GAWK:报告生成器,格式化文本输出
awk [options] ‘program’ var=value file…
awk [options] -f programfile var=value file…
awk [options] 'BEGIN{ action;… } pattern{ action;… } END{ action;… }' file ...
awk程序组成部分:
BEGIN语句块、能够使用模式匹配的通用语句块、END语句块
选项:
-F:指明输入时用到的字段分割符;
-v var=value:自定义变量
-f:指定awk脚本,从脚本中读取program
基本格式:
awk [options] 'program' file...
program:pattern{action statements;...} 通常在单引号或双引号中;
pattern与action:
pattern部分决定动作语句何时触发及事件
BEGIN:模式匹配之前要执行的动作
END:模式匹配结束之后要执行的动作
action statements对数据进行处理,放在{}内指明;
print $0,$!.......$(NF-1)........$NF(最后一列)
分隔符,域,记录:
awk执行时,由分隔符分隔的字段(域)标记$1,$2...$n称为域标识。$0为所有域。
文件的每一行称为记录;
省略action,则默认执行print $0的操作;
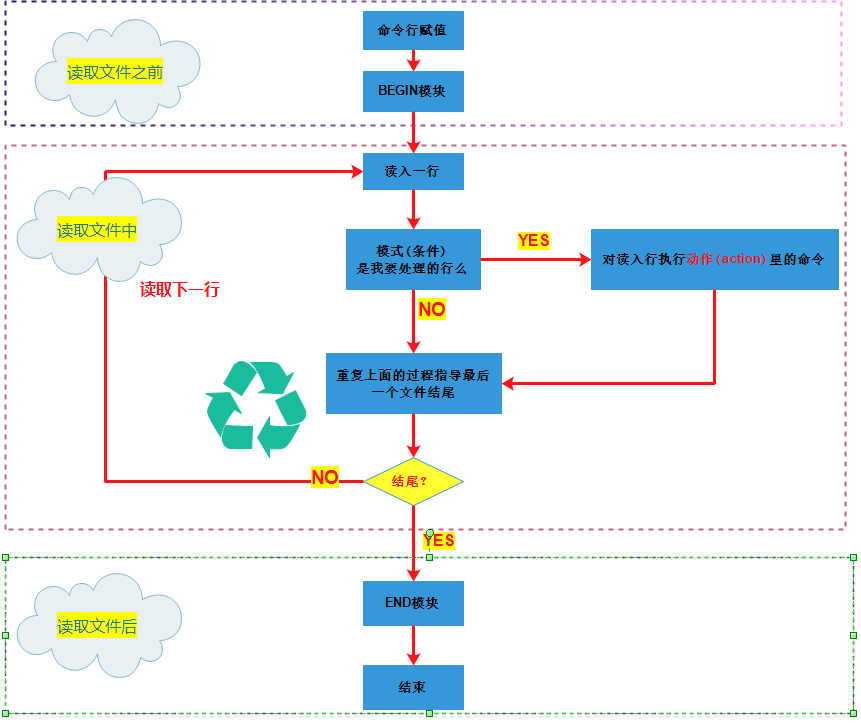
awk的工作原理:
1)、执行BEGIN{action;...}语句块中的语句;
2)、从文件或标准输入(stdin)读取一行,然后执行pattern{action;...}语句块,它会逐行扫描文件,从第一行到最后一行重复这个过程,知道文件被全部读取完毕;
3)、当读至输入流末尾时,执行END{action;...}语句块
BEGIN语句块:在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常 可以写在BEGIN语句块中。
END语句块:在awk从输入流中读取完所有的行之后即被执行,比如 打印所有行的分析结果这类信息汇总都是在END语句块中完成它也是一个可选语句块
pattern语句块中的通用命令是最重要的部分,也是可选的。如果 没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块
print格式:print item1,item2,...
