,添加了messaging和websocket,其他模块保持不变,因此,spring4的jar有20个
- spring-websocket:为web应用提供的高效通信工具
- spring-messaging:用于构建基于消息的应用程序
它们的依赖关系
10.SpringMVC运行原理
一、SpringMVC运行原理图
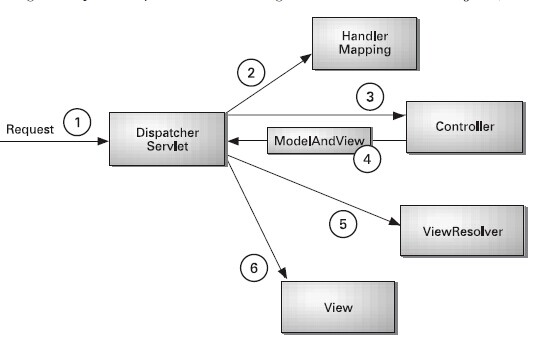
二、相关接口解释 DispatcherServlet接口: Spring提供的前端控制器,所有的请求都有经过它来统一分发。在DispatcherServlet将请求分发给Spring Controller之前,需要借助于Spring提供的HandlerMapping定位到具体的Controller。 HandlerMapping接口: 能够完成客户请求到Controller映射。 Controller接口: 需要为并发用户处理上述请求,因此实现Controller接口时,必须保证线程安全并且可重用。 Controller将处理用户请求,这和Struts Action扮演的角色是一致的。一旦Controller处理完用户请求,则返回ModelAndView对象给DispatcherServlet前端控制器,ModelAndView中包含了模型(Model)和视图(View)。 从宏观角度考虑,DispatcherServlet是整个Web应用的控制器;从微观考虑,Controller是单个Http请求处理过程中的控制器,而ModelAndView是Http请求过程中返回的模型(Model)和视图(View)。 ViewResolver接口: Spring提供的视图解析器(ViewResolver)在Web应用中查找View对象,从而将相应结果渲染给客户。
SpringMVC运行原理
1. 客户端请求提交到DispatcherServlet
2. 由DispatcherServlet控制器查询一个或多个HandlerMapping,找到处理请求的Controller
3. DispatcherServlet将请求提交到Controller
4. Controller调用业务逻辑处理后,返回ModelAndView
5. DispatcherServlet查询一个或多个ViewResoler视图解析器,找到ModelAndView指定的视图
6. 视图负责将结果显示到客户端 DispatcherServlet是整个Spring MVC的核心。它负责接收HTTP请求组织协调Spring MVC的各个组成部分。
其主要工作有以下三项:
1. 截获符合特定格式的URL请求。
2. 初始化DispatcherServlet上下文对应的WebApplicationContext,并将其与业务层、持久化层的WebApplicationContext建立关联。
3. 初始化Spring MVC的各个组成组件,并装配到DispatcherServlet中
11.SpringBoot的执行过程
参考https://www.jianshu.com/p/63ad69c480fe
https://blog.csdn.net/u010851067/article/details/81413392
什么是springboot
用来简化spring应用的初始搭建以及开发过程 使用特定的方式来进行配置(properties或yml文件)
创建独立的spring引用程序 main方法运行
嵌入的Tomcat 无需部署war文件
简化maven配置
自动配置spring添加对应功能
starter自动化配置
springboot常用的starter有哪些
spring-boot-starter-web 嵌入tomcat和web开发需要servlet与jsp支持
spring-boot-starter-data-jpa 数据库支持
spring-boot-starter-data-redis redis数据库支持
spring-boot-starter-data-solr solr支持
mybatis-spring-boot-starter 第三方的mybatis集成starter
springboot自动配置的原理
在spring程序main方法中 添加@SpringBootApplication或者@EnableAutoConfiguration会自动去maven中读取每个starter中的spring.factories文件 该文件里配置了spring容器中所有需要的bean
springboot读取配置文件的方式
springboot默认读取配置文件为application.properties或者是application.yml
springboot集成mybatis的过程
添加mybatis的starter maven依赖
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.2.0</version>
</dependency>
在mybatis的接口中 添加@Mapper注解
在application.yml配置数据源信息
SpringBoot集成热部署?
把依赖项添加至pom.xml 中
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
</dependency>
重启应用程序,然后就可以了
我们能否在 spring-boot-starter-web 中用 jetty 代替 tomcat?
在 spring-boot-starter-web 移除现有的依赖项,并把下面这些添加进去。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
</dependency>
RequestMapping 和 GetMapping 的不同之处在哪里?
