无聊中,感觉自己思维僵硬,于是,总结一些贼有意思的题(坑),会持续更新。。。
先上一道简单的入门题:
1、单词覆盖还原(数据加强版)
题目描述
在一长串(3<=l<=255)中被反复贴有boy和girl两单词,后贴上的可能覆盖已贴上的单词(没有被覆盖的用句点表示),最终每个单词至少有一个字符没有被覆盖。问贴有几个boy几个girl?
输入输出格式
输入格式:
一行被被反复贴有boy和girl两单词的字符串。
输出格式:
两行,两个整数。第一行为boy的个数,第二行为girl的个数。
输入输出样例
……boyogirlyy……girl…….
4
2
数据范围:
对于100%的数据,满足字符串之间无空格且字符串长度小于106
Solution:
这道题其实很简单,在洛谷上有原题,而且是入门难度的,呵呵呵,开始还一直纠结题意,真是f**k。我们先解读一下样例,首先第一个boy就不用说了,往后看有一个o,则肯定覆盖了1个boy,继续往后看,两个y,则这里覆盖了2个boy,所以一共4个boy,至于girl的大家都能看出来,这里就不多说了。于是我们便能轻易得出代码:
1 #include<bits/stdc++.h> 2 using namespace std; 3 int a,b;string c; 4 int main() 5 { 6 cin>>c; 7 int l=c.size(); 8 for(int i=0;i<l;i++){ 9 if(c[i]=='b'||c[i+1]=='o'||c[i+2]=='y')a++; 10 if(c[i]=='g'||c[i+1]=='i'||c[i+2]=='r'||c[i+3]=='l')b++;} 11 cout<<a<<endl<<b; 12 return 0; 13 }
2、N 色球
【题目描述】
山山是一个双色球高手,每次必中无疑。
终有一天,他开始嫌弃双色球的颜色太少了,于是发明了 N 色球。
规则如下:
一个袋子里装有 n 个大小、形状相同的球,但每个球标有唯一的数字
你要从这个袋子中摸出 n-1 个球,最后的奖金为这 n-1 个球所标数字的乘积除以 p 的余数。
山山想知道他得到奖金的期望。
【输入文件】
输入文件 nsq.in 的第 1 行包含 2 个正整数 n,p
第二行包含 n 个正整数 a1,a2...an,表示每个球所标的数字
【输出文件】
输出文件 nsq.out 仅包含一个实数,表示得到奖金的期望
答案的误差不能超过 1e-6
【样例输入】
3 100
2 1 7
【样例输出】
7.6666666667
【数据规模】
对于 20%的数据,n≤2000
对于 20%的数据,n≤10^5,ai≤10^5,p=1000000007
对于 60%的数据,n≤10^6,ai≤10^9,p≤1000000007
Solution:
首先,期望就不用我赘述了,我们先转换一下题意,有n个数和一个p,在这n个数中取n-1个数相乘再对p取模,将所有情况所得值相加除以n。毋庸置疑,共有n种情况,我们可以这样想,对于第i个数,我们不取它,而是把它前面和后面的数相乘取模,这样我们用数组f维护从前往后的前缀积,因为数据较大,所以我们每次相乘便取模,同理,用数组b维护从后往前的后缀积,当然也要取模。这样,我们只需从前往后扫一遍,第i个值=f[i-1]*b[i+1]%p,并累加起来,最后输出累加值除以n就行了。
1 #include<iostream> 2 #include<cstdio> 3 #include<algorithm> 4 #include<cmath> 5 #include<cstring> 6 #include<queue> 7 #include<map> 8 using namespace std; 9 #define ll long long 10 inline ll gi() 11 { 12 ll a=0;char x=getchar();bool f=0; 13 while((x>'9'||x<'0')&&x!='-')x=getchar(); 14 if(x=='-')f=1,x=getchar(); 15 while(x>='0'&&x<='9')a=a*10+x-48,x=getchar(); 16 return f?-a:a; 17 } 18 ll n,p,a[1000005],f[1000005],b[1000005],tot; 19 int main() 20 { 21 //freopen("nsq.in","r",stdin); 22 //freopen("nsq.out","w",stdout); 23 n=gi(),p=gi();f[0]=1;b[n+1]=1; 24 for(int i=1;i<=n;i++)a[i]=gi(),f[i]=f[i-1]*a[i]%p; 25 b[n+1]=1; 26 for(int i=n;i>=1;i--)b[i]=(b[i+1]*a[i])%p; 27 for(int i=1;i<=n;i++)tot+=(f[i-1]*b[i+1])%p; 28 printf("%.10f",tot*1.0/n); 29 return 0; 30 }
