(1)为什么学习node?


服务器为中间件
学习node.js便是为了帮助前端开发人员 打开服务器的黑盒子,了解接口制作、数据处理等,以便更好地配合后端进行协同开发
案例:node.js中文社区系统(多人社区)
(2)什么是node?
前端:HTML、CSS、JS
服务器端:node、java、PHP、Python、Ruby(案例:GitHub)、c#、.Net(dot点,发音为dao net)... ...都可以作为服务器端语言,都可以打开web后台服务器黑盒子。
node.js主要使用js编码

浏览器JS构成:

node.js中构成(服务端不处理页面,所以没有BOM和DOM)


node.js特性:
event-driven事件驱动、non-blocking I/O model非阻塞I/O模型
node.js生态库

小结:
node.js不是新语言、框架、库等,而是js在服务器端的运行环境。是基于Chrome的V8 JavaScript引擎构建的JavaScript运行时环境,浏览器引擎相关参考下面所示


(3)node介绍
1、node能做什么?

 等等,主要为服务器和命令行工具
等等,主要为服务器和命令行工具
对于前端来说,主要使用node命令行工具

2、预备知识

3、学习资源

4、学习知识点

B/S编程模型:Browser与Server

模块化编程

异步编程

ES6

(4)node环境安装

1、 查看当前是否安装node或者已经安装好的版本号
node --version或者node -v

2、官网查看版本进行下载
LTS为Long Time Support长期支持版,即稳定版
Current为当前最新版


3、安装
注意:已经安装过的,再次安装会进行覆盖
一路next傻瓜式安装即可
4、验证版本,确认是否安装成功
5、配置环境变量

(5)使用node执行JS脚本文件
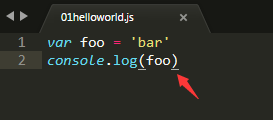
1、新建helloworld.js脚本
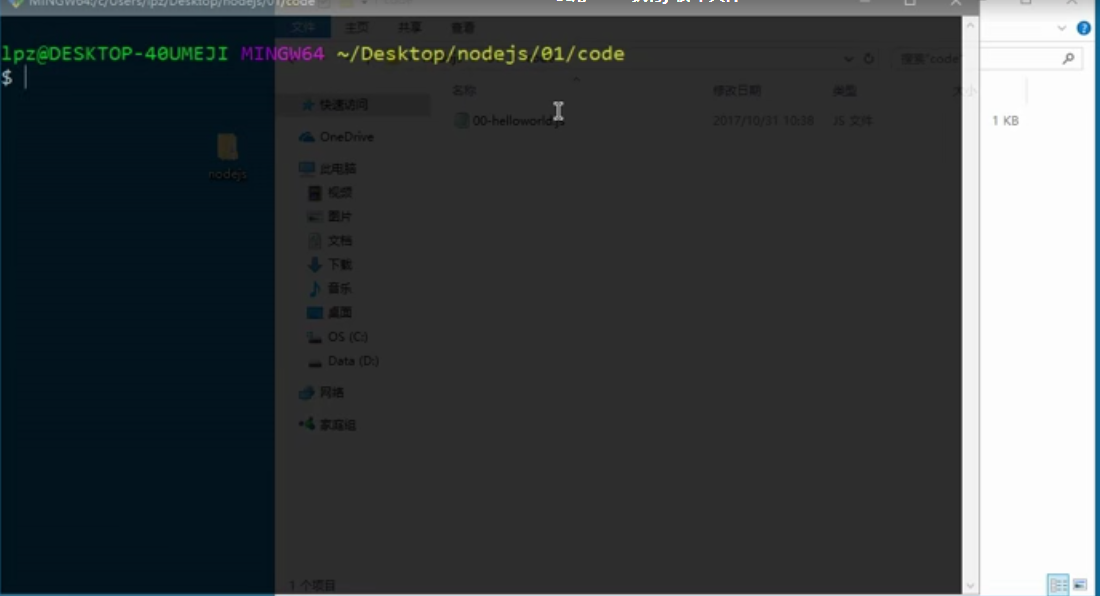
2、切换到脚本目录文件
CMD与Git Bash都可以

3、node执行脚本文件
如上所示
4、注意

脚本文件命名避免node.js或者中文
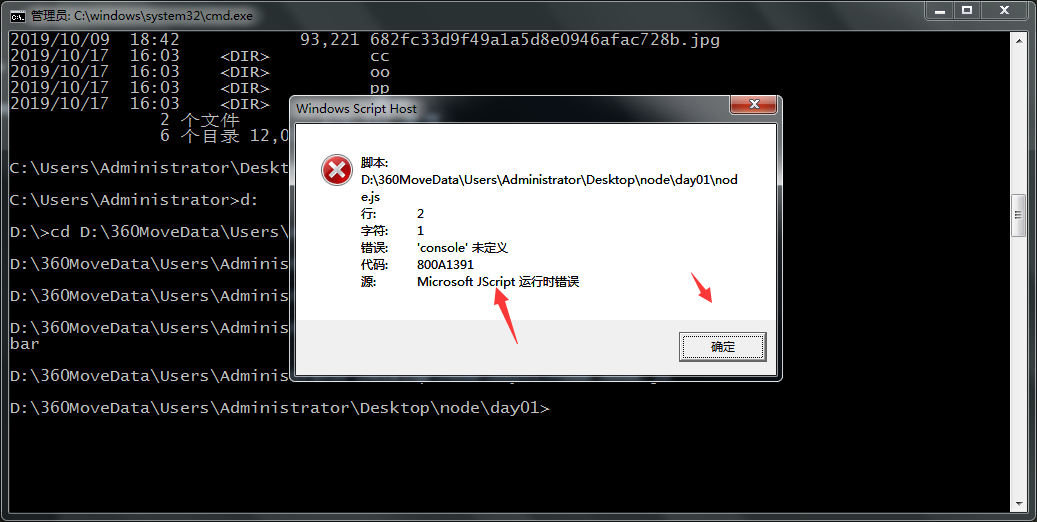
5、没有BOM与DOM验证
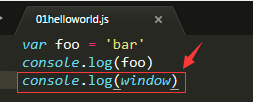


没有DOM与BOM操作,主要是服务器级别操作,例如读写文件
注意:浏览器中JS无法直接读取或者创建写入文件
6、浏览器js与node的js宏观对比---结合读写文件

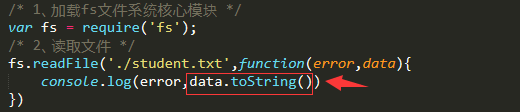
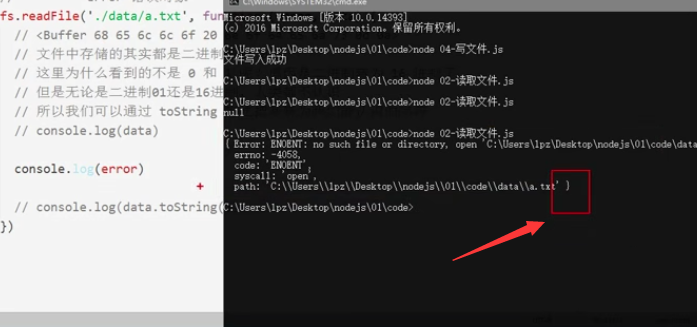
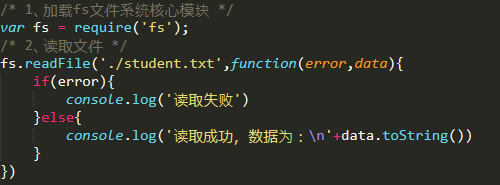
1、使用require方法加载fs(file-system文件系统)核心模块 var fs = require('fs'); 2、读取文件 fs.readFile('读取文件路径','回调函数(error,data)')
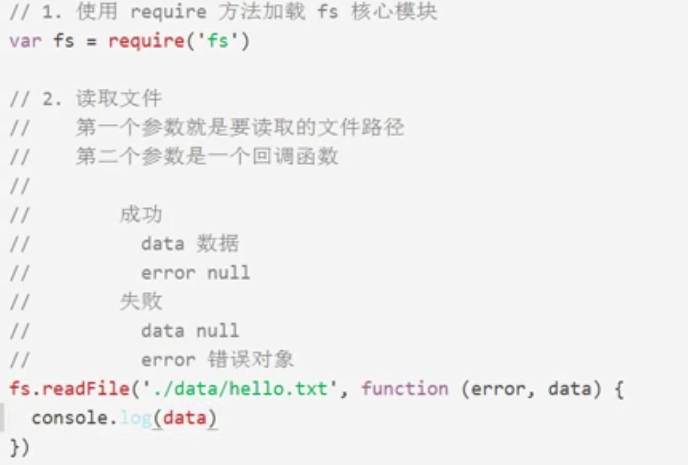
案例如下:
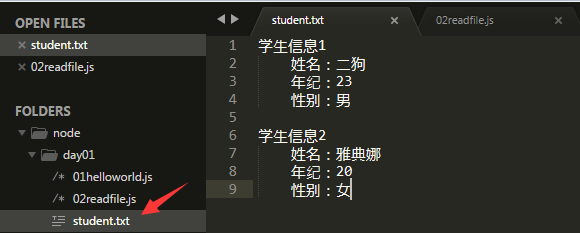


