zoukankan
html css js c++ java
xml02 XML编程(CRUD)增删查改
XML解析技术概述
Demo2.java
import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import org.w3c.dom.Document; public class Demo2 { public static void main(String args[])throws Exception { //1.创建工程 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); //2.得到dom解析器 DocumentBuilder builder = factory.newDocumentBuilder(); //3.解析xml文档,得到代表文档的document Document document = builder.parse("src/book.xml"); } }
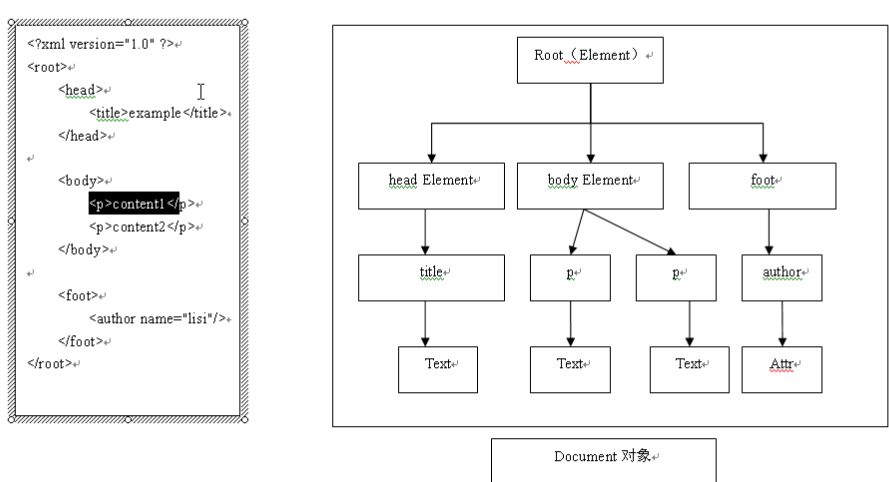
xml解析技术概述和使用Jaxp对xml文档进行dom解析
package cn.lysine; import org.junit.Test; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; //使用dom方式对xml文档进行 增删查改 CRUD public class Demo3 { // 读取xml文档中;<书名>java就业培训中心</书名> 节点的值 @Test public void read1() throws Exception { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); NodeList list = document.getElementsByTagName("书名"); Node node = list.item(1); String content = node.getTextContent(); System.out.println(content); //输出 java就业培训中心 } //得到xml中标签属性的值 @Test public void read2() throws Exception { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); // 得到根结点 Node root = document.getElementsByTagName("书架").item(0); list(root); } private void list(Node node) { System.out.println(node.getNodeName()); NodeList list = node.getChildNodes(); for(int i = 0; i <list.getLength(); i++ ){ Node childe = list.item(i); list(childe); } } //得到xml文档中标签属性的值:<书名 name="xxxx">java就业培训教材</书名> @Test public void read3() throws Exception{ DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); Element bookname = (Element)document.getElementsByTagName("书名").item(0); String value = bookname.getAttribute("name"); System.out.println(value); } //输出 xxxx }
import java.io.FileOutputStream; import java.io.IOException; import org.junit.Test; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; //使用dom方式对xml文档进行 增删查改 CRUD public class Demo3 { // 读取xml文档中;<书名>java就业培训中心</书名> 节点的值 @Test public void read1() throws Exception { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); NodeList list = document.getElementsByTagName("书名"); Node node = list.item(0); String content = node.getTextContent(); System.out.println(content); } //得到xml中标签属性的值 @Test public void read2() throws Exception { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); // 得到根结点 Node root = document.getElementsByTagName("书架").item(0); list(root); } private void list(Node node) { System.out.println(node.getNodeName()); NodeList list = node.getChildNodes(); for(int i = 0; i <list.getLength(); i++ ){ Node childe = list.item(i); list(childe); } } //得到xml文档中标签属性的值:<书名 name="xxxx">java就业培训教材</书名> @Test public void read3() throws Exception{ DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); Element bookname = (Element)document.getElementsByTagName("书名").item(0); String value = bookname.getAttribute("name"); System.out.println(value); } //向xml文档中添加节点:<售价>59.00元</售价> @Test public void add() throws Exception{ DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); //创建节点 Element price = document.createElement("售价"); price.setTextContent("59.00元"); //得到参考节点 Element refNode = (Element) document.getElementsByTagName("售价").item(0); //得到要挂崽的节点 