3、Antiprime数
如果一个自然数n(n>=1),满足所有小于n的自然数(>=1)的约数个数都小于n的约数个数,则n是一个Antiprime数。譬如:1, 2, 4, 6, 12, 24。
任务:
编一个程序:
1、 从ANT.IN中读入自然数n。
2、 计算不大于n的最大Antiprime数。
3、将结果输出到ANT.OUT中。
输入( antip.in):
输入文件antip.in只有一个整数,n(1 <= n <= 2 000 000 000)。
输出(antip.out):
输出文件antip.out也只包含一个整数,即不大于n的最大Antiprime数。
样例输入( antip.in):
1000
样例输出(antip.out):
840
Solution:
(逆用)唯一分解定理+神奇的思路~
对于一个小于n的处于一定数量级上的数,显然它的质因子越小,这个数所包含的因子就会越多,所以我们可以只枚举几个较小质数的次方数,同时也可以减小循环的次数。
而对于有相同因子数的两个数,较小的一个更有更新的空间,所以当两个数有相同因子数时,我们取较小一个。
一定要用long long! 可以去看看这篇证明:http://www.doc88.com/p-389773941498.html
1 #include<cstdio> 2 #include<cmath> 3 #define ll long long 4 ll n,maxx,num[12]={0,2,3,5,7,11,13,17,19,21,23},ans; 5 inline void findd(ll now,ll tot,ll u,ll v) 6 { 7 if(maxx<tot || (tot==maxx && ans>now)) 8 { 9 maxx=tot;ans=now; 10 } 11 if(v>=11) return; 12 for(ll i=1;i<=u;i++) 13 { 14 now*=num[v]; 15 if(now>n) return; 16 findd(now,tot*(1+i),i,v+1); 17 } 18 } 19 int main() 20 { 21 freopen("antip.in","r",stdin); 22 freopen("antip.out","w",stdout); 23 scanf("%lld",&n); 24 findd(1,1,500,1); 25 printf("%lld ",ans); 26 return 0; 27 }
4、Vrisible Lattice Points
【题目描述】
从原点看第一象限的所有点,能直接看到的点的数目是多少(不包含原点)
【输入文件】
第 1 行为测试数据的组数C(1<=C<=1000),
以下C行,每行包含一个数N(1<=N<=1000),表示所求的可视范围。
【输出文件】
对于每一组测试数据,输出一行一个数,表示答案。
【样例输入】
4
2
4
5
231
【样例输出】
5
13
21
32549
Solution:
首先,题目主要是求从(0,0)能直接看到的点的个数。先考虑只有1*1的时候,很明显只能看到3个点:(0,1)、(1,0)、(1,1)。其实就是下三角的个数*2+1(斜率为1的点)。那么除开1*1以外,我们只需要计算斜率从0到1之间的个数就行了,不包括1,包括0。结果设为sum,那么最终ans=sum*2+1。
1*1只有一个斜率为0的。
2*2斜率有0,1/2(0已经算过了,以后不用再算了),其实就是多了一个斜率为1/2的。
3*3的时候,又多了1/3、2/3两个。
4*4的时候,又多了1/4、3/4也是两个。
5*5的时候,又多了1/5、2/5、3/5、4/5这4个。
……
从上面不难发现规律,对于n*n,可以从(0,0)连接到(n,0)到(n,n)上,斜率将会是1/n,2/n…(n-1)/n。
凡是 分子和分母能够约分的,也就是有公约数的,前面都已经出现过了。所以每次添加的个数就是分子和分母互质的个数。
那么问题就转换成了,对于一个数n,求小于n的与n互质的数的个数,其实就是欧拉函数吧~~!
