目录结构
1、应用场景及作用
2、结构关系
2.1、三者关系类图
2.2、ThreadLocalMap结构图
2.3、 内存引用关系
2.4、存在内存泄漏原因
3、源码分析
3.1、重要代码片段
3.2、重要方法分析
3.3、set(T): void
3.4、get():T
3.5、remove():void
3.6、总结
1、应用场景及作用
-1作用、ThreadLocal 为了实现线程之间数据隔离,每个线程中有独立的变量副本,操作互不干扰。区别于线程同步中,同步在为了保证正确使用同一个共享变量,需要加锁。
-2应用场景:
1)可以对一次请求过程,做一个过程日志追踪。如slf4j的MDC组件的使用,可以在日志中每次请求过程加key,方便定位一次请求流程问题。
2)解决线程中全局数据传值问题。
2、结构关系
要理清ThreadLocal的原理作用,可以先了解Thread, ThreadLocal, ThreadLocalMap三者之间的关系。简单类图关系如下
2.1、三者关系类图

1、Thread 类中有ThreadLocalMap类型的成员变量 threadLocals
2、ThreadLocalMap是ThreadLocal的静态内部类
3、Thread 与 ThreadLocal怎么关联?
线程对象中threadLocals中存储的键值对 key--> ThreadLocal对象,value --> 线程需要保存的变量值
2.2、ThreadLocalMap结构图
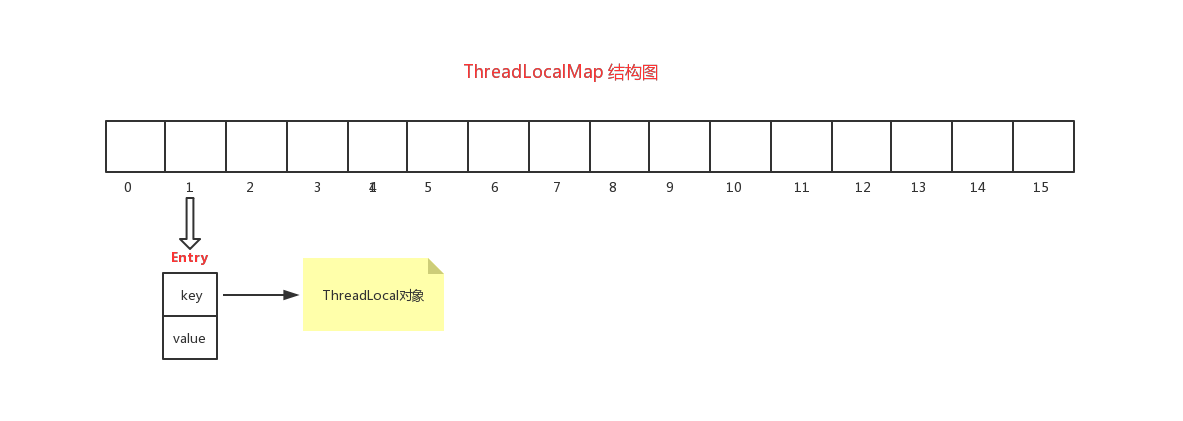
ThreadLocalMap 底层实现实质是一个Entry对象数组, 默认容量是16,在存储元素到数组中,自己实现了一个算法来寻址(计算数组下标), 与Map集合中的HashMap有所不同。 Entry对象中 key是ThreadLocal对象。
误区:在不了解原理前,会想线程之间要实现数据隔离,那这个集合中key应该是Thread对象,这样在存的时候,以当前线程对象为key,value为要保存的值,这样在获取的时候,通过线程对象去get获取相应的值。
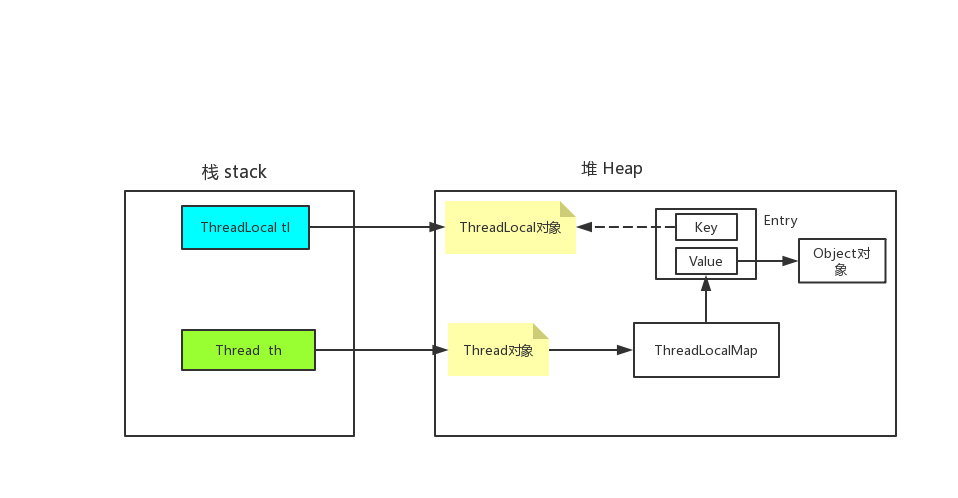
2.3、 内存引用关系

-1,同一个ThreadLocal对象可被多个线程引用,每个线程之间本地变量副本存储,实现数据独立性,可见每个线程内部都有单独的map集合,即使引用的ThreadLocal同一个,value可以不同,如图中ThreadLocal1对象,同时被线程A,B引用作为key
-2,一个线程可以存储多个ThreadLocal,因线程中存储的只能存储同一个ThreadLocal对象一次,再次存储相同的Threadlocal对象,因为key相同,会覆盖原来的value,value可以是基本数据类型的值,也可以是引用数据类型(如封装的对象)
2.4、存在内存泄漏原因
ThreadLocal对象没有外部强引用后,只存在弱引用,下一次GC会被回收。如下:
