一、设备指纹
一般都是基于某些设备信息,通过一些设备指纹算法会将这些信息组合起来,通过特定的hash算法得到一个最后的ID值,作为该设备的唯一标识符。常见的元素有:
- sim卡信息
- wifi信息
- 硬盘信息
- 内存信息
- 屏幕信息
- 设备的传感器特征,比如麦克风、加速传感器、摄像头等信息
- 浏览器本身的特征,包括UA,版本,操作系统信息等
- 浏览器中插件的配置,主要是插件的类型与版本号等
- 设备操作系统的特征,比如是否越狱等
- 浏览器的Canvas特征,影响该特征的因素有GPU特性造成的渲染差异,屏幕的分辨率以及系统不同字体的设置等
主动式设备指纹技术需要在客户端上植入自己的Javascript或SDK代码,主动收集设备相关的特征,用以标识设备和用户。在特征的选取上,需要考虑特征的稳定性和准确度。理想的特征应该在一定的时间段内不会因为外界的条件变化、或是用户的操作行为而发生变化(比如上面那些,而像用户的通讯录的总联系人数这种就不适合),同时在不同的设备上具有显著的差异。
二、知识图谱
不管你打算做什么样的社交网络分析还是图分析,前提都是你要先构建出网络,然后才能有之后。
把客户基础信息等结构化的数据清洗为点、边关系--à图数据库存储---à实时关联特征计算----à图分析算法。
把不同的信息连到一起,其实关键是哪些信息是你所重点关注的应该把它作为一个实体,而不是节点属性,图谱的设计。比如我们公司把时间也作为实体,企业的行为也作为实体,通过这些实体把企业的投资、诉讼等行为都联系起来,考虑企业的历史关系。
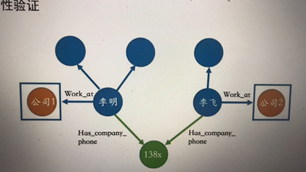
关联关系构建,对公:买卖违约(合同)、同联系(地址、电话、邮箱)、招中标、司法(拓展亲属关系)、投融资、交易;对私:设备指纹、通讯录、社交平台上的好友关系、评论关系、是否在同一个城市(粗一点)
主要应用场景:
- 反欺诈(主要是团伙欺诈)
- 风险预测(从图谱网络中抽取一些feature放到评分卡里用,需要考虑时间穿越问题)
- 催收(挖掘一些可以触达的失联客户的联系人)
- 精准营销(匹配用户最合适的贷款产品)
- Lookalike人群扩展
https://www.jianshu.com/p/c7957ac169f1
- 智能搜索
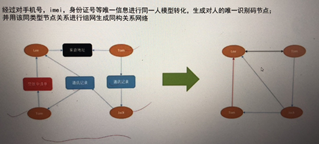
举个例子来说明构建知识图谱的流程,此处我们采用个人信息(也可以是设备指纹,总之有可能是虚假的数据)进行一个场景构建。
1)通过对数据进行清理,抽取,构建知识图谱的节点,比如工作地址,姓名,身份证,GPS,工作地点,单位,IP,联系人手机号,等等。
2)比较好的方式是建立基础信息表,然后不断更新,这种方式比较好的原因是可以防止异常,可以保证数据最终一致性。这个就会根据不同情况,构建不同基础数据表,少则十几个,二十几个,多的可以成百上千。
3)基于清洗后的信息,进入图数据库,构建出整个知识图谱。(姓名一样可能会被连在一起、身份证一样可能会被连在一起)
4)基于图算法进行相关的特征抽取或者通过网络结构进行负样本挖掘(标签传播)
欺诈的难点,在于把不同来源的数据汇总到一起构造欺诈引擎是一件比较困难的事情。一部分是要爬数据,还有就是爬出带来的数据千奇百怪。
三、特征抽取:
- 不一致性检验