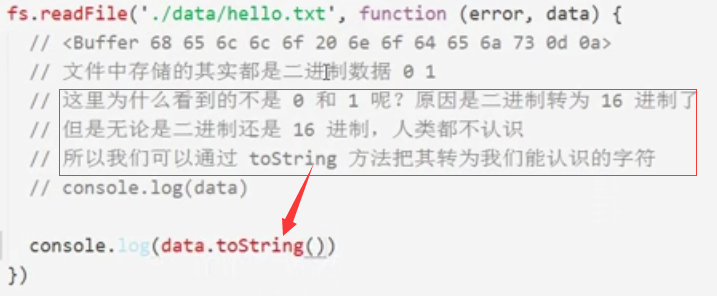
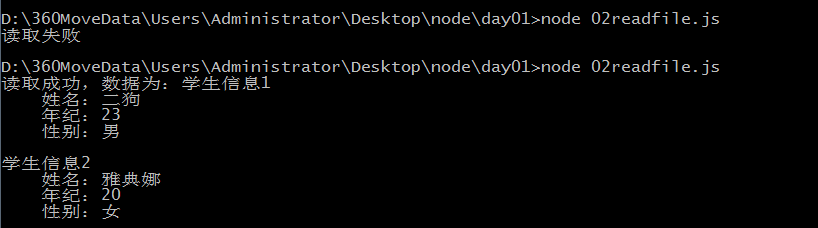
默认存储为二进制数据,这里看到的之所以乱码,是因为二进制转为16进制了,通过toString转换即可

小结:
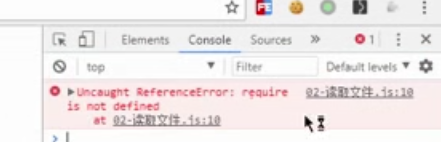
7、浏览器不认识node代码

(6)写文件和简单的错误处理
1、写文件API
writeFile()


案例如下:


2、完善--错误情况处理,自定义错误提示
错误时error为错误对象,包含具体错误信息
添加错误判断
3、写入文件加错误处理

4、小结
error参数作用:判断读写文件操作是否成功
(7)简单的http服务

之前首先利用node执行脚本文件,打印hello world;后来利用fs与API读写文件,接下来使用web服务器实现
核心模块:fs文件系统模块、http服务器模块
1、核心模块(宏观了解)
1、加载http核心模块 var http = require('http'); 2、创建web服务器 使用http.createServer()方法创建一个web服务器,返回一个server实例 var server = http.createServer() 3、服务器提供“数据”服务,接收请求
server.on('request',function(){...})
4、绑定端口号(3000、5000、8000,端口号下面介绍),启动服务器

验证如下:
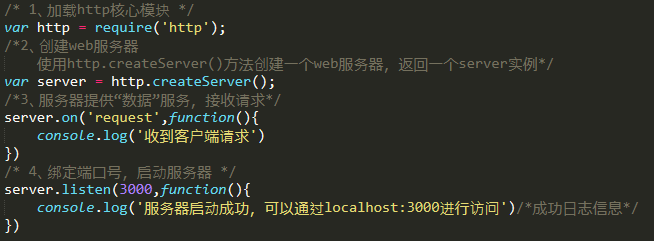


问题:此时浏览器输入url后一直显示等待响应... ....
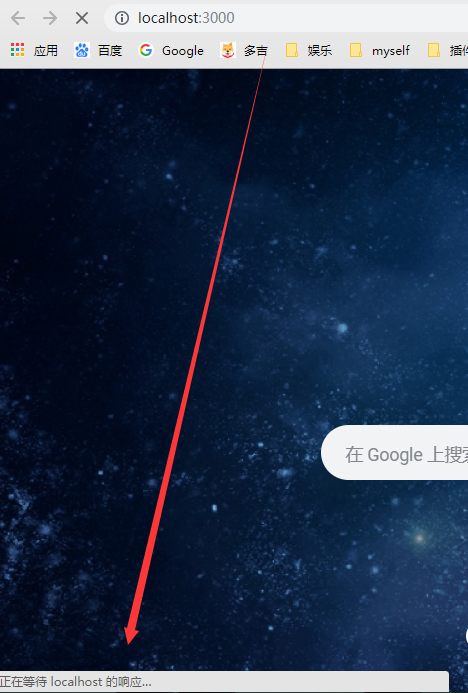
之所以会这样,主要因为当前只是接受请求request,还没有设置响应,所以接下来设置响应
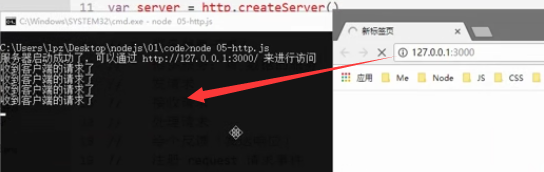
(8)设置并发送响应
1、参数
request请求事件回调处理函数,需要接受两个参数:
Request请求对象(获取客户端一些请求信息,例如请求路径request.url)
Response响应对象(给客户端发送响应消息)

2、验证如下
/* 1、加载http核心模块 */ var http = require('http'); /*2、创建web服务器 使用http.createServer()方法创建一个web服务器,返回一个server实例*/ var server = http.createServer(); /*3、服务器提供“数据”服务,接收请求*/ /* request请求事件回调处理函数,需要接受两个参数: Request请求对象(获取客户端一些请求信息,例如请求路径) Response响应对象(给客户端发送响应消息) */ server.on('request',function(request,response){ console.log('收到客户端请求,请求路径为'+request.url) /* response对象有一个write方法,可以用来给客户端发送响应数据 write可以使用多次,但最后要用end结束响应,否则客户端会一直等待 */ //往response响应流中写数据 response.write('hello world') //告知客户端,服务器的话已经说完了,可以呈递给用户了 response.end(); }) /* 4、绑定端口号,启动服务器 */ server.listen(3000,function(){ console.log('服务器启动成功,可以通过localhost:3000进行访问')/*成功日志信息*/ })

注意:/favicon.icon为收藏夹图标,浏览器有个默认行为,会去请求收藏夹图标
3、思考:路由

根据不同请求路径,响应不同内容... ...
简单复习:

