Python8 ---- 数据库基础
数据库基础
数据库的基本介绍
-
关系型数据库
创建在关系模型基础上的数据库, 用来存储和管理结构化的数据.-
关系模型
类似python中类 class Student: def __init__(self, name, classes ...): self.name = name self.classes = classes def borrow(self, book): print(f"student {self.name} borrow {book.name}") class Book: pass在关系型数据库当中, 可以用三张数据表来表示
- 学生表
- 图书表
- 借阅表(记录行为)

-
关系型数据库的特点(也就是事务的特点)
- ACID
-
Atomic(原子性)
指事务的操作是不可分割的, 要么完成, 要么不完成. 不存在其他的中间态A -> B 转账, 如果中途中断, 那么整个银行系统就会崩溃. -
Consistence(一致性)
事务A和事务B同时运行, 无论谁先结束, 数据库都会到达一致.集合点在东方明珠, 同学A从静安出发, 同学B从黄埔出发. 一致性不关心A和B谁先到达, 只关心最终两者都在东方明珠汇合. -
Isolation(隔离性)
解决多个事务同时对数据进行读写和修改的能力. -
Duration(持久性)
当某个事务一旦提交, 无论数据库崩溃还是其他原因, 该事务的结果都能够被持久化地保存下来.事务的所有操作都是有记录的, 即使数据库中途崩溃, 仍然可以通过记录恢复
-
- ACID
-
适用场景
考虑到事务和日志- 对数据完整性有要求.
- 存储的数据结构化完整.
- 单个数据库服务实例可以满足需求.
建立集群方案, 大多需要适用企业版, 企业版收费高昂.
- 读表操作远远大于写表操作.
-
-
非关系型数据库(
Nosql, not noly sql)
创建在Nosql系统存储(键对值)基础上的数据库, 既可以存储结构化的数据, 也可以存储非结构化的数据.
Mysql数据库的安装(服务端)
数据库分为服务端和客户端
-
windows
https://jingyan.baidu.com/article/9f7e7ec0ebac9a6f281554dd.html -
ubuntu
apt-get install mysql-server # 登录 mysql -u root -p -
mac
https://jingyan.baidu.com/article/b7001fe1c7cc260e7382dd66.html
Navicat的安装和使用(客户端)
-
windows&ubuntu
http://www.navicat.com.cn/ -
mac
SequelPro
Mysql数据库的基本使用
-
连接
- localhost
填写主机的时候就是填写ip地址
localhost对应的地址约等于127.0.0.1
- localhost
-
数据库(database)
-
Create
create database tunan_class_2;- 设置字符集
-
utf8和utf8mb4
mysql中utf8字符是不全的,utf8mb4才是和我们python中的utf-8字符集一致. -
排序规则
选择默认的utf8mb4_general_ci
-
- 设置字符集
-
Retrieve
show databases; -
Update
ALTER database tunan_class_2 DEFAULT CHARACTER SET 'utf8mb4' -
Delete
drop database 库名
-
-
数据表(table)
-
Create
use tunan_class; CREATE TABLE class_2( id int PRIMARY KEY auto_increment, student_name varchar(255) )DEFAULT charset=utf8mb4; -
Retrieve
show tables; -
Update
ALTER TABLE class_2 RENAME class_3; -
Delete
drop table 表名- 只删除数据, 不删除表
truncate 表名
- 只删除数据, 不删除表
-
课后作业
- 什么是关系型数据表, 什么是非关系型数据表, 他们有什么区别, 各有什么应用场景.
- 什么是事务, 事务的特点.
- 完成Mysql服务端和Navicat的安装.
- 完成数据库和数据表的基础操作.
常用的数据类型
-
int
数字范围-2**32 ~ 2**32-1 -
bigint
数字范围-2**63 ~ 2 ** 63-1 -
float
float(m,d), 其中m表示的是有效位, d表示小数位 有效位就是把当前的小数: 12345.12 转变成科学计数法: 1.234512 * 10**5 m最大值为7,d不能大于m,m包括小数位 -
double
double(m, d), 其中m表示的是有效位, d表示小数位 m的最大值为15 -
decimal
涉及金额的时候使用decimaldouble(m, d), 其中m表示的是有效位, d表示小数位 m的最大值为65 **不会产生精度问题, 因为decimal没有精度损失的本质是因为它存的是字符串.**
-
char
表示固定长度的字符串, 长度为255个字节中文字符占据3~4个字节
-
varchar
表示不定长的字符串, 长度为0~65535个字节 -
TEXT
长文本类型, 最大长度占据64kb在mysql中一般不建议使用大文体来存储,推荐使用Nosql键值存储,除非需求
-
datetime
如果当前时区发生更改, datetime类型不会发生更改, 与存入的日期保持一致 -
timestamp
如果当前时区发生更改, timestamp类型会跟着时区更改.