1)、逗号为分隔符;
2)、输出的个item可以是字符串,也可以是当前记录的字段、变量或awk的表达式;
3)、如省略item,相当于print $0;
awk '{print "hello,awk"}' awk –F: '{print}' /etc/passwd # -F指定分割符为 :冒号 awk –F: '{print “wang”}' /etc/passwd
awk –F: '{print $1}' /etc/passwd awk –F: '{print $0}' /etc/passwd awk –F: '{print $1” ”$3}' /etc/passwd tail –3 /etc/fstab |awk '{print $2,$4}'
变量:
FS:输入字段分隔符,默认为空白字符;
awk -v FS=':' '{print $1,FS,$3}' file
OFS:输出字段分隔符,默认为空白字符;指定输出时的分隔符是什么,一般可以进行分隔符号替换,类似下面的ORS的作用
awk -v FS=':' -v OFS=':' '{print $1,$2,$3}' file
[root@mysql-141 ~]# awk -v FS=':' -v OFS='#' '{print $1,$2,$3}' /etc/passwd
root#x#0
bin#x#1
daemon#x#2
adm#x#3
RS:输入记录分隔符,指定输入时的换行符,原换行符仍有效;
awk -v RS=' ' '{print}' file
ORS:输出记录分隔符,输出时用指定符号代替换行符;
awk -v RS=' ' -v ORS='$$$' '{print}' file
NF:字段数量
awk -F: '{print NF}' file awk -F: '{print $(NF-1)}' file
# 显示文件的第一列,第三列,倒数第二列和最后一列
[root@mysql-141 ~]# awk -F : '{print $1,$2,$(NF-1),$NF}' /etc/passwd
root x /root /bin/bash
bin x /bin /sbin/nologin
daemon x /sbin /sbin/nologin
adm x /var/adm /sbin/nologin
NR:行号
awk -F: '{print NR,$1}' file # 与FNR类似 awk END'{print NR}' file
[root@mysql-141 ~]# awk END'{print NR}' /etc/passwd #将文件内容读取完成之后,统计行数
26
awk 'NR==2,NR==6{print NR,$0}}' file #显示文件2-6行
FNR:各文件的行号分别计数;
awk -F: '{print FNR,$1}' file1 file2...
[root@mysql-141 ~]# awk -F: '{print FNR,$1}' /etc/passwd
1 root
2 bin
3 daemon
4 adm
5 lp
6 sync
7 shutdown
8 halt
FILENAME:当前文件名;文件内容有多少行,awk就会输出多少行
awk '{print FILENAME}' FILE1 FILE2...
[root@mysql-141 ~]# awk '{print FILENAME}' /etc/passwd |wc -l
26
[root@mysql-141 ~]# wc -l /etc/passwd
26 /etc/passwd
ARGV:数组,保存的是命令行所给定的各参数;
awk 'BEGIN {print ARGV[0]}' /etc/fstab /etc/inittab awk 'BEGIN {print ARGV[1]}' /etc/fstab /etc/inittab
[root@mysql-141 ~]# awk 'BEGIN {print ARGV[1]}' /etc/fstab /etc/inittab # 相当于shell里面的$1 $2 $3 的概念
/etc/fstab
[root@mysql-141 ~]# awk 'BEGIN {print ARGV[2]}' /etc/fstab /etc/inittab
/etc/inittab
[root@mysql-141 ~]# awk 'BEGIN {print ARGV[0]}' /etc/fstab /etc/inittab
awk
[root@mysql-141 ~]# awk 'BEGIN {print ARGV[3]}' /etc/fstab /etc/inittab
算术操作符:
x+y x-y x*y x/y x^y x%y
-x:转换为负数;
+x:转换为数值,变量通过+连接运算,自动强制将字符串转为整形,非数字变成0,发现第一个非数字字符,后面的自动忽略;
字符串操作符:没有符号的操作符,字符串连接
赋值操作符:
= += -= *= /= %= ^= ++ --
比较操作符:
== != > >= < <=
模式匹配符:
~:左边的内容是否被右边的模式包含匹配
!~:是否不匹配;
[root@mysql-141 ~]# awk -F: '$0 ~ /root/{print $1}' /etc/passwd # 以:为分隔符,匹配全部内容包含root的行,打印第一列
root
operator
[root@mysql-141 ~]# awk '$0 ~ "^root"' /etc/passwd # 匹配所有内容,期初以root开头的行
root:x:0:0:root:/root:/bin/bash
[root@mysql-141 ~]# awk -F: '$3==0' /etc/passwd # 匹配以冒号为分隔符,第三列是0的行
root:x:0:0:root:/root:/bin/bash
cat >>/tmp/reg.txt<<EOF Zhang Dandan 41117397 :250:100:175 Zhang Xiaoyu 390320151 :155:90:201 Meng Feixue 80042789 :250:60:50 Wu Waiwai 70271111 :250:80:75 Liu Bingbing 41117483 :250:100:175 Wang Xiaoai 3515064655 :50:95:135 Zi Gege 1986787350 :250:168:200 Li Youjiu 918391635 :175:75:300 Lao Nanhai 918391635 :250:100:175 EOF

操作符:
与&&
或||
非!