(9)根据不同请求路径返回不同数据

1、启动服务器基本步骤
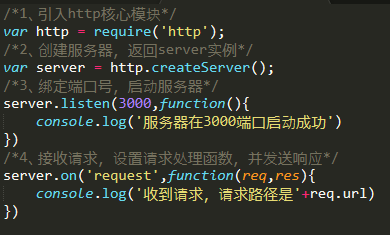
2、端口不能重复使用
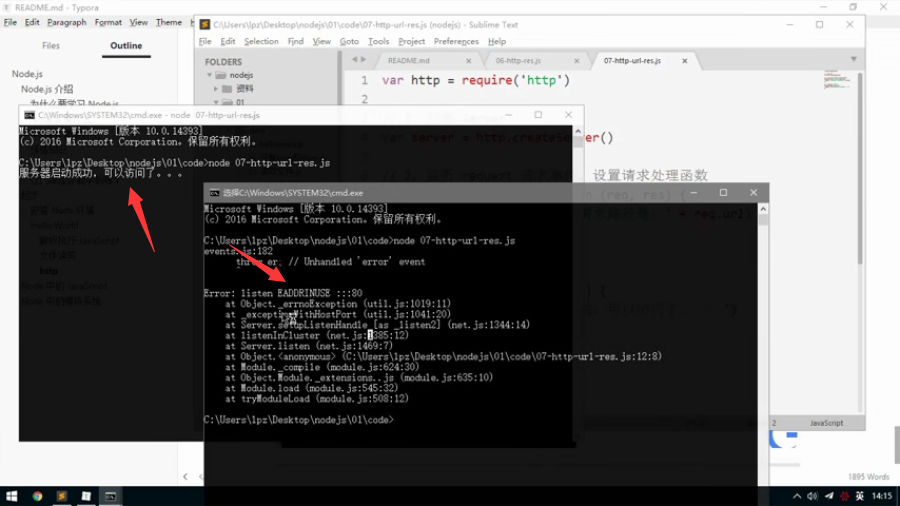
端口号如果已经被占用,则会启动失败
浏览器默认端口为80端口
3、默认端口号80验证
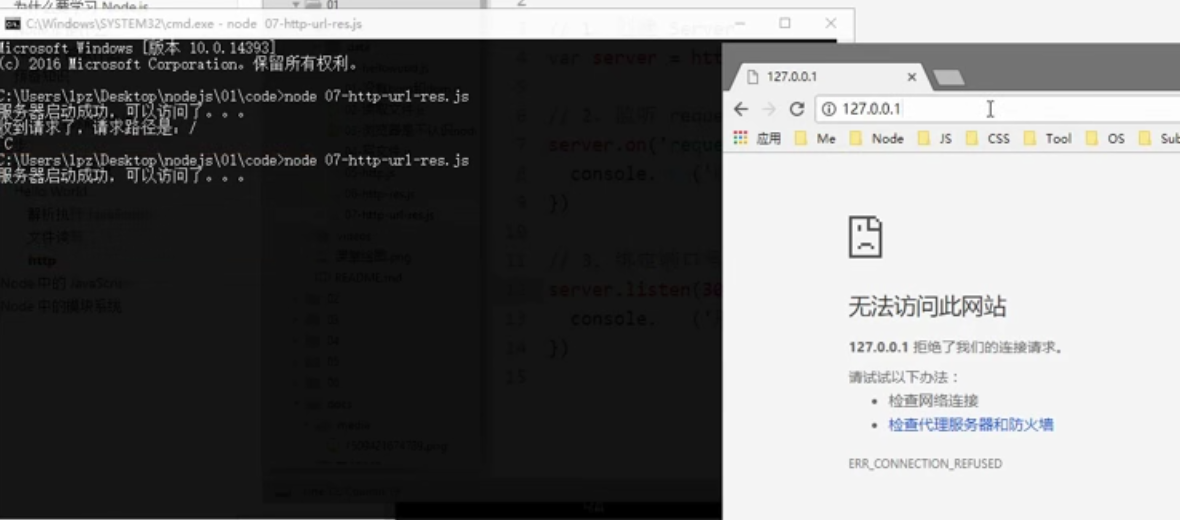
如果端口号是80,则输入url时只输入localhost或者127.0.0.1也可以访问
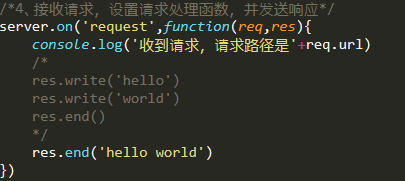
4、响应编写与结束简写
发送响应数据同时,结束响应
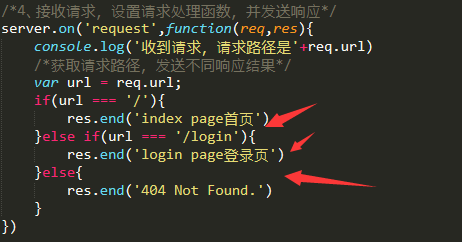
5、根据不同请求路径,发送不同结果
判断分析:所有请求路径以/开头
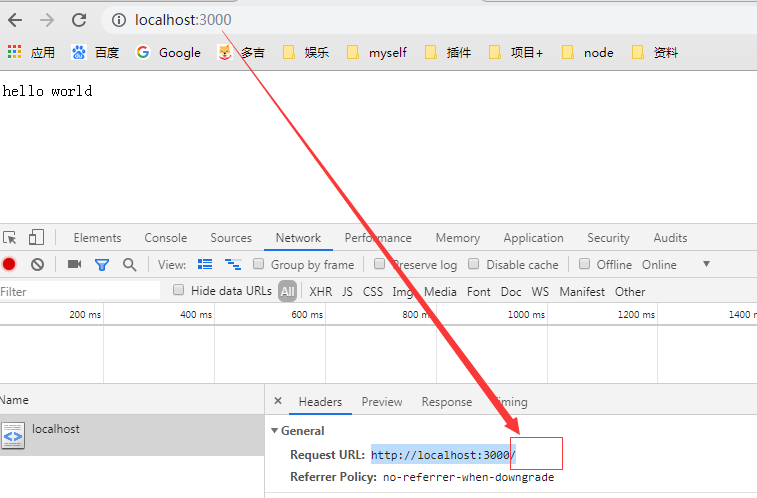
浏览器默认行为:访问网页图标
6、商品接口模拟
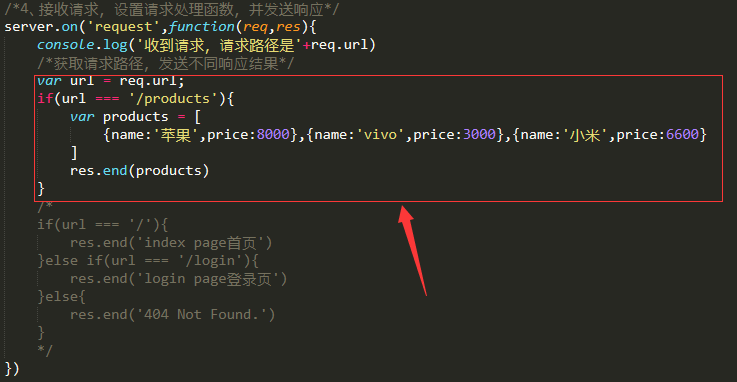
注意:编写好商品数据后,无法直接编写响应数据返回给客户端,需要注意数据类型
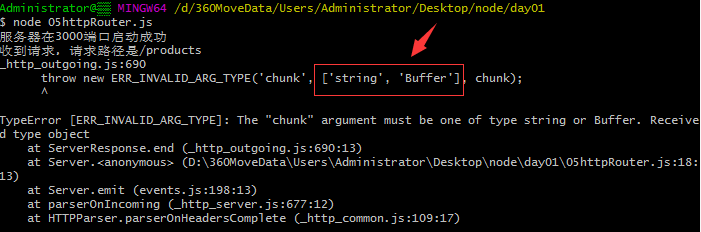
验证后发现只能接收字符串和二进制数据,即响应内容数据类型限制。

结果:

验证后发现和之前所接触的接口十分相似,简单了解下... ...,这里中文乱码,后续介绍,当然开发时数据都是存储在数据库
(10)Node.js中的js---核心模块
1、node中JS支持ES,没有BOM与DOM
2、核心模块
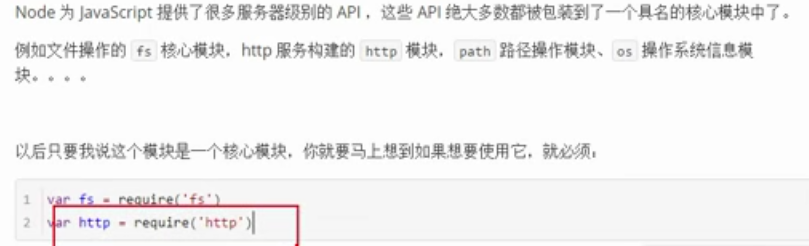
例如:
fs(file system)文件系统模块
os(operation system)操作系统信息模块
http服务构建模块
path路径操作模块
os案例:
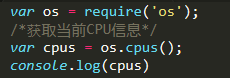
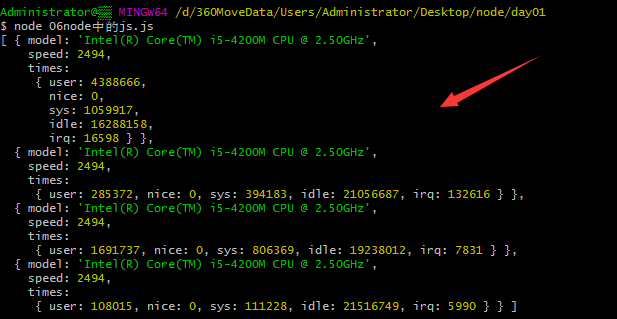
上面四个对象为四核
3、获取内存totalmem
/*获取内存大小,memory内存,单位为字节*/ var totalmem = os.totalmem(); console.log(totalmem)

4、path模块处理路径,获取扩展名extname
var path = require('path'); /*获取扩展名:extension name*/ var extname = path.extname('c:/user/myblog.txt'); console.log(extname)

5、多脚本文件并发执行
普通编写的话:node下同一时间只能读取操作一个脚本文件,如下所示
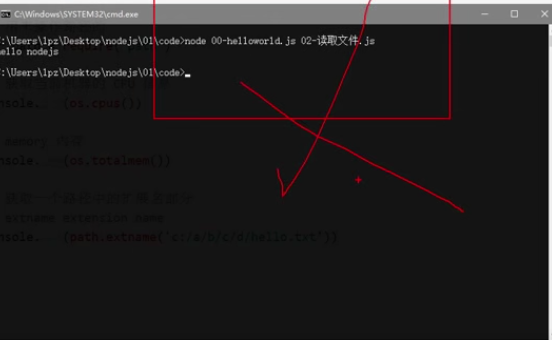
如果想同时执行多个脚本,需要模块化编程
6、模块化编程
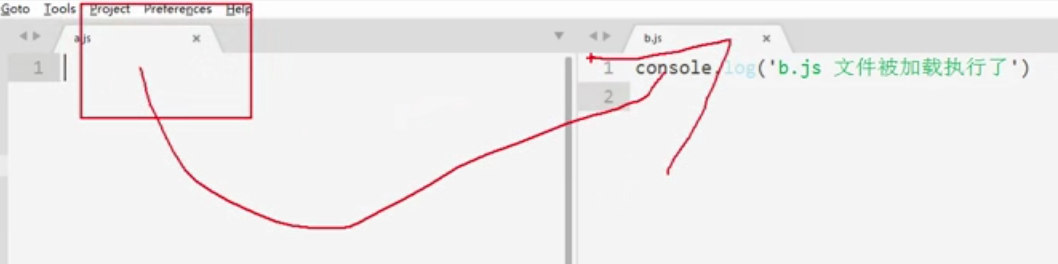
正如之前验证,两个脚本无法同时执行,所以只能通过代码,在执行a.js同时执行脚本文件b.js
node里,可以通过require加载的模块有3种 1、具名核心模块fs、http、path、os 2、用户自定义的模块(相对路径必须加./) 3、
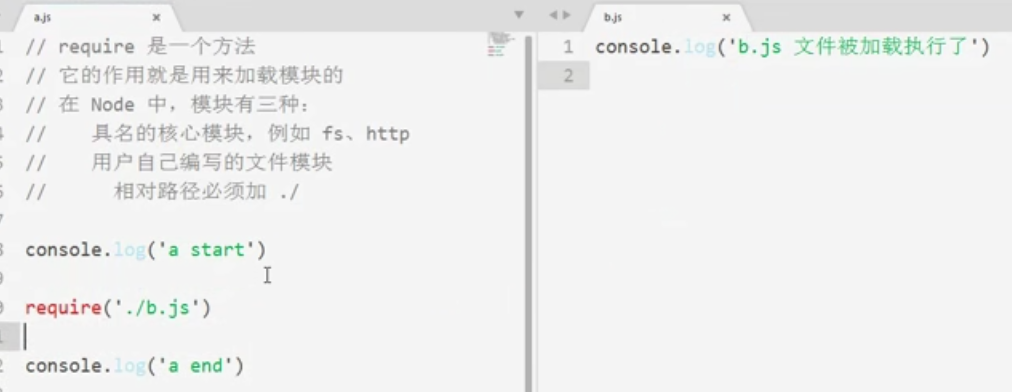
验证如下:
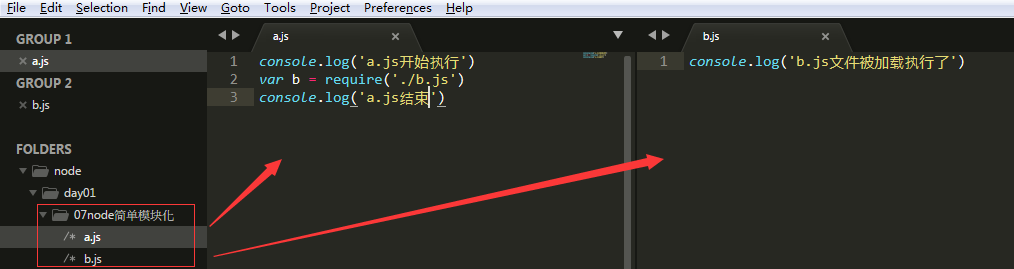

同理,再添加个c.js

验证如下

先进后出,后进先出
7、模块作用域
在node里,没有全局作用域,只有模块作用域,外部访问不到内部,内部也访问不到外部
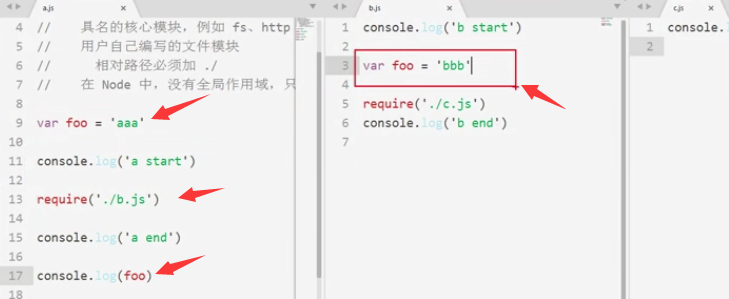
验证如下:
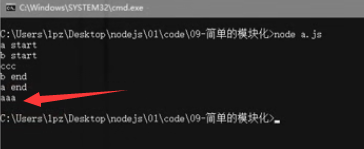
小结:

注意: 1、后缀名可以省略
2、相对路径的./不能省略,否则会报错(去掉会将其作为核心模块与识别解析)
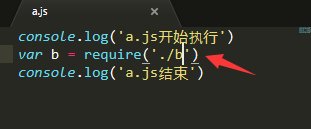
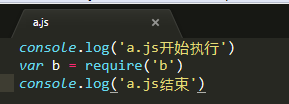
8、模块通信