常用的运算符
-
算术运算符
+-*/- div
取商SELECT 5 div 3 - mod
取余SELECT 5 mod 3
-
比较运算符
=类似python中的 == SELECT 1 =1!=>与>=<与<=between与not betweenSELECT 2 not between 1 and 3is null与is not null
用来判断当前是否有记录
-
逻辑运算符
- NOT
- AND
- OR
- XOR(了解)
异或, 两个值一个True, 一个为False, 当前表达式才为True
常用的函数
- 算术运算
- SUM
求和 - AVG
平均数 - MAX和MIN
对字符串进行操作时, 类似python的排序, 是根据ascii码来排序的. - COUNT
计算当前记录数 SELECT count(*) from test
- SUM
- 字符处理
- CHAR_LENGTH
SELECT CHAR_LENGTH("test") - FORMAT
格式化SELECT FORMAT(0.333333,2) - LEFT和RIGHT
SELECT right("abcdefg", 2) - TRIM
SELECT trim("abcdefg ")
- CHAR_LENGTH
课后作业
- 通过navicat建表, 包含当前常用的数据类型.
INSERT INTO test(float_field, double_field) values(123.22, 123123.22) - 练习常用的运算符
- 练习常用的函数
> 创建表的时候尽量加上create_time字段, 为create_time设置默认值CURRENT_TIMESTAMP
CRUD操作
-
Create(增)
-
单条插入
INSERT INTO 表名(字段1, 字段2..) VALUES(值1, 值2) INSERT INTO class_1(name) VALUES('name_1') -
多条插入
INSERT INTO 表名(字段1, 字段2..) VALUES(值1, 值2), (值1, 值2)
-
-
Retrieve(查)
-
获取所有记录
SELECT 字段1, 字段2 FROM 表名 SELECT name FROM class_1 SELECT * FROM class_1 -
条件查询(
WHERE,AND,OR)SELECT 字段1, 字段2 FROM 表名 WHERE 表达式 SELECT * FROM class_1 WHERE name="name_1" AND id=8 -
模糊匹配(
LIKE,%)模糊匹配有性能问题, 表记录如果比较多, 查询速度很慢
SELECT 字段1, 字段2 FROM 表名 WHERE 表达式 SELECT * FROM class_1 WHERE name LIKE "%m%" -
限制返回条数(
LIMIT)查询表达式 LIMIT 数量 -
过滤重复值(
DISTINCT)
对查询的结果进行过滤.如果指定多个字段, 会对多个字段联合进行过滤
SELECT DISTINCT 字段1, 字段2 FROM 表名 [条件语句] SELECT distinct name, create_time FROM class_1 WHERE name like '%m%' -
排序问题
对查询的结果进行排序-
升序(
ASC)
数据库默认是升序的查询表达式 ORDER BY 字段 ASC -
降序(
DESC)查询表达式 ORDER BY 字段 DESC
-
-
获取查询结果的条数(
COUNT)SELECT COUNT(*) FROM 表名 [条件语句]
-
-
Update(更新)
UPDATE 表名 SET 字段1=新值, 字段2=新值 WHERE 表达式 UPDATE class_1 SET name='name_0' WHERE id=8 -
Delete(删除)
DELETE FROM 表名 WHERE 表达式 DELETE FROM class_1 WHERE name='name_0'
集合操作
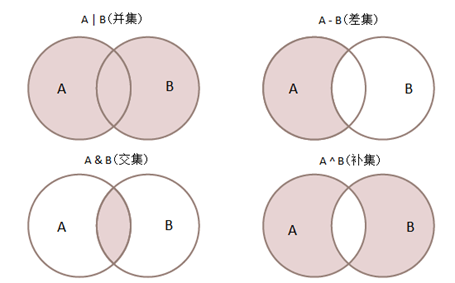
-
并集
UNION
子语句SELECT 必须拥有相同数量的列(字段), 且列的数据类型也相同若多个字段,也会对多个字段进行匹配
SELECT name from class_1 WHERE name is not NULL UNION SELECT name from class_2 WHERE name is not NULL -
交集(
JOIN,INNER JOIN)SELECT s1.name FROM (SELECT name from class_1 WHERE name is not NULL) as s1 JOIN (SELECT name from class_2 WHERE name is not NULL) as s2 ON s1.name=s2.name -
差集(
LEFT JOIN,RIGHT JOIN)-
A对B的差集(
LEFT JOIN)SELECT * FROM // s1对s2的差集, select就可以使用s1.name (SELECT name from class_1 WHERE name is not NULL) as s1 LEFT JOIN (SELECT name from class_2 WHERE name is not NULL) as s2 ON s1.name=s2.name WHERE s2.name is NULL // 限定s1有, s2没有的记录 -
B对A的差集(
RIGHT JOIN)SELECT * FROM (SELECT name from class_1 WHERE name is not NULL) as s1 RIGHT JOIN (SELECT name from class_2 WHERE name is not NULL) as s2 ON s1.name=s2.name WHERE s1.name is NULL
-
-
补集
A与B的补集 = A与B的并集 - A与B的交集
A与B的补集 = A对B的差集 + B对A的差集 √
SELECT s1.name FROM (SELECT name from class_1 WHERE name is not NULL) as s1 LEFT JOIN (SELECT name from class_2 WHERE name is not NULL) as s2 ON s1.name=s2.name WHERE s2.name is NULL UNION SELECT s2.name FROM (SELECT name from class_1 WHERE name is not NULL) as s1 RIGHT JOIN (SELECT name from class_2 WHERE name is not NULL) as s2 ON s1.name=s2.name WHERE s1.name is NULL
课后作业
- 练习CRUD操作
- 练习集合操作