1.新建项目
scrapy startproject book_project
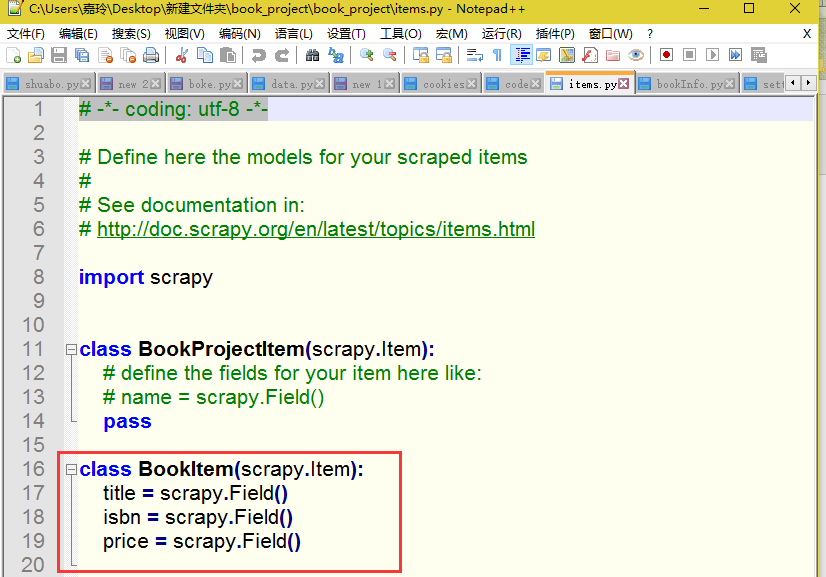
2.编写items类
3.编写spider类


# -*- coding: utf-8 -*- import scrapy from book_project.items import BookItem class BookInfoSpider(scrapy.Spider): name = "bookinfo"#定义爬虫的名字 allowed_domains = ["allitebooks.com", "amazon.com"]#定义爬取的范围 start_urls = [ "http://www.allitebooks.com/security/", ] def parse(self, response): num_pages=int(response.xpath('//span[contains(@class,"pages")]/text()').extract_first().split()[-2]) base_url = "http://www.allitebooks.com/security/page/{0}/" for page in range(1, num_pages): yield scrapy.Request(base_url.format(page), dont_filter=True, callback=self.parse_page) #open('my.txt', 'wb').write(page) def parse_page(self, response): for sel in response.xpath('//div/article'): book_detail_url = sel.xpath('div/header/h2/a/@href').extract_first() yield scrapy.Request(book_detail_url, callback=self.parse_book_info) def parse_book_info(self, response): title = response.css('.single-title').xpath('text()').extract_first() isbn = response.xpath('//dd[2]/text()').extract_first() item = BookItem() item['title'] = title item['isbn'] = isbn # yield item amazon_search_url = 'https://www.amazon.com/s/ref=nb_sb_noss?url=search-alias%3Daps&field-keywords=' + isbn yield scrapy.Request(amazon_search_url, headers={'User-agent': 'Mozilla/5.0'}, callback=self.parse_price, meta={ 'item': item }) def parse_price(self, response): item = response.meta['item'] item['price'] = response.xpath('//span/text()').re(r'$[0-9]+.[0-9]{2}?')[0] yield item
4.启动爬虫开始抓取
scrapy crawl bookinfo -o books.csv
5.运行结果

看出来运行了很久,大概有25分钟
csv中的数据