示例:
[root@mysql-141 ~]# awk -F : '$3>=0 && $3<=1000 {print $1}' /etc/passwd
root
bin
daemon
adm
lp
[root@mysql-141 ~]# awk -F : '$3==0 || $3>=1000 {print $1}' /etc/passwd
root
[root@mysql-141 ~]# awk -F : '!($3==0) {print $1}' /etc/passwd
bin
daemon
adm
lp
[root@mysql-141 ~]# awk -F : '!($3>=500) {print $3}' /etc/passwd
0
1
2
3
4
5
6
awk PATTERN:
1)、如果未指定:空模式,匹配每一行;
2)、/regular expression/:仅处理能够被模式匹配到的行,需要用//括起来;
awk '/^UUID/{print $1}' /etc/passwd awk '!/^UUID/{print $1}' /etc/passwd
3)、relational expression:关系表达式,结果未"真"才会被处理;
真:结果为非0值,非空字符串;
假:结果为空字符串或0值;
awk -F : 'i=1;j=1{print i,j}' /etc/passwd awk '!0' /etc/passwd ; awk '!1' /etc/passwd awk –F : '$3>=1000{print $1,$3}' /etc/passwd awk -F : '$3<1000{print $1,$3}' /etc/passwd
[root@mysql-141 ~]# awk -F : '$NF=="/bin/bash"{print $1,$NF}' /etc/passwd
root /bin/bash
lipeng /bin/bash
[root@mysql-141 ~]# awk -F : '$NF ~ /nologin$/{print $1,$NF}' /etc/passwd
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
mail /sbin/nologin
uucp /sbin/nologin
4)、line ranges:行范围:
startline,endine:/pat1/,/pat2/ 不支持直接给出数字格式:
[root@mysql-141 ~]# awk -F: '/^root>/,/^nobody>/{print $1}' /etc/passwd root bin daemon adm lp nobody [root@mysql-141 ~]# awk -F: '(NR>=10&&NR<=20){print NR,$1}' /etc/passwd 10 uucp 11 operator 12 games 13 gopher 14 ftp
awk数组概念:
预备知识: 了解两种awk运算方法
1) 累加运算 1+1+1
i=i+1 i初始状态为0
i++
eg: 统计/etc/services文件中空行数量
第一个里程: 找出文件中空行信息
awk '/^$/' /etc/services
第二个里程: 统计空行数量
awk '/^$/{i=i+1;print i}' /etc/services
PS: awk中所有字符串信息都会识别为变量名称信息, 调取变量是不需要加上$符号
awk中想显示指定字符串信息, 需要在字符串外面加上双引号信息
[root@oldgirl ~]# awk '/^$/{i=i+1;print i}' /etc/services 1 # i=i+1 i=0 i=0+1 --> i=1 2 # i=i+1 i=1 i=1+1 --> i=2 3 # i=2 i=2+1 --> i=3 4 5 6 7 8 9 10 11 12 13 14 15 16
[root@oldgirl ~]# awk '/^$/{i=i+1}END{print i}' /etc/services # 将文件内容加载完之后,做出统计 16
2) 求和运算 10+20+5
i=i+$n i的初始状态为0 $n取第几列数值信息
[root@oldgirl ~]# seq 10|awk '{i=i+$0;print i}' 1 i=i+$0 i=0 $0=1 i=0+1 -- 1 1 2 i=i+$0 i=1 $0=2 i=1+2 -- 3 3 3 i=i+$0 i=3 $0=3 i=3+3 -- 6 6 4 10 5 15 6 21 7 28 8 36 9 45 10 55
