我们在前面的学习中都知道,如果把1-10以内的元素追加到一个新的列表表中,如果使用for循环我们可以这么做:
a = []
for i in range(1,11):
a.append(i)
print(a)
输出结果如下:
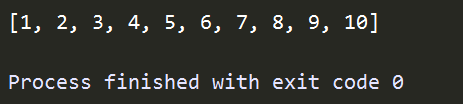
如果我们换成列表解析式来进行操作会是什么样呢?接下来我们换成列表解析式,如下所示:
b = [a for a in range(1,11)]
print(b)
输出结果如下:

同样的实现效果,那么到底哪种方式的效率更快呢?继续分析,为了看执行效率,我们引入time模块,来实际看一下两种方式执行效率的差异:
我们首先看一下for循环执行的效率:
import time
a = []
t0=time.clock() #获取当前时间
for i in range(1,20000):
a.append(i)
print('for循环消耗的时间是:{a}'.format(a=time.clock()-t0))
输出结果如下:

然后我继续看一下列表解析式的执行效率:
t0=time.clock()
b = [i for i in range(1,20000)]
print("列表推导式消耗的时间:{}".format(time.clock()-t0))
输出结果如下:

总结对比:

当然,两种方法运用好了,对我们后面的实际工作中都是有很大帮助的,列表推导式和for循环的应用场景不相同,本篇只是给大家分享两者在处理程序上的效率差异性。不喜勿喷哈!