9、模块的导入加载与导出
首先测试下直接读取别的模块信息

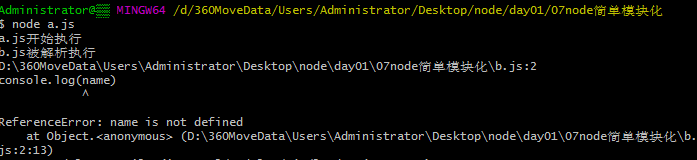
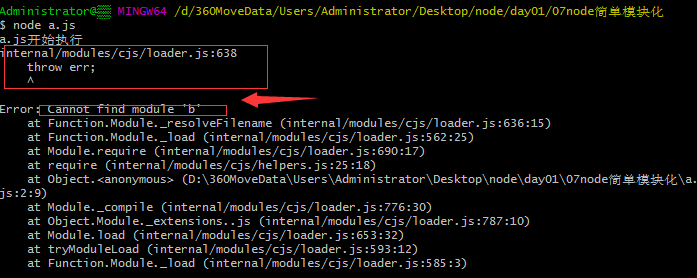
读取失败
接下来试下模块化信息操作,即模块导入与导出

每个文件模块都提供了一个对象:exports,默认exports是一个空对象
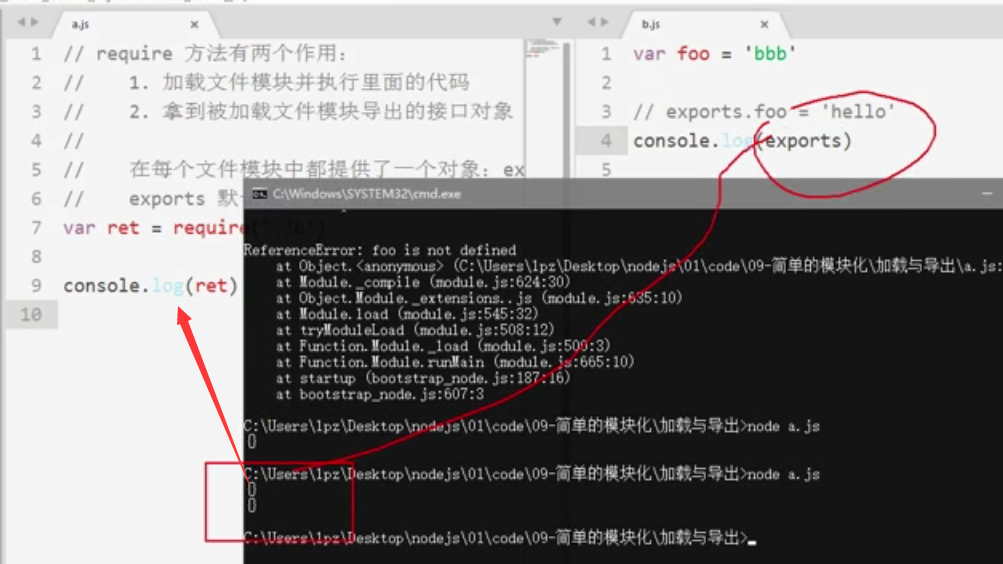
对象是动态的,所以如果想在其他模块使用该模块的数据,需要将其挂载到exports对象上,即动态添加成员
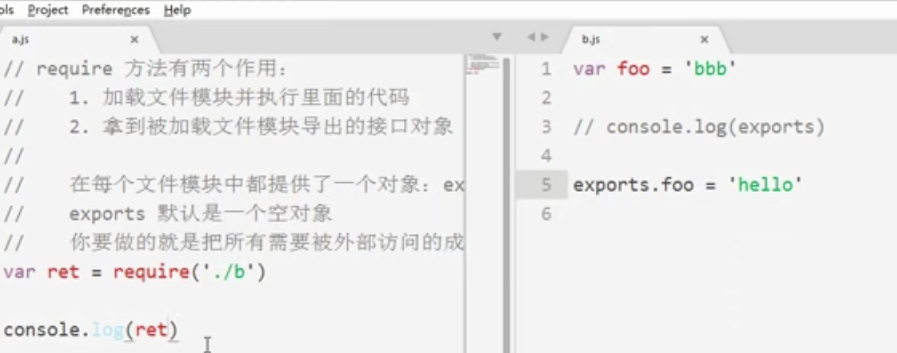
此时结果为{foo:hello}

也可以导出方法


思考:
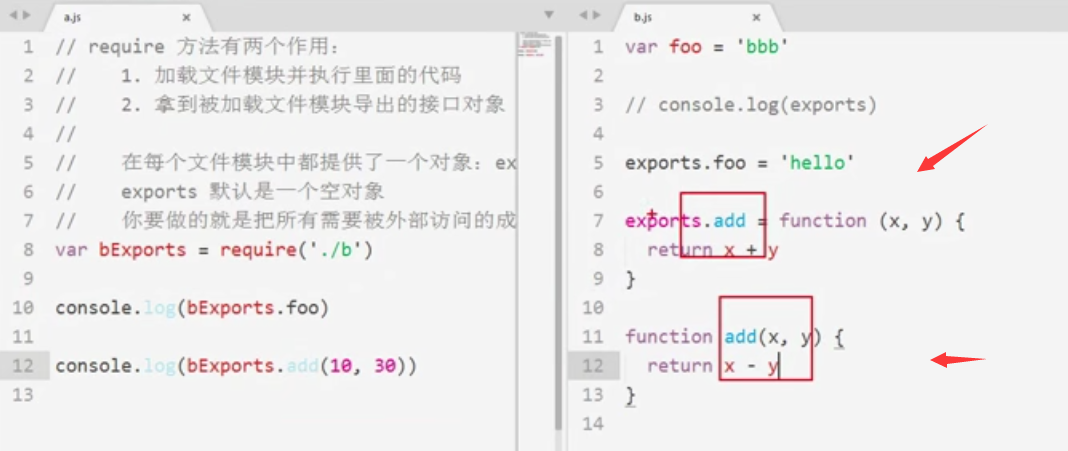
这里的两个add并不一样,一个是模块里的函数,另一个是挂载到exports对象上的方法
注意:只要是没有挂载到exports对象上的数据或方法,在另一个模块里都获取不到
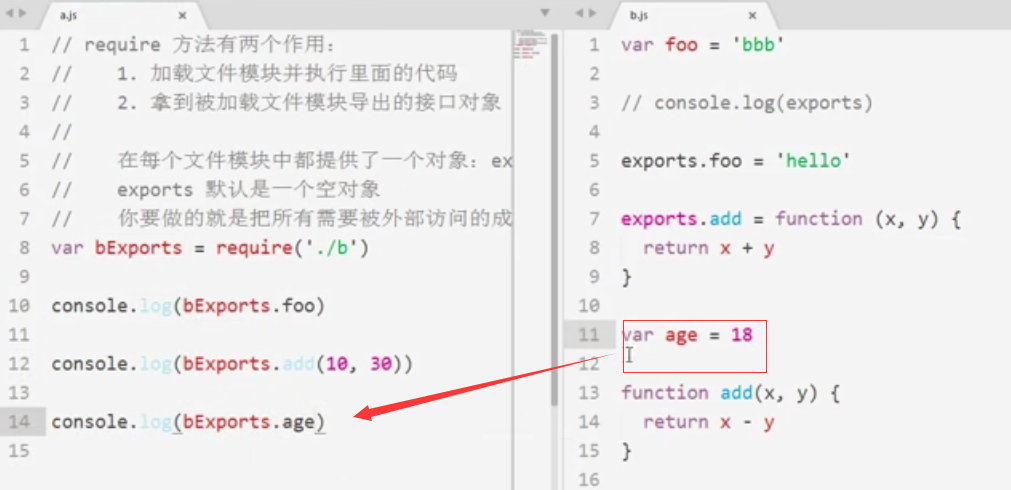