1 #include <iostream> 2 #include<cstdio> 3 #include<cstring> 4 #include<algorithm> 5 using namespace std; 6 #define maxn 1000008 7 long long phi[maxn]; 8 void getphi() 9 { 10 for(int i=1; i<maxn; i++) phi[i]=i; 11 for(int i=2; i<maxn; i+=2) phi[i]>>=1; 12 for(int i=3; i<maxn; i+=2) 13 if(phi[i]==i) 14 { 15 for(int j=i; j<maxn; j+=i) 16 phi[j]=phi[j]/i*(i-1); 17 } 18 phi[1]=3; 19 for(int i=2; i<maxn; i++) 20 phi[i]=phi[i-1]+2*phi[i]; 21 } 22 int main() 23 { 24 getphi(); 25 int n,ca=0,t; 26 scanf("%d",&t); 27 while(t--) 28 scanf("%d",&n), 29 printf("%d %d %lld ",++ca,n,phi[n]); 30 return 0; 31 }
5、与运算
【题目描述】
给定 n 个数,找出两个,使得它们经过与运算后结果最大。
注意,选出来的两个数在原数组中的位置不能一样,但是数值可以一样。
【输入格式】
第一行一个整数 n,表示数字个数。
第二行 n 个数,表示给定的数。
【输出格式】
一个整数表示答案。
【样例输入】
3
1 2 1
【样例输出】
1
【数据范围】
对于 20%的数据点,n <= 1000
对于另外 20%的数据点,只有 0 和 1
对于 100%的数据点,n <= 100000, 0 <= 数值 <= 10^9
Solution:
就是从最高的一位向下找,如果这一位为1的数多于两个就取出这些数,把其他数踢出,然后再取出的这些数里面继续下一位的一样的处理,我就用递归写的,最后留下的两个数的相与值会最大。
1 #include<bits/stdc++.h> 2 using namespace std; 3 #define ll long long 4 #define il inline 5 #define M 100005 6 il ll gi() 7 { 8 int a=0;char x=getchar();bool f=0; 9 while((x>'9'||x<'0')&&x!='-')x=getchar(); 10 if(x=='-')x=getchar(),f=1; 11 while(x>='0'&&x<='9')a=a*10+x-48,x=getchar(); 12 return f?-a:a; 13 } 14 int a[M],n; 15 il int getand(int *num,int len,int w) 16 { 17 int s[len],sta=0; 18 memset(s,0,sizeof(s)); 19 int b=0; 20 for(int i=w;i>=0;i--) 21 { 22 for(int j=1;j<=len;j++) 23 { 24 if(num[j]&(1<<i)){ 25 b++; 26 s[++sta]=num[j]; 27 } 28 } 29 if(b>1) 30 { 31 int ret=getand(s,sta,i-1)+(1<<i); 32 return ret; 33 } 34 b=0;sta=0; 35 } 36 return 0; 37 } 38 int main() 39 { 40 41 n=gi(); 42 for(int i=1;i<=n;i++)a[i]=gi(); 43 cout<<getand(a,n,31); 44 return 0; 45 }
6、斐波拉契
题目描述
小 C 养了一些很可爱的兔子。 有一天,小 C 突然发现兔子们都是严格按照伟大的数学家斐波那契提出的模型来进行 繁衍:一对兔子从出生后第二个月起,每个月刚开始的时候都会产下一对小兔子。我们假定, 在整个过程中兔子不会出现任何意外。
小 C 把兔子按出生顺序,把兔子们从 1 开始标号,并且小 C 的兔子都是 1 号兔子和 1 号兔子的后代。如果某两对兔子是同时出生的,那么小 C 会将父母标号更小的一对优先标 号。
如果我们把这种关系用图画下来,前六个月大概就是这样的:
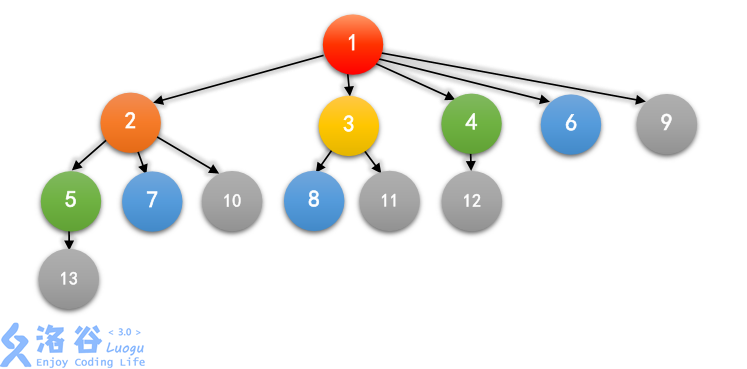
其中,一个箭头 A → B 表示 A 是 B 的祖先,相同的颜色表示同一个月出生的兔子。
为了更细致地了解兔子们是如何繁衍的,小 C 找来了一些兔子,并且向你提出了 m 个 问题:她想知道关于每两对兔子 aia_iai 和 bib_ibi ,他们的最近公共祖先是谁。你能帮帮小 C 吗?