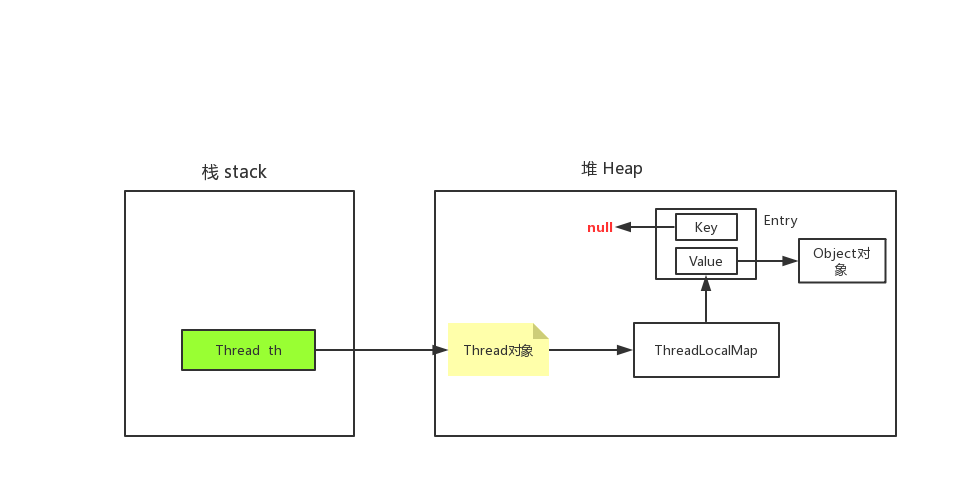
-1,上图实线箭头代表强引用,虚线代表弱引用; JVM存在四种引用:强引用,软引用,弱引用,虚引用,弱引用对象,会在下一次GC(垃圾回收)被回收。
-2,上图可见Entry的 Key指向的ThreadLocal对象的引用是弱引用,一旦tl的强引用断开,没有外部的强引用后,在下一次JVM垃圾回收时,ThreadLocal对象被回收了,此时 key--> null,而此时 Entry对象,是有一条强引用链的,th-->
Thread对象-->ThreadLocalMap--> Entry,可达性性分析是可达的,这时ThreadLocalMap集合,即在数组的某一个索引是有Entry引用的,但是该Entry的key为null,value依然有值,但再也用不了了,这时的Entry称为staleEntry(我理解为失效的Entry),造成内存泄漏。
-3,内存泄漏是指分配的内存,gc回收不了,自己也用不了; 内存溢出,是指内存不够,如有剩余2M内存,这时有一个对象创建需要3M,内存不够,导致溢出。内存泄漏可能会导致内存溢出,因为内存泄漏就会有人占着茅坑不拉屎,可用空间越来越少,gc也回收不了,最终导致内存溢出。
-4,那线程对象被回收了,这条引用链断了就没事了,下次Gc就会把ThreadLocalMap集合中对象全部回收了,就不存在内存泄漏问题了;但开发环境,线程一般会在线程池创建来节约资源,每个线程是被重复使用的,生命周期很长,线程对象长时间是存在内存中的,而ThreadLocalMap和Thread生命周期相同,只有线程结束,它内部持有的ThreadLocalMap对象才会销毁,如下Thread#exit:
private void exit() {
if (group != null) {
group.threadTerminated(this);
group = null;
}
/* Aggressively null out all reference fields: see bug 4006245 */
target = null;
//线程退出时,才断开ThreadLocalMap引用
threadLocals = null;
inheritableThreadLocals = null;
inheritedAccessControlContext = null;
blocker = null;
uncaughtExceptionHandler = null;
}
3、源码分析
本次源码分析,主要分析ThreadLocal的set,get,remove三个方法,分别以此为入口,一步步深入每个代码方法查看其实现原理,在这分析之前,先捡几个我理解比较重要的方法或者代码片段先解释一下,有一个初步的理解,后面会更顺畅。
3.1、重要代码片段
//一、ThreadLocalMap的寻址,因其底层是数组,在存放元素如何定位索引i存储?