在团簇中,如果用户的信息与我们的正常理解有严重偏差,那么这种团簇很可疑;如两个用户拥有同个家庭wifi,但所填家庭地址相差甚远,显然与现实不符。这里需要大量的人工干预,因为我们不能通过欺诈标签做相关的统计分析,更多的要靠经验判断。当然如果标签得当,我们其实可以通过做相似性度量来进行筛选重要的关联特征,作为规则的。

- 静态分析
给定时间节点,去尝试发现图形结构的异常子图。
- 动态分析
分析结构网络|随着时间变化的趋势
- 关联特征提取
对网络特征的提取,一方面可以考虑节点本身的中心性特征提取,比如度中心性、紧密中心性、介数中心性、pageRank;另一方面可以考虑衍生的图特征,关联用户的一度或二度联系人特征;另外就是网络嵌入特征,从网络中学习到隐式的表达矩阵,使得网络中重要的信息能够包含在一个相对低维的空间向量中。
https://github.com/thunlp/OpenNE
特征提取后可供上层规则系统或风险评估模型使用。基本思想仍然是在网络中社交越广泛,越有可能是一个坏人。
反欺诈对于实时决策的需求很高,这些指标都需要实时提取。其中一些指标,比如二度关联度, 在一般的情况下计算复杂度是很高的。在动态图的情形下,一般会采取一些近似的算法并进行预计算。
四、网络信息挖掘:
- 社区发现 团体欺诈
组团欺诈的挖掘难度非常大,它会藏在非常复杂的组织网络中,很难发现,只有当我们把隐含的关系网络梳理清楚了,才有可能发现潜在的风险,图谱可以帮助识别(信息共享,把内在图关系挖掘出来)。
网络评分建模:①首先通过社群划分(经验或社群划分的算法)②提取子网络特征(平均年龄、授信通过率、平均收入、平均负债率、平均多头数、子网络最大年龄差)作为X,逾期客户占比或子网络欺诈客户占比来决定Y值③考虑再用logit回归建模进行子网络评分或者如果有单调关系直接用一些规则(关联了黑节点n个的)④建模后被判定为黑网络的所有样本判定为黑样本。
- 失联模型
挖掘更多的潜在的可触达联系人。
负样本生成:
- 染色
染色本质就是一种基于关联图谱的半监督学习方法,我们知道在反欺诈的场景下,一个典型的困境就是欺诈标注非常少,获得的代价非常高,而我们要做一些监督式的机器学习,却又非常依赖于标注。因此如果能用少量的欺诈标注样本产生出更多的标注,就能最大程度利用欺诈样本。这就是染色的初衷,欺诈标注会沿着网络里的边从一个节点传播到另一个节点。
染色从直觉上比较容易理解,我们经常说近朱者赤,近墨者黑。一个用户和坏用户有关联,其实很有可能他本身就是有问题的。这里放一个数据,根据分析得到,一个客户一旦出现在某个坏客户的通讯录中,就有70%的概率会变坏。
五、知识图谱反欺诈
1. 关联网络预警
不仅仅关注①目标企业的风险预警(纳税情况异常、信用评分预警、对外担保情况异常、负债收入比异常、还款来源欠保障、资金需求急迫)还需要关注②关联方的风险预警(通过关联网络,关联方的风险会通过网络进行传播,包括关联方的诉讼风险、违约事件、异常经营、合规风险、负面舆情等)③风险事件(违约事件、舆情事件、政策监管、行业新规)
预警指标体系:A即时状态指标 B时序波动指标C风险评分类指标(综合多个弱指标)
对私:客户挖掘(理财、信贷),风险评估(关联方风险、场景式、模块化、全息),风险监控和预警(提前提示信号,模型判断信号重点)
2. 一致行动人
一致行动人挖掘
3. 探查多个企业的复杂网络
4. 产品
交易监管:构建企业间高管变动、投资动作、借贷担保的知识图谱。大额交易探查、疑似关联账户探查。
反洗钱:根据银行流水构建图谱。匹配一些特定的模式比如巨额资金分发多处、又从多处汇聚到一处的洗钱模式等、接入机器学习、多维分析模块
统计指标计算、子图匹配、关系推理、出入度