一对兔子的祖先是这对兔子以及他们父母(如果有的话)的祖先,而最近公共祖先是指 两对兔子所共有的祖先中,离他们的距离之和最近的一对兔子。比如,5 和 7 的最近公共祖 先是 2,1 和 2 的最近公共祖先是 1,6 和 6 的最近公共祖先是 6。
输入输出格式
输入格式:
从标准输入读入数据。 输入第一行,包含一个正整数 m。 输入接下来 m 行,每行包含 2 个正整数,表示 aia_iai 和 bib_ibi 。
输出格式:
输出到标准输出中。 输入一共 m 行,每行一个正整数,依次表示你对问题的答案。
输入输出样例
5
1 1
2 3
5 7
7 13
4 12
1
1
2
2
4
说明
【数据范围与约定】 子任务会给出部分测试数据的特点。如果你在解决题目中遇到了困难,可以尝试只解 决一部分测试数据。 每个测试点的数据规模及特点如下表:
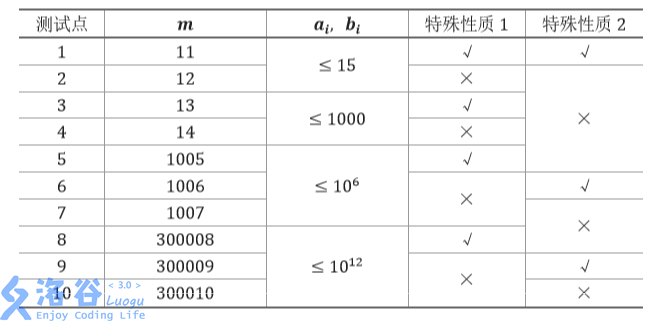
特殊性质 1:保证 aia_iai, bib_ibi 均为某一个月出生的兔子中标号最大的一对兔子。例如,对 于前六个月,标号最大的兔子分别是 1, 2, 3, 5, 8, 13。
特殊性质 2:保证 ∣ai−bi∣≤1|a_i-b_i|le 1∣ai−bi∣≤1
Solution:
题目来自于洛谷的一次月赛,考的时候在ka哥提醒下AC,值得说这题其实很容易,关键是思路。
解法:斐波拉契
思路:很多人直接诶想到了lca吧,但对这道题显然是不可以的。我们考虑列出几项斐波拉契数来查找规律:[1] [2] [3] [4 5] [6 7 8] [9 10 11 12 13]…我们观察一下上述的几项,同一个[]中的是同时出生的,我们发现第i个月出生的兔子恰巧就是它上个月之前的兔子所生,而且对于一个数x,它的直接父亲就是x-fi,所以我们可以对于每次询问(a,b),将a、b中较大的数先往前跳到它的父亲,然后比较此时a和b的大小是否相同,若想同则输出该数,若不同则重复上述步骤继续往前跳。说的好像不太清楚,但是我们自己列一列应该很容易看出。举个例子:假设我要询问8和11的最近公共祖先是谁,我们先对11往前跳,即11-8得到了3,此时比较3和8的大小,不相等,so用较大的数8继续往前跳,即8-5=3,此时3和3相等了,所以3就是11和8的最近公共祖先。
注意:题目中数据较大到了10的12次方,所以要开long long,此外必须得预处理出斐波拉契中的前60项(因为数据只有10的12次方,斐波拉契的第60项刚好超过了数据范围),然后就是读入优化(数据有300多万次询问而且数还那么大),最后在比较时最好二分查找节省时间。
代码量超少,关键是思路稍微得思考。
1 #include<bits/stdc++.h> 2 using namespace std; 3 #define ll long long 4 #define il inline 5 ll m,a,b; 6 il ll gi() 7 { 8 ll a=0;char x=getchar();bool f=0; 9 while((x<'0'||x>'9')&&x!='-')x=getchar(); 10 if(x=='-')x=getchar(),f=1; 11 while(x>='0'&&x<='9')a=a*10+x-48,x=getchar(); 12 return f?-a:a; 13 } 14 ll c[1000000]; 15 il void find(ll a,ll b) 16 { 17 if(a<b)swap(a,b); 18 if(a==b){printf("%lld ",a);return;} 19 int w=lower_bound(c,c+62,a)-c; 20 find(b,a-c[w-1]); 21 } 22 int main() 23 { 24 m=gi(); 25 c[0]=1;c[1]=1; 26 for(int i=2;i<=61;i++)c[i]=c[i-1]+c[i-2];//printf("%lld ",c[i]); 27 while(m--) 28 { 29 a=gi(),b=gi(); 30 find(a,b); 31 } 32 return 0; 33 }
7、楼房
一道codevs上的题目。(在闲逛博客园时从一位学姐(神犇)的博客看到的题目)
地平线(x轴)上有n个矩(lou)形(fang),用三个整数h[i],l[i],r[i]来表示第i个矩形:矩形左下角为(l[i],0),右上角为(r[i],h[i])。地平线高度为0。在轮廓线长度最小的前提下,从左到右输出轮廓线。
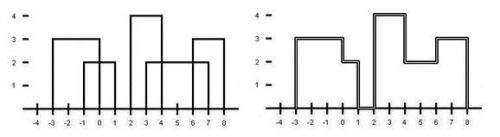
下图为样例2。
输入输出格式
输入格式:
第一行一个整数n,表示矩形个数
以下n行,每行3个整数h[i],l[i],r[i]表示第i个矩形。
输出格式:
第一行一个整数m,表示节点个数
以下m行,每行一个坐标表示轮廓线上的节点。从左到右遍历轮廓线并顺序输出节点。第一个和最后一个节点的y坐标必然为0。
输入输出样例
【样例输入1】
2
3 0 2
4 1 3
【样例输入2】
5
3 -3 0
2 -1 1
4 2 4
2 3 7
3 6 8
输出样例#1:
【样例输出1】
6
0 0
0 3
1 3
1 4
3 4
3 0
Solution:
正解有很多吧。什么线段树+扫描线。但我注意到的是一种用堆的做法:
这诸多情况,真是想想就头疼。
但是扫描线,再加上堆的强大援助就能解决
下面我就用十分通俗的语言讲解我的思路
扫描线,就是每一条竖着的线,楼房左侧的线叫入边,右侧的线叫出边,扫描线有长度(高度)up,横坐标x和出入边的标识k(k=1为入边,k=2为出边)。