把创建的节点挂到第一本书上 Element book = (Element)document.getElementsByTagName("书").item(0); //往book节点的指定位置插崽 book.insertBefore(price,refNode); //把更新后内存写回到xml文档 TransformerFactory tffactory = TransformerFactory.newInstance(); Transformer tf = tffactory.newTransformer(); tf.transform(new DOMSource(document), new StreamResult(new FileOutputStream("src/book.xml"))); } //add 向xml文档中添加节点:<书名>java就业培训教程</书名> 上添加name=“xxxx”属性 @Test public void addAttr() throws Exception{ DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); Element bookname = (Element) document.getElementsByTagName("书名").item(0); bookname.setAttribute("name", "xxxxx"); //把更新后内存写回到xml文档 TransformerFactory tffactory = TransformerFactory.newInstance(); Transformer tf = tffactory.newTransformer(); tf.transform(new DOMSource(document),new StreamResult(new FileOutputStream("src/book.xml"))); } //删除整个xml @Test public void delete1() throws Exception{ DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); //得到要删除的结点 Element e = (Element) document.getElementsByTagName("售价").item(0); //得到要删除的结点的爸爸 Element book = (Element) document.getElementsByTagName("书").item(0); //爸爸再删崽 book.removeChild(e); //把更新后内存写回到xml文档 TransformerFactory tffactory = TransformerFactory.newInstance(); Transformer tf = tffactory.newTransformer(); tf.transform(new DOMSource(document),new StreamResult(new FileOutputStream("src/book.xml"))); } public void delete2() throws Exception{ DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); //得到要删除的结点 Element e = (Element) document.getElementsByTagName("售价").item(0); e.getParentNode().getParentNode().getParentNode().removeChild(e.getParentNode().getParentNode()); //把更新后内存写回到xml文档 TransformerFactory tffactory = TransformerFactory.newInstance(); Transformer tf = tffactory.newTransformer(); tf.transform(new DOMSource(document),new StreamResult(new FileOutputStream("src/book.xml"))); } //update 更新 public void update()throws ParserConfigurationException, SAXException, IOException,Exception{ DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/book.xml"); //得到要更新的结点 Element e = (Element) document.getElementsByTagName("售价").item(0); e.setTextContent("109元"); //把更新后内存写回到xml文档 TransformerFactory tffactory = TransformerFactory.newInstance(); Transformer tf = tffactory.newTransformer(); tf.transform(new DOMSource(document),new StreamResult(new FileOutputStream("src/book.xml"))); } }
查看全文
相关阅读:
python_之无参装饰器_01
一 :接口自动化之 Rquests封装
python --字典基本用法
hadoop集群通过web管理界面只显示一个节点
Hadoop基础(十八):MapReduce框架原理(二)切片机制(二)
Hadoop基础(十七):MapReduce框架原理(一)切片机制(一)
Hadoop基础(十六):Hadoop序列化
Hadoop基础(十五): MapReduce概述
Hadoop基础(十四): HDFS 2.X新特性
Hadoop基础(十三): DataNode
原文地址:https://www.cnblogs.com/firecode/p/2460926.html
最新文章
python的list的基本操作、list循环、切片、字典基本操作、字典嵌套、字符串常用方法
python介绍、条件判断、循环、字符串格式化、乘法表.
Charles抓包方法
接口测试的工具postman和jmeter
关于python循环
JMeter脚本参数化 的方法用
仿制Django的admin组件完成的Xadmin组件设计——新的Xadmin组件的配置
仿制Django的admin组件完成的Xadmin组件设计——url分发
Python之单例对象的应用
Django学习笔记二十三——Django之admin模块的使用
热门文章
博客项目——〇五 评论功能实现
博客项目——〇四 个文章页面设计
博客项目——〇三 个人站点设计
博客项目——〇二首页设计
jQuery带参数的事件绑定
博客项目——〇一需求分析(占位)
python之匿名函数介绍
python_之递归函数
三元表达式和列表生成式
python之有参装饰器_02
Copyright © 2011-2022 走看看