[root@mysql-141 ~]# seq 10|awk '{i=i+$0;print i}'
1
3
6
10
15
21
28
36
45
55
3). 数组的表现形式
数组中的括号里面的内容
hotel[元素01]=xiaolizi1 --- 调用print xiaolizi1[元素01]--- xiaolizi1
hotel[元素02]=xiaolizi2 --- 调用print xiaolizi2[元素02]--- xiaolizi2
数组统计命令组成说明:
1) 找出要统计的信息
$1
2) 把指定要统计信息作为数组的元素
h[$1]
3) 利用统计运算公式,进行运算
h[$1]=h[$1]+1 --- i=i+1
4) 显示运算的结果信息
a 只看某一个元素的结果信息
awk '{h[$1]=h[$1]+1}END{print h["101.226.61.184"]}' access.log 5
b 要看全部元素的结果信息
awk '{h[$1]=h[$1]+1}END{print h["101.226.61.184"],h["114.94.29.165"]}' access.log
# 精简后命令
awk '{h[$1]++}END{for(name in h)print name,h[name]}' access.log
for name in 101.226.61.184 114.94.29.165
print h[$name]
==>
for(name in h) --- > echo name=h=第一个元素信息
echo name=h=第二个元素信息
说明: 循环中读取数组名称==读取每一个元素名称信息
cat >>url.txt<<EOF http://www.etiantian.org/index.html http://www.etiantian.org/1.html http://post.etiantian.org/index.html http://mp3.etiantian.org/index.html http://www.etiantian.org/3.html http://post.etiantian.org/2.html EOF awk '{h[$1]++}END{for(name in h)print name,h[name]}' access.log
[root@mysql-141 ~]# awk '{h[$1]++}END{for(name in h)print name,h[name]}' access.log
101.226.61.184 5
27.154.190.158 2
218.79.64.76 2
114.94.29.165 1
第一步: 定义数组信息 awk '{h[$1]}' access.log 说明: 数组中的元素就是你关注要统计的列的信息 第二步: 进行统计运算,编写公式 awk '{h[$1]=h[$1]+1}' access.log 第三步: 编写元素循环信息 awk '{h[$1]=h[$1]+1}END{for(name in h)}' access.log 第四步: 输出结果信息 awk '{h[$1]=h[$1]+1}END{for(name in h) print name,h[name]}' access.log
将文本内容格式化输出
原文如下:
job_name job_group
syncCommStockJob dataSync
syncStoreChnlJob dataSync
syncOrderJob dataSync
syncReportStoreJob dataSync
hdfsScanJob report
orderSaleDailyJob report
jdzmdOrdersJob report
jdCanJob report
使用awk格式化输出后
cat xxx.txt | awk '{printf "%-30s%-15s
",$1,$2}'
#%-30s表示输出字符串,宽度30位(字符串如果过长,可以自己调整),左对齐.%-15s用来指定第二列的,左对齐,宽度15.两个百分号之间可以没有空格.使用
对每一行的输出加上换行符
job_name job_group
syncCommStockJob dataSync
syncStoreChnlJob dataSync
syncOrderJob dataSync
syncReportStoreJob dataSync
hdfsScanJob report