struct line{
int up,x,k;
}l[200020];
把所有竖边都加入扫描线后,就进行排序,排序要按照从左到右的顺序
如果横坐标相同,入边在先,出边在后
如果同为入边,高的在先,矮的在后,防遮挡
如果同为出边,矮的在先,高的在后,防遮挡

int cmp(line i,line j){
if(i.x!=j.x)return i.x<j.x;
if(i.k!=j.k)return i.k<j.k;
if(i.k==1)return i.up>j.up;
if(i.k==2)return i.up<j.up;
}
通过对图形的分析,我们发现,能够参与答案的只有目前的最高点,
所以我们对于入边只需要堆的最大值,其他的尽管加上
对于出边只需要判断一下是否是此刻的最大值,然后加加删删
代码:
1 #include<iostream> 2 #include<set> 3 #include<algorithm> 4 using namespace std; 5 int n; 6 struct build{ 7 int h,l,r; 8 }a[100010]; 9 struct line{ 10 int up,x,k; 11 }l[200020]; 12 int cnt,num; 13 struct ANS{ 14 int ax,ay; 15 }ans[400040]; 16 multiset<int>s; 17 int cmp(line i,line j){ 18 if(i.x!=j.x)return i.x<j.x; 19 if(i.k!=j.k)return i.k<j.k; 20 if(i.k==1)return i.up>j.up; 21 if(i.k==2)return i.up<j.up; 22 } 23 int main(){ 24 cin>>n; 25 for(int i=1;i<=n;i++){ 26 cin>>a[i].h>>a[i].l>>a[i].r; 27 l[++cnt].up=a[i].h,l[cnt].x=a[i].l,l[cnt].k=1; 28 l[++cnt].up=a[i].h,l[cnt].x=a[i].r,l[cnt].k=2; 29 } 30 sort(l+1,l+cnt+1,cmp); 31 s.insert(0); 32 for(int i=1;i<=cnt;i++){ 33 int mx=*s.rbegin(); 34 if(l[i].k==1){ 35 if(l[i].up<=mx)s.insert(l[i].up); 36 else{ 37 ++num;ans[num].ax=l[i].x;ans[num].ay=mx; 38 ++num;ans[num].ax=l[i].x;ans[num].ay=l[i].up; 39 s.insert(l[i].up); 40 } 41 } 42 if(l[i].k==2){ 43 if(l[i].up==mx&&s.count(mx)==1){ 44 s.erase(mx); 45 ++num;ans[num].ax=l[i].x;ans[num].ay=l[i].up; 46 ++num;ans[num].ax=l[i].x;ans[num].ay=*s.rbegin(); 47 } 48 else s.erase(s.find(l[i].up)); 49 } 50 } 51 cout<<num<<endl; 52 for(int i=1;i<=num;i++){ 53 cout<<ans[i].ax<<' '<<ans[i].ay<<endl; 54 } 55 }
8、圆圈
圆圈
c c ircle .cpp/in/out
1s / 128M
[ 题目描述]
现在有一个圆圈, 顺时针标号分别从 0 到 n-1, 每次等概率顺时针走一步或者逆时针走一步,
即如果你在 i 号点,你有 1/2 概率走到((i-1)mod n)号点,1/2 概率走到((i+1)mod n)号点。问
从 0 号点走到 x 号点的期望步数。
[ 输入]
第一行包含一个整数 T,表示数据的组数。
接下来有 T 行,每行包含两个整数 n, x。
T<=10, 0<=x<n<=300;
[ 输出]
对于每组数据,输出一行,包含一个四位小数表示答案。
[ 样例输入]
3
3 2
5 4
10 5
[ 样例输出]
2.0000
4.0000
25.0000
[ 数据范围]
对于 30% 的数据,n<=20
对于 50% 的数据,n<=100
对于 70% 的数据,n<=200
对于 100%的数据,n<=300
Solution:
题目来源 sdut 2878:
期望公式:
E[x]=0 (x==0);
E[x]=0.5*(E[x-1]+1)+0.5*(E[x+1]+1); (x!=0)
移项得,-E[i-1]*0.5+E[i]*0.5-E[i+1]*0.5=1
n 个方程高斯消元求解。因为每个方程只有三个不为零系数,所以当 TLE 可以适当剪枝。
其实可以直接打表,然后不难发现规律。详见代码。
1 #include<iostream> 2 #include<cstdio> 3 using namespace std; 4 int t,n,x; 5 int main() 6 { 7 freopen("circle.in","r",stdin); 8 freopen("circle.out","w",stdout); 9 scanf("%d",&t); 10 while(t--) 11 { 12 scanf("%d%d",&n,&x); 13 printf("%d.0000 ",(n-x)*x); 14 } 15 return 0; 16 }