修改如下:

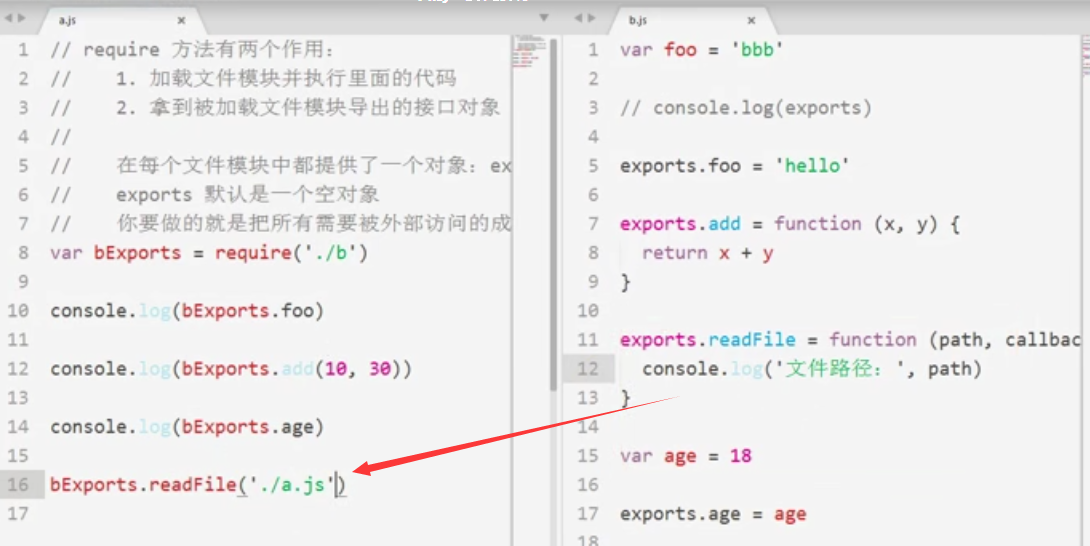
10、模拟核心模块封装
(11)ip地址&&端口号介绍
1、ip与端口号
ip用来定位计算机
端口号用来定位应用程序
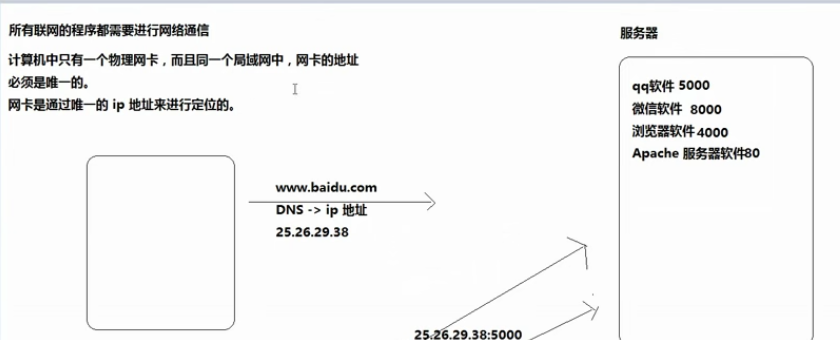
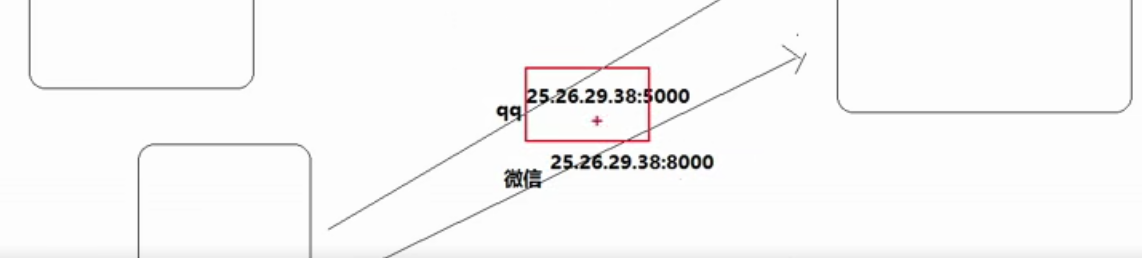
小结:


2、端口号补充

范围:0-65535
网站上线部署时用80默认端口即可
开发阶段推荐用3000、5000没有实际含义的端口号即可
(12)响应内容类型Content-type
1、中文乱码问题
首先编写http服务模块基本框架
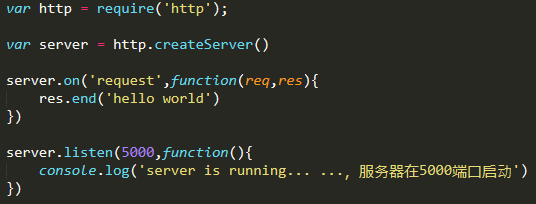
可以同时开启多个服务,但要确保不同服务占用不同的端口号