- RequestMapping 具有类属性的,可以进行 GET,POST,PUT 或者其它的注释中具有的请求方法。
- GetMapping 是 GET 请求方法中的一个特例。它只是 ResquestMapping 的一个延伸,目的是为了提高清晰度
自定义属性与加载
自定义属性与加载
在application.properties文件中配置相关属性
com.didispace.blog.name=程序猿DD
com.didispace.blog.title=Spring Boot教程
创建一个文件读取的class类,使用component注释:(把普通pojo实例化到spring容器中)
@Component
public class BlogProperties {
@Value("${com.didispace.blog.name}")
//采用@Value("${前缀}")方式注入属性
private String name;
@Value("${com.didispace.blog.title}")
private String title;
// 省略getter和setter
}
多环境配置
我们在开发Spring Boot应用时,通常同一套程序会被安装到几个不同的环境,比如:开发、测试、生产等。对于多环境的配置,通过配置多份不同环境的配置文件,再通过打包命令配置不停的环境配置。
在Spring Boot中多环境配置文件名需要满足application-{profile}.properties的格式,其中{profile}对应你的环境标识,比如:
- application-dev.properties:开发环境
- application-test.properties:测试环境
- application-prod.properties:生产环境
至于哪个具体的配置文件会被加载,需要在application.properties文件中通过spring.profiles.active属性来设置,其值对应{profile}值。
如:spring.profiles.active=test就会加载application-test.properties配置文件内容
12.Spring的事务隔离级别

- DataSourceTransactionManager:适用于使用JDBC和iBatis进行数据持久化操作的情况,在定义时需要提供底层的数据源作为其属性,也就是 DataSource。
- HibernateTransactionManager:适用于使用Hibernate进行数据持久化操作的情况,与 HibernateTransactionManager 对应的是 SessionFactory。
- JpaTransactionManager:适用于使用JPA进行数据持久化操作的情况,与 JpaTransactionManager 对应的是 EntityManagerFactory。
Spring事务的本质其实就是数据库对事务的支持,没有数据库的事务支持,spring是无法提供事务功能的。对于纯JDBC操作数据库,想要用到事务,可以按照以下步骤进行:
- 获取连接 Connection con = DriverManager.getConnection()
- 开启事务con.setAutoCommit(true/false);
- 执行CRUD
- 提交事务/回滚事务 con.commit() / con.rollback();
- 关闭连接 conn.close();
使用Spring的事务管理功能后,我们可以不再写步骤 2 和 4 的代码,而是由Spirng 自动完成。 那么Spring是如何在我们书写的 CRUD 之前和之后开启事务和关闭事务的呢?解决这个问题,也就可以从整体上理解Spring的事务管理实现原理了。下面简单地介绍下,注解方式为例子
- 配置文件开启注解驱动,在相关的类和方法上通过注解@Transactional标识。
- spring 在启动的时候会去解析生成相关的bean,这时候会查看拥有相关注解的类和方法,并且为这些类和方法生成代理,并根据@Transaction的相关参数进行相关配置注入,这样就在代理中为我们把相关的事务处理掉了(开启正常提交事务,异常回滚事务)。
- 真正的数据库层的事务提交和回滚是通过binlog或者redo log实现的。
数据库隔离级别
| 隔离级别 | 隔离级别的值 | 导致的问题 |
| Read-Uncommitted | 0 | 导致脏读 |
| Read-Committed | 1 | 避免脏读,允许不可重复读和幻读 |
| Repeatable-Read | 2 | 避免脏读,不可重复读,允许幻读(可重复读) |
| Serializable | 3 | 串行化读,事务只能一个一个执行,避免了脏读、不可重复读、幻读。执行效率慢,使用时慎重 |
脏读:一事务对数据进行了增删改,但未提交,另一事务可以读取到未提交的数据。如果第一个事务这时候回滚了,那么第二个事务就读到了脏数据。
不可重复读:一个事务中发生了两次读操作,第一次读操作和第二次操作之间,另外一个事务对数据进行了修改,这时候两次读取的数据是不一致的。
幻读:第一个事务对一定范围的数据进行批量修改,第二个事务在这个范围增加一条数据,这时候第一个事务就会丢失对新增数据的修改。
Spring中的隔离级别
| 常量 | 解释 |
| ISOLATION_DEFAULT | 这是个 PlatfromTransactionManager 默认的隔离级别,使用数据库默认的事务隔离级别。另外四个与 JDBC 的隔离级别相对应。 |