9、无限序列
无限序列
infinit .pas/c/cpp
1s / 128M
[ [ 问题描述] ]
我们按以下方式产生序列:
1、 开始时序列是: "1" ;
2、 每一次变化把序列中的 "1" 变成 "10" ,"0" 变成 "1"。
经过无限次变化,我们得到序列"1011010110110101101..."。
总共有 Q 个询问,每次询问为:在区间 A 和 B 之间有多少个 1。
请写一个程序回答 Q 个询问。
[ [ 输入 数据 ]
第一行为一个整数 Q,后面有 Q 行,每行两个数用空格隔开的整数 a, b。
[ [ 输出 数据 ]
共 Q 行,每行一个回答
[ [ 输入 样例] ]
1
2 8
[ [ 输出样例] ]
4
[ [ 数据 范围] ]
1 <= Q <= 5000
1 <= a <= b < 2^63
Solution:
我们先看看序列变化规律, S1 = "1", S2 = "10", S3 = "101", S4 = "10110", S5 = "10110101",
等等. Si 是 S(i+1)的前缀。
序列 Si 是由序列 S(i-1) 和 S(i-2), 连接而成的。
即 Si = Si-1 + Si-2 (实际上上是 Fibonacci 数列)。
找到规律以后,我们可以可以用递归的方法求出从从位置 1 到位置 X 之间所有的 1 的个数,
用一个函数 F 计算,结果为 f(b)-f(a-1)。
具体的参见:http://blog.csdn.net/famousdt/article/details/6907408
时间复杂度为: O(Q * log MAX_VAL)
此题需要先找出数学规律, 再进用递归实现。 主要考查选手的数学思维能力和递归程序的实
现。
1 #include<iostream> 2 #include<cstdio> 3 #include<algorithm> 4 #include<cmath> 5 #include<cstring> 6 using namespace std; 7 #define ll long long 8 ll q,x,y,f[100]; 9 inline ll gi() 10 { 11 ll a=0;char x=getchar();bool f=0; 12 while((x<'0'||x>'9')&&x!='-')x=getchar(); 13 if(f=='-')x=getchar(),f=1; 14 while(x>='0'&&x<='9')a=a*10+x-48,x=getchar(); 15 return f?-a:a; 16 } 17 inline ll find(ll l,ll k) 18 { 19 if(l==0)return 0; 20 if(l==f[k])return f[k-1]; 21 else if(l<=f[k-1])return find(l,k-1); 22 return f[k-2]+find(l-f[k-1],k-2); 23 } 24 int main() 25 { 26 freopen("infinit.in","r",stdin); 27 freopen("infinit.out","w",stdout); 28 q=gi();f[0]=1;f[1]=1; 29 for(int i=2;i<=91;i++)f[i]=f[i-1]+f[i-2]; 30 while(q--){ 31 x=gi();y=gi(); 32 printf("%lld ",find(y,91)-find(x-1,91)); 33 } 34 return 0; 35 36 }
10、删数
[ [ 问题描述] ]
有 N 个不同的正整数数 x 1 , x 2 , ... x N 排成一排,我们可以从左边或右边去掉连续的 i 个数
(只能从两边删除数),1<=i<=n,剩下 N-i 个数,再把剩下的数按以上操作处理,直到所
有的数都被删除为止。
每次操作都有一个操作价值, 比如现在要删除从 i 位置到 k 位置上的所有的数。 操作价值为
|x i – x k |*(k-i+1),如果只去掉一个数,操作价值为这个数的值。如何操作可以得到最大
值,求操作的最大价值。
[ [ 输入数据] ]
第一行为一个正整数 N,第二行有 N 个用空格隔开的 N 个不同的正整数。
[ 输出数据] ]
包含一个正整数,为操作的最大值
[ [ 样例] ]
re move .in
6
54 29 196 21 133 118
re move. . out
768
[ [ 数据范围] ]
3<=N<=100
N 个操作数为 1..1000 之间的整数。
[ [ 样例说明] ]
经过 3 次操作可以得到最大值,第一次去掉前面 3 个数 54、29、196,操作价值为 426。第
二次操作是在剩下的三个数(21 133 118)中去掉最后一个数 118,操作价值为 118。第三
次操作去掉剩下的 2 个数 21 和 133 ,操作价值为 224。操作总价值为 426+118+224=768。
Solution:
这是一个基本的动态规划问题。
我们用 F[i][j]表示按规则消去数列 a[i..j]得到的的最大值;
删除第 i 个数得到的最大值为 a[i];
删除 a[i..j]得到的最大值为:一次性删除数列 a[i..j]得到的值是|a[i]-a[j]|*(j-i+1)
或者是先删除 a[i..k] 再删除 a[k+1..j], k 在 i 到 j-1 之间,得到的值是
F[i][k]+F[k+1][j].