//两个要求:1)求的索引位置一定要在数组大小内
// 2)索引足够均分分散,要求hashcode足够散列,目的减少hash冲突。
//firstKey.threadLocalHashCode,就是为了达到要求2,均分分散
// &(INITIAL_CAPACITY - 1) 为了落在数组范围内,常用进行模运算,这里是巧妙运用位运算,效率更高, %2^n与 &(2^n-1)等价,所以要求数组的容量要为2的幂;
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
// -------------------> firstKey.threadLocalHashCode,
//传入的ThreadLocal对象,做了 0x61c88647的增量后求得hash值,为什么要加0x61c88647呢,与斐波那契数列有关,反正是一个神奇的魔法值,目的就是使的hash值更分散,减少hash冲突。
private final int threadLocalHashCode = nextHashCode();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
//二、如何ThreadLocalMap中,出现hash冲突了,即2个ThreadLocal对象的hash计算出来是相同的下标,这里解决hash冲突使用线性探测法,即这个位置冲突,就寻找下一个位置,如果到数组终点了呢,从0再开始,所以这里数组逻辑上是一个首尾相接的环形数组。
//1,向后遍历,获取索引位置
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
//2,向前遍历
private static int prevIndex(int i, int len) {
return ((i - 1 >= 0) ? i - 1 : len - 1);
}
如下图:

3.2、重要方法分析
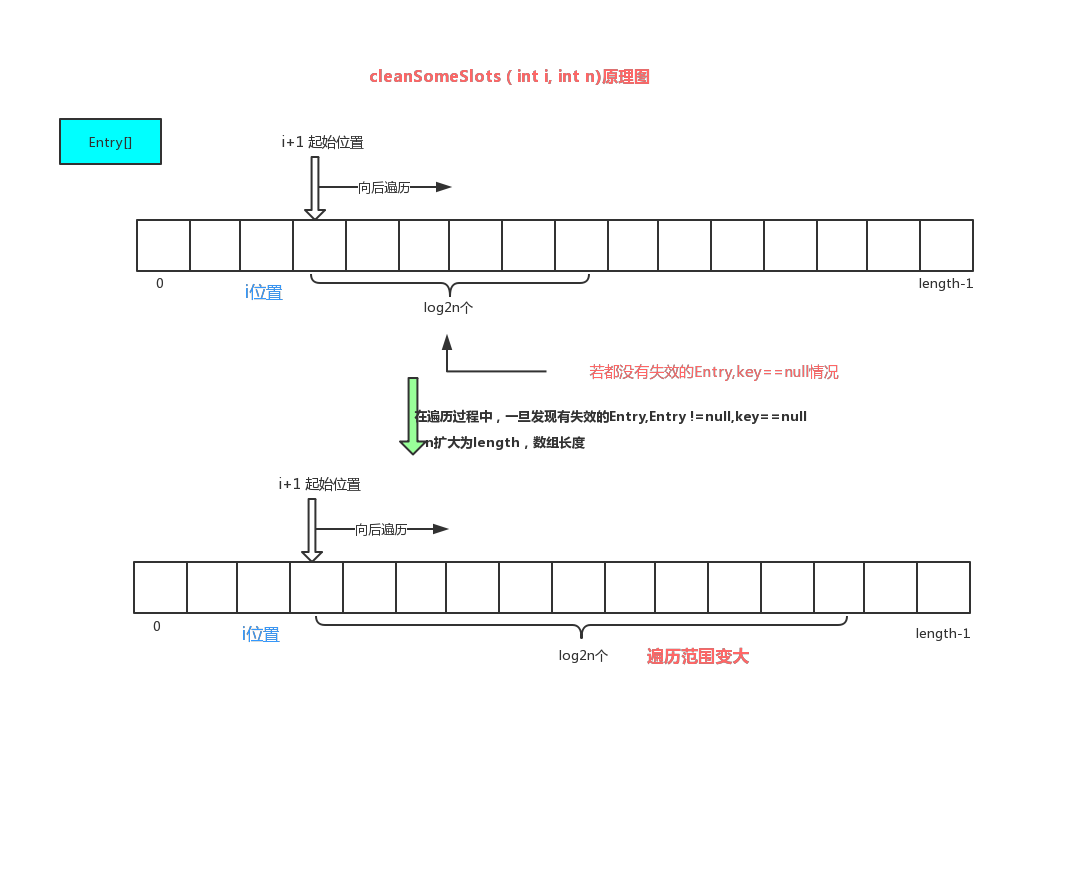
cleanSomeSlots 原理图1如下:
//一,分析清理失效Entry方法,清理起始位置是staleSlot
//已经知道某个Entry的key==null了,那么数组该位置的引用应该被清除
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
//Entry的value引用也清除,方便gc回收
tab[staleSlot].value = null;
// 清理数组当前位置的Entry
tab[staleSlot] = null;
size--;
// Rehash until we encounter null
Entry e;
int i;
//向后循环遍历,直到遇到 null
//做2件事:
//1)遇到其他失效Entry,顺手清除
//2)没有失效的Entry,重新hash一下,安排新位置;因为可能之前某些位置有hash冲突,导致根据key生成hash的值与当前的位置i不一致(冲突,会往后顺延,这里是逻辑上往后,达到数组长度,从0开始),而这时又清理了不少失效的Entry,可能会有空位了,所以重新hash调一下顺序,提高效率。
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
//1,失效Entry,清除
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
//2,hash值与当前数组索引位置不同