加上中文,再次验证如下
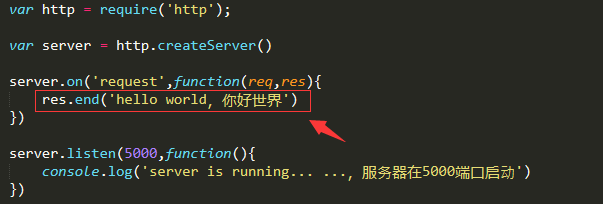

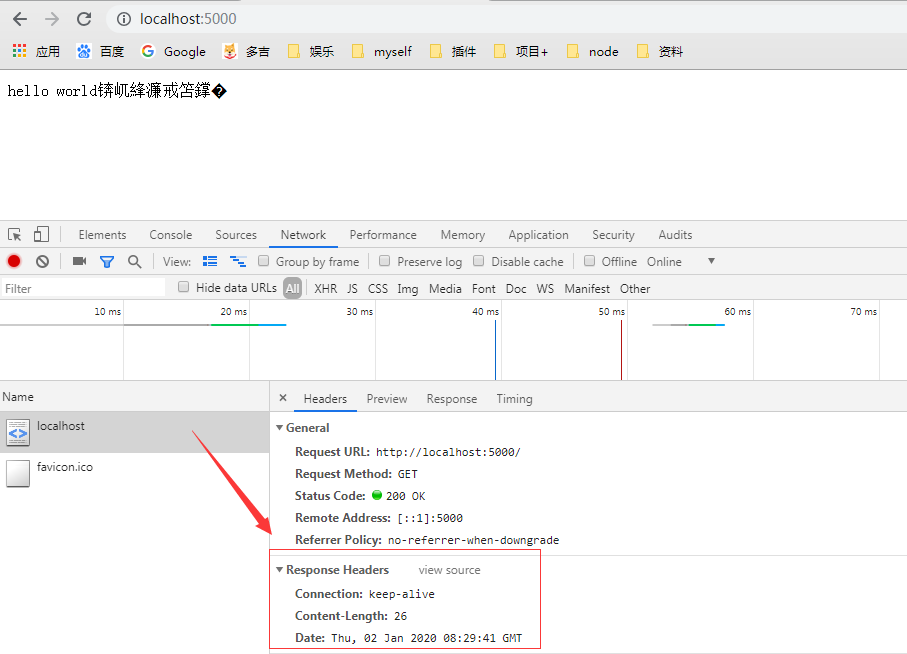
乱码原因剖析:之所以乱码,是因为服务器发送的数据为utf-8编码即国标编码,但浏览器不知道。
浏览器在不知道服务器响应内容的编码情况下,会按照当前系统的默认编码去解析(中文操作系统默认gbk编码)
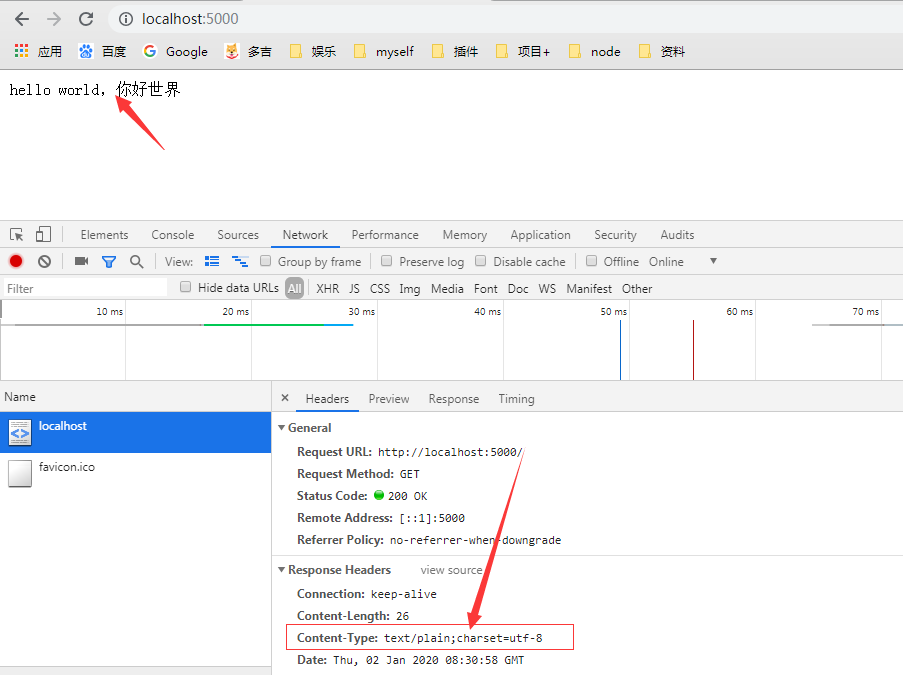
2、解决方法,声明编码协议类型
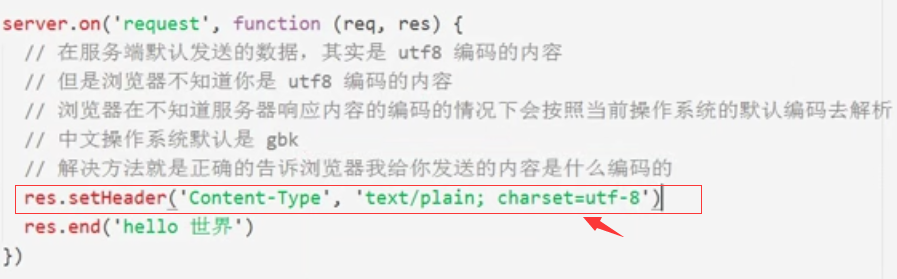
案例如下:
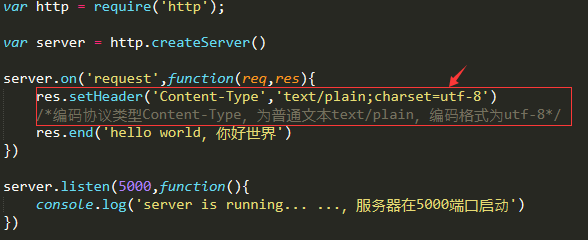
乱码与设置响应头格式对比:
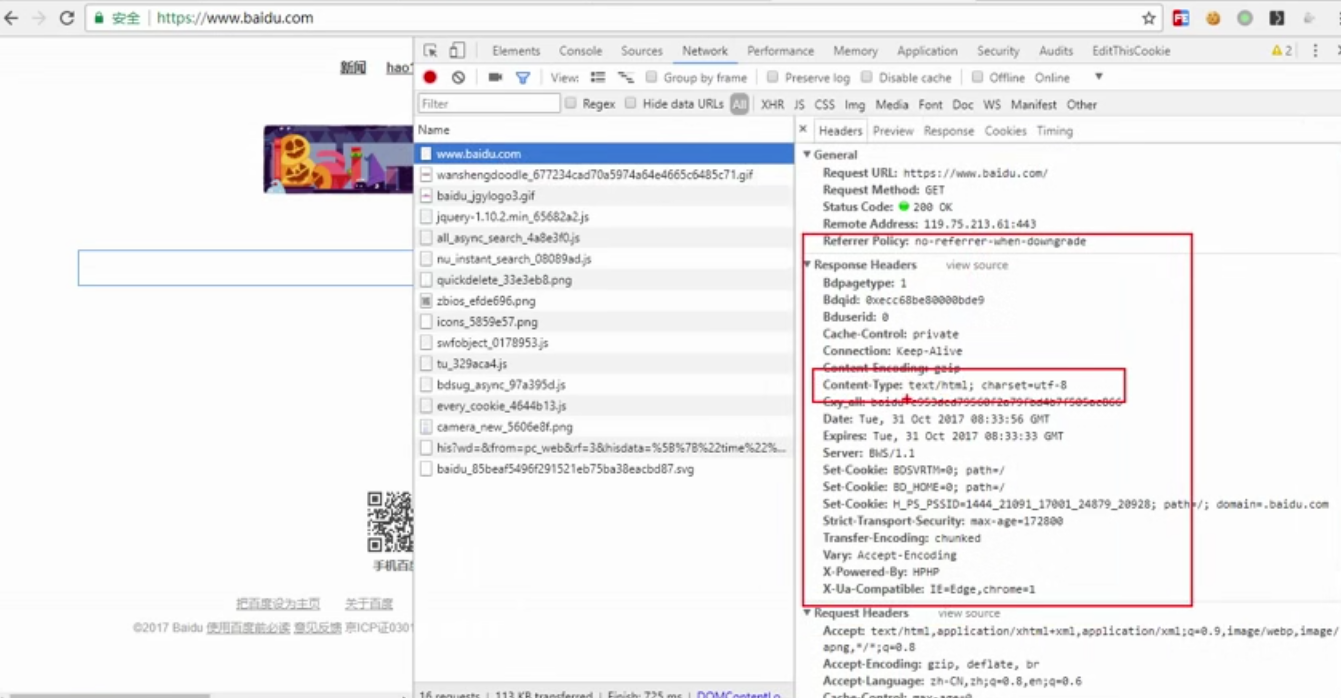
3、除了普通文本text/plain,还有其他格式,例如百度
4、Content-Type作用
在http协议里,Content-Type作用为设定信息类型
代码如下所示
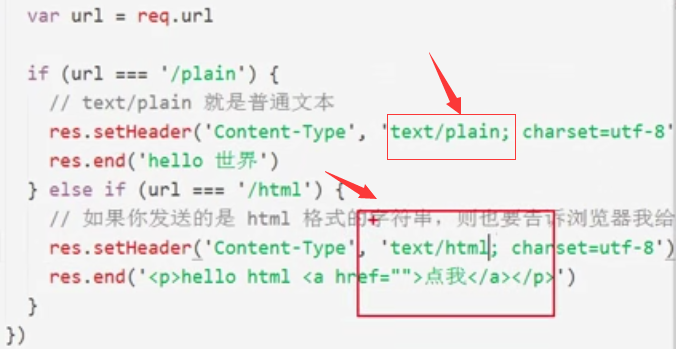
案例根据不同Content-Type返回不同类型,如下所示