我们得到状态转移方程:
F[i][i]=a[i], for i=1..N
对于任意的 i<j,有:
F[i][j]=max{|a[i]-a[j]|*(j-i+1), f[i][i]+f[i+1][j],
F[i][i+1]+F[i+2][j],...,F[i][j-1]+F[j][j]}
F[1,n]为所求的解
时间复杂度:o(N^3);
此题需要选手对算法的时间复杂度进行分析, 简单的搜索是不能在规定时间内求出结果, 必
需使用高效的算法,主要考查选手运用高效算法——动态规划解决问题的能力
1 #include<iostream> 2 #include<cstdio> 3 #include<algorithm> 4 #include<cmath> 5 #include<cstring> 6 #include<vector> 7 #include<queue> 8 using namespace std; 9 int n,ans,a[505],f[505][505]; 10 int main() 11 { 12 freopen("remove.in","r",stdin); 13 freopen("remove.out","w",stdout); 14 scanf("%d",&n); 15 for(int i=1;i<=n;i++) 16 { 17 scanf("%d",&a[i]); 18 f[i][1]=a[i]; 19 } 20 for(int j=2;j<=n;j++) 21 for(int i=1;i<=n-j+1;i++) 22 { 23 f[i][j]=j*fabs(a[i]-a[i+j-1]); 24 for(int k=1;k<j;k++) 25 f[i][j]=max(f[i][j],f[i][k]+f[k+i][j-k]); 26 } 27 for(int i=1;i<=n;i++)ans=max(ans,f[i][n]); 28 printf("%d",ans); 29 return 0; 30 }
11、组合数
【题目描述】
最近老师教了小明怎么算组合数,小明又想到了一个问题。 。 。
小明定义 C(N,K)表示从 N 个元素中不重复地选取 K 个元素的方案数。
小明想知道的是 C(N,K)的奇偶性。
当然,这个整天都老是用竖式算 123456789*987654321=?的人不会让你那么让自己那
么轻松,它说: “N 和 K 都可能相当大。 ”
但是小明也犯难了,所以它就找到了你,想请你帮他解决这个问题。
【输入描述】
输入文件:comb.in
第 1 行:一个正整数 t,表示数据的组数。
第 2~2+t-1 行:两个非负整数 N 和 K。 (保证 k<=n)
【输出描述】
输出文件:comb.out
对于每一组输入,如果 C(N,K)是奇数则输出 1,否则输出 0。
【样例输入】
3
1 1
1 0
2 1
【样例输出】
1
1
0
【数据范围】
对于 30% 的数据,n<=10^2 t<=10^4
对于 50% 的数据,n<=10^3 t<=10^5
对于 100%的数据,n<=10^8 t<=10^5
【预备知识 】
C(n, 0) = C(n, n) = 1 (n > 0;)
C(n, k) = C(n − 1, k − 1) + C(n − 1, k) (0 < k < n)
Solution:
如果本题你还思维定式的用高精度计算,那你就完蛋了。 (可以得部分分)
本题主要考察数学知识。
方法一:统计 n!质因子中 2 的个数
n! = 2^a * M
a=[n/2]+[n/(2^2)]+[n/(2^3)]+ ... +[n/(2^g)] (2^(g+1)>n>=2^g)
证明:加法原理
所以 C(N)K 质因子中 2 的个数为 F = f(N) - f(K) - f(N - K)
若 F 大于 0,则为偶数,等于零为奇数。
*方法二:由 Lucas 定理得当 k==(k&n)时为奇数,否则为偶数。
1 #include <cstdio> 2 #include <cstring> 3 #include <iostream> 4 using namespace std; 5 int t,n,k; 6 int gi() { 7 int a=0;bool f=0;char c=getchar(); 8 while (c>'9'||c<'0') {if (c=='-') f=1;c=getchar();} 9 while (c>='0'&&c<='9') {a=a*10+c-'0';c=getchar();} 10 return f?-a:a; 11 } 12 13 int main() { 14 freopen("comb.in","r",stdin); 15 freopen("comb.out","w",stdout); 16 t=gi(); 17 int ans; 18 while (t--) { 19 n=gi();k=gi(); 20 ans=(n&k)==k?1:0; 21 cout<<ans<<endl; 22 } 23 return 0; 24 }
12、偶数
【题目描述】
山山有一个长度为 N 的序列。当序列中存在相邻的两个数的和为偶数的话,LGTB 就
能把它们删掉。
山山想让序列尽量短,请问能将序列缩短到几个数?