| ISOLATION_READ_UNCOMMITTED | 这是事务最低的隔离级别,它充许另外一个事务可以看到这个事务未提交的数据。这种隔离级别会产生脏读,不可重复读和幻像读。 |
| ISOLATION_READ_COMMITTED | 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据。 |
| ISOLATION_REPEATABLE_READ | 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。 |
| ISOLATION_SERIALIZABLE | 这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。 |
13.Spring框架IOC和AOP的实现原理
参考https://www.cnblogs.com/zedosu/p/6709921.html
13.Springboot优势劣势,适用场景
SpringBoot核心功能
1、独立运行Spring项目
Spring boot 可以以jar包形式独立运行,运行一个Spring Boot项目只需要通过java -jar xx.jar来运行。
2、内嵌servlet容器
Spring Boot可以选择内嵌Tomcat、jetty或者Undertow,这样我们无须以war包形式部署项目。
3、提供starter简化Maven配置
spring提供了一系列的start pom来简化Maven的依赖加载,例如,当你使用了spring-boot-starter-web,会自动加入如图5-1所示的依赖包。
4、自动装配Spring
SpringBoot会根据在类路径中的jar包,类、为jar包里面的类自动配置Bean,这样会极大地减少我们要使用的配置。当然,SpringBoot只考虑大多数的开发场景,并不是所有的场景,若在实际开发中我们需要配置Bean,而SpringBoot没有提供支持,则可以自定义自动配置。
5、准生产的应用监控
SpringBoot提供基于http ssh telnet对运行时的项目进行监控。
6、无代码生产和xml配置
SpringBoot不是借助与代码生成来实现的,而是通过条件注解来实现的,这是Spring4.x提供的新特性。
SpringBoot优缺点
优点:
1、快速构建项目。
2、对主流开发框架的无配置集成。
3、项目可独立运行,无须外部依赖Servlet容器。
4、提供运行时的应用监控。
5、极大的提高了开发、部署效率。
6、与云计算的天然集成。
缺点:
将现有或传统的Spring Framework项目转换为Spring Boot应用程序是一个非常困难和耗时的过程。它仅适用于全新Spring项目。
19.常用的线程池模式以及适用场景
newCachedThreadPool:
- 底层:返回ThreadPoolExecutor实例,corePoolSize为0;maximumPoolSize为Integer.MAX_VALUE;keepAliveTime为60L;unit为TimeUnit.SECONDS;workQueue为SynchronousQueue(同步队列)
- 通俗:当有新任务到来,则插入到SynchronousQueue中,由于SynchronousQueue是同步队列,因此会在池中寻找可用线程来执行,若有可以线程则执行,若没有可用线程则创建一个线程来执行该任务;若池中线程空闲时间超过指定大小,则该线程会被销毁。
- 适用:执行很多短期异步的小程序或者负载较轻的服务器
newFixedThreadPool:
- 底层:返回ThreadPoolExecutor实例,接收参数为所设定线程数量nThread,corePoolSize为nThread,maximumPoolSize为nThread;keepAliveTime为0L(不限时);unit为:TimeUnit.MILLISECONDS;WorkQueue为:new LinkedBlockingQueue<Runnable>() 无解阻塞队列
- 通俗:创建可容纳固定数量线程的池子,每隔线程的存活时间是无限的,当池子满了就不在添加线程了;如果池中的所有线程均在繁忙状态,对于新任务会进入阻塞队列中(无界的阻塞队列)
- 适用:执行长期的任务,性能好很多
newSingleThreadExecutor:
- 底层:FinalizableDelegatedExecutorService包装的ThreadPoolExecutor实例,corePoolSize为1;maximumPoolSize为1;keepAliveTime为0L;unit为:TimeUnit.MILLISECONDS;workQueue为:new LinkedBlockingQueue<Runnable>() 无解阻塞队列
- 通俗:创建只有一个线程的线程池,且线程的存活时间是无限的;当该线程正繁忙时,对于新任务会进入阻塞队列中(无界的阻塞队列)
- 适用:一个任务一个任务执行的场景
NewScheduledThreadPool:
- 底层:创建ScheduledThreadPoolExecutor实例,corePoolSize为传递来的参数,maximumPoolSize为Integer.MAX_VALUE;keepAliveTime为0;unit为:TimeUnit.NANOSECONDS;workQueue为:new DelayedWorkQueue() 一个按超时时间升序排序的队列