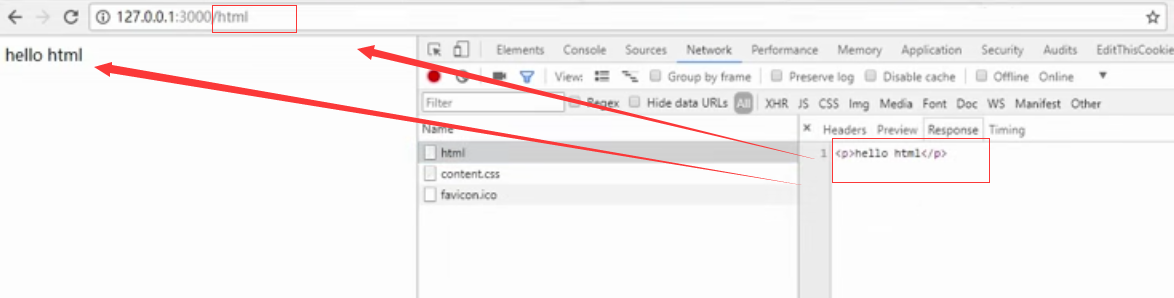
如果Content-Type为html,浏览器会将其进行解析;如果是普通文本,则会将其解析为普通字符串文
5、发送文件中的数据及Content-Type内容类型
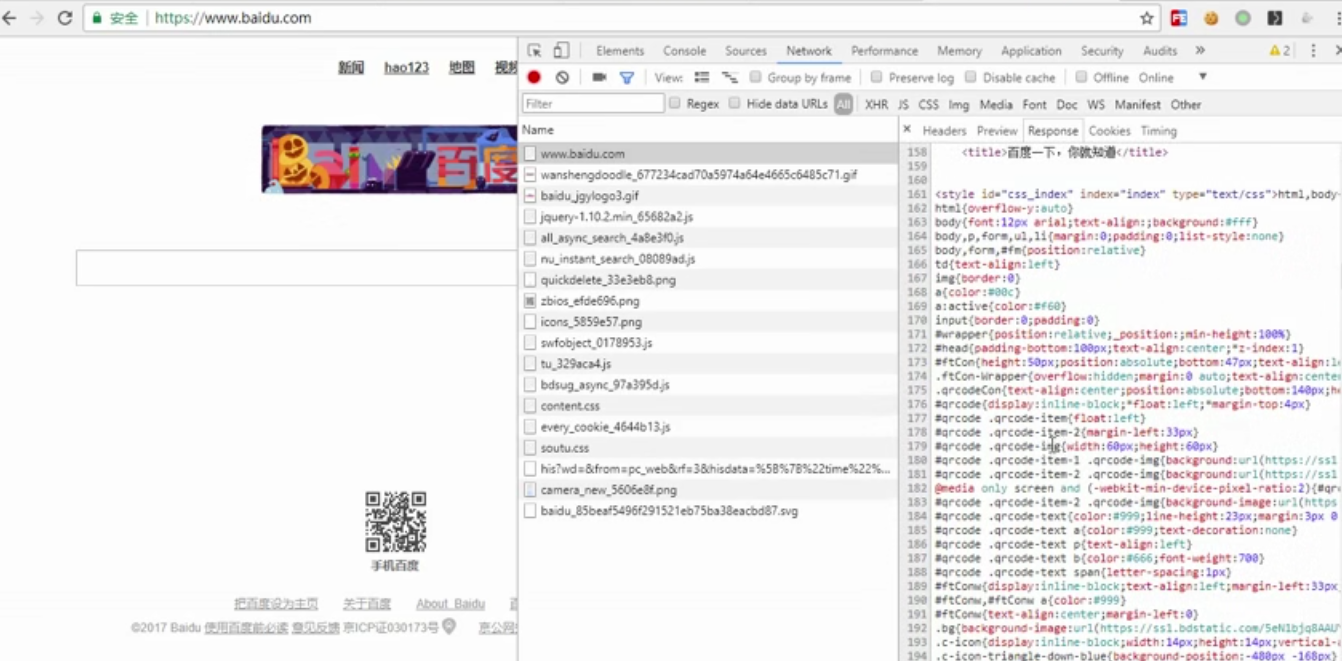
打开百度审查,即可得知,请求页面时,本质获取的是字符串,但为html内容字符串。然后浏览器对其进行解析渲染
6、测试
首先在文件夹下存放不同类型的资源文件
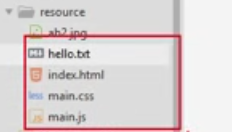
需求:请求路径不同,访问不同的资源文件
①首先读取html文件
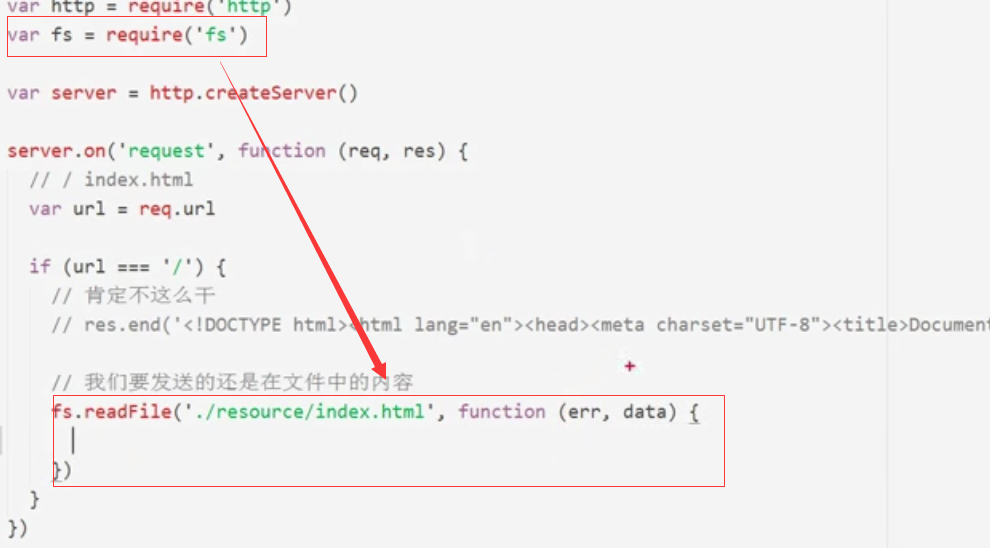
详细设置

接下来修改HTML文件内容,再次刷新页面,这里注意:不用重启服务器
这里之所以不用重启服务器,因为js脚本文件并未更新,每次只是重新读取html文件,所以这里直接刷新后会重新读取
②读取图片
这里拓展对照表

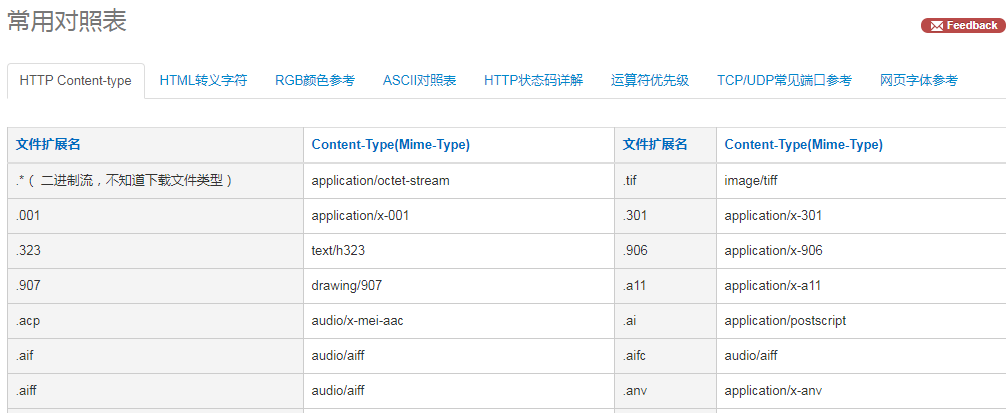
查找图片对应Content-Type类型

③统一资源定位符

④小结

(13)总结



接口对象:

核心模块:

http网络服务构建模块:

框架:

目前为止的一些操作,都是原生语法操作,例如http网络服务模块相关操作比较繁琐;所以后期学习express简化操作;所以这里会先使用原生,后用express框架
类似于JS操作DOM,后续学习jQuery简化DOM操作语法
.