【输入格式】
第一行包含一个数 N 代表序列初始长度。
接下来一行包含 N 个数 a1 ,a2 ,...,aN ,代表序列。
【输出格式】
输出包含一个数代表操作后序列最短长度
【样例输入】
10
1 3 3 4 2 4 1 3 7 1
【样例输出】
2
【数据范围】
对于 50% 的数据,1 ≤ N ≤ 1000
对于 100% 的数据,1 ≤ N ≤ 10 5 ,0 ≤ ai ≤ 10 9
Solution:
考虑到连续的一段奇偶性相同的数字才能被删除,所以直接贪心即可,用栈实现
1 #include<iostream> 2 #include<cstdio> 3 #pragma GCC optimize(2) 4 using namespace std; 5 #define ll long long 6 #define il inline 7 ll a[100005],s[100005]; 8 il ll gi() 9 { 10 ll a=0;char x=getchar();bool f=0; 11 while((x<'0'||x>'9')&&x!='-')x=getchar(); 12 if(x=='-')x=getchar(),f=1; 13 while(x>='0'&&x<='9')a=a*10+x-48,x=getchar(); 14 return f?-a:a; 15 } 16 int main() 17 { 18 freopen("even.in","r",stdin); 19 freopen("even.out","w",stdout); 20 ll n=gi(),t=0; 21 for(int i=1;i<=n;i++){ 22 a[i]=gi(); 23 if(!t)s[++t]=a[i]; 24 else if(s[t]+a[i]&1)s[++t]=a[i]; 25 else t--; 26 } 27 cout<<t; 28 return 0; 29 }
13、序列
【题目描述】
山山有一个长度为 N 的序列 A,现在他想构造一个新的长度为 N 的序列
B,使得 B 中的任意两个数都互质。
并且他要使 最小。
请输出最小值。
【输入格式】
第一行包含一个数 N 代表序列初始长度
接下来一行包含 N 个数 A1 , A2 ,..., AN ,代表序列 A
【输出格式】
输出包含一行,代表最小值
【样例输入】
5
1 6 4 2 8
【样例输出】
3
【样例说明】
样例中 B 数组可以为 1 5 3 1 8
【数据范围】
对于 40% 的数据,1 ≤ N ≤ 10
对于 100% 的数据,1 ≤ N ≤ 100,1 ≤ ai ≤ 30
Solution:
考虑到ai最多变成58,如果变成更大的数还不如变成1,而且58之内只有16个素数
并且可以证明对于两个数a > b,变成的数A >= B
所以最多只有16个最大的数变成素数,其他的数都会变成1
所以直接对于前16个数dp,dp[i][j]代表到第i个数,哪些素因子被用过了,花费最少为多少。枚举一个数来转移即可
1 #include<iostream> 2 #include<cstdio> 3 #include<algorithm> 4 #include<cmath> 5 #include<cstring> 6 using namespace std; 7 #define smax(x,tmp) x=max((x),(tmp)) 8 #define smin(x,tmp) x=min((x),(tmp)) 9 const int INF=0x3f3f3f3f; 10 const int prime[] = {0,2,3,5,7,11,13,17,19,23,29,31,37,41,43,47,53}; 11 int n,a[105],f[17][1<<17],pdd[105]; 12 inline bool cmp(int a,int b){return a>b;} 13 int main() 14 { 15 freopen("seq.in","r",stdin); 16 freopen("seq.out","w",stdout); 17 scanf("%d",&n); 18 for(int i=1;i<=n;i++)scanf("%d",&a[i]); 19 sort(a+1,a+n+1,cmp); 20 for(int i=1;i<=58;i++) 21 for(int j=1;j<=16;j++) 22 if(i<prime[j])break; 23 else if(i%prime[j]==0)pdd[i]|=(1<<j-1); 24 memset(f,0x3f,sizeof(f)); 25 f[0][0]=0; 26 for(int i=1;i<=min(n,16);i++) 27 for(int j=0;j<(1<<16);j++) 28 for(int k=1;k<=58;k++) 29 if(!(pdd[k]&j))smin(f[i][j|pdd[k]],f[i-1][j]+abs(a[i]-k)); 30 int ans=INF; 31 for(int j=0;j<(1<<16);j++)smin(ans,f[min(n,16)][j]); 32 if(n>16)for(int i=17;i<=n;i++)ans+=abs(a[i]-1); 33 printf("%d",ans); 34 return 0; 35 }