- 通俗:创建一个固定大小的线程池,线程池内线程存活时间无限制,线程池可以支持定时及周期性任务执行,如果所有线程均处于繁忙状态,对于新任务会进入DelayedWorkQueue队列中,这是一种按照超时时间排序的队列结构
- 适用:周期性执行任务的场景
线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。 说明:Executors各个方法的弊端:
1)newFixedThreadPool和newSingleThreadExecutor:
主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
2)newCachedThreadPool和newScheduledThreadPool:
主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
20.ReentrantLock和synchronized的区别
参考https://www.cnblogs.com/fanguangdexiaoyuer/p/5313653.html
基本概念
1、ReentrantLock 拥有Synchronized相同的并发性和内存语义,此外还多了 锁投票,定时锁等候和中断锁等候
线程A和B都要获取对象O的锁定,假设A获取了对象O锁,B将等待A释放对O的锁定,
如果使用 synchronized ,如果A不释放,B将一直等下去,不能被中断
如果 使用ReentrantLock,如果A不释放,可以使B在等待了足够长的时间以后,中断等待,而干别的事情
ReentrantLock获取锁定与三种方式:
a) lock(), 如果获取了锁立即返回,如果别的线程持有锁,当前线程则一直处于休眠状态,直到获取锁
b) tryLock(), 如果获取了锁立即返回true,如果别的线程正持有锁,立即返回false;
c)tryLock(long timeout,TimeUnit unit), 如果获取了锁定立即返回true,如果别的线程正持有锁,会等待参数给定的时间,在等待的过程中,如果获取了锁定,就返回true,如果等待超时,返回false;
d) lockInterruptibly:如果获取了锁定立即返回,如果没有获取锁定,当前线程处于休眠状态,直到或者锁定,或者当前线程被别的线程中断
2、synchronized是在JVM层面上实现的,不但可以通过一些监控工具监控synchronized的锁定,而且在代码执行时出现异常,JVM会自动释放锁定,但是使用Lock则不行,lock是通过代码实现的,要保证锁定一定会被释放,就必须将unLock()放到finally{}中
3、在资源竞争不是很激烈的情况下,Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态;
下面内容 是转载 http://zzhonghe.iteye.com/blog/826162
5.0的多线程任务包对于同步的性能方面有了很大的改进,在原有synchronized关键字的基础上,又增加了ReentrantLock,以及各种Atomic类。了解其性能的优劣程度,有助与我们在特定的情形下做出正确的选择。
总体的结论先摆出来:
synchronized:
在资源竞争不是很激烈的情况下,偶尔会有同步的情形下,synchronized是很合适的。原因在于,编译程序通常会尽可能的进行优化synchronize,另外可读性非常好,不管用没用过5.0多线程包的程序员都能理解。
ReentrantLock:
ReentrantLock提供了多样化的同步,比如有时间限制的同步,可以被Interrupt的同步(synchronized的同步是不能Interrupt的)等。在资源竞争不激烈的情形下,性能稍微比synchronized差点点。但是当同步非常激烈的时候,synchronized的性能一下子能下降好几十倍。而ReentrantLock确还能维持常态。
Atomic:
和上面的类似,不激烈情况下,性能比synchronized略逊,而激烈的时候,也能维持常态。激烈的时候,Atomic的性能会优于ReentrantLock一倍左右。但是其有一个缺点,就是只能同步一个值,一段代码中只能出现一个Atomic的变量,多于一个同步无效。因为他不能在多个Atomic之间同步。
所以,我们写同步的时候,优先考虑synchronized,如果有特殊需要,再进一步优化。ReentrantLock和Atomic如果用的不好,不仅不能提高性能,还可能带来灾难。
补充两者唤醒线程方式+线程切换
只要线程可以在30到50次自旋里拿到锁,那么Synchronized就不会升级为重量级锁,而等待的线程也就不用被挂起,我们也就少了挂起和唤醒这个上下文切换的过程开销.
但如果是ReentrantLock呢?不会自旋,而是直接被挂起,这样一来,我们就很容易会多出线程上下文开销的代价.当然,你也可以使用tryLock(),但是这样又出现了一个问题,你怎么知道tryLock的时间呢?在时间范围里还好,假如超过了呢?
所以,在锁被细化到如此程度上,使用Synchronized是最好的选择了.这里再补充一句,Synchronized和ReentrantLock他们的开销差距是在释放锁时唤醒线程的数量,Synchronized是唤醒锁池里所有的线程+刚好来访问的线程,而ReentrantLock则是当前线程后进来的第一个线程+刚好来访问的线程.
如果是线程并发量不大的情况下,那么Synchronized因为自旋锁,偏向锁,轻量级锁的原因,不用将等待线程挂起,偏向锁甚至不用自旋,所以在这种情况下要比ReentrantLock高效。