if (h != i) {
tab[i] = null;
//3,向后遍历,找合适空位置插入
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
//返回i位置, Entry ==null
return i;
}
//二、可伸缩性遍历某段范围失效的Entry cleanSomeSlots(int i, int n),原理如上图1
//为什么要有伸缩性,我理解还是为了效率,如果发现这范围内有需要清理的失效Entry,才把范围放大一些查找清除,源代码如下:
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
Entry e = tab[i];
// 遇见有失效的Entry,当n传入的是size,即数组实际容纳的数量,n扩大到数组长度了,
//影响在于,原来清理遍历的只是数组的一个小范围,一下子扩大到了整个数组。我理解这样做为了提高执行效率,没有检测到失效entry就小范围清理一下,检测到就大范围清理。
if (e != null && e.get() == null) {
n = len;
removed = true;
i = expungeStaleEntry(i);
}
// n >>>= 1,即 n向右位移1位,即 n/2, 可循环次数log2n次
} while ( (n >>>= 1) != 0);
return removed;
}
//三、当在set时,发现当前生成的数组位置已经被其他Entry占了,但是它失效了,key==null,这时需要把它给替换了吧,replaceStaleEntry(ThreadLocal<?> key, Object value,int staleSlot),较难理解,多看几遍哈,原理图看下面,分析了2种情况,还有前后遍历都发现有失效的Entry情况,请自行脑补了哈。
//源代码如下:
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
// 1,要清除的位置
int slotToExpunge = staleSlot;
//2,从i 向前遍历,找到左边第一个失效的位置(指的是Entry !=null,key==null)
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
//3,从i向后遍历
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
//4,传入 staleSlot的 key==null,是一个失效的Entry, 从staleSlot+1个向后遍历,如果
//遇见 k==key,将staleSlot索引位置与此处i替换位置,即将失效的Entry往后面放
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
// Start expunge at preceding stale entry if it exists
//如果相等,staleSlot左边没有失效的entry,赋值为此处i,此处已经替换为失效Entry了,如果不相等,那么就清除失效Entry,以staleSlot最左边那一个失效entry开始清除
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
//cleanSomeSlots的目的:expungeStaleEntry返回的是entry ==null的索引i,
//清理i到len这一段的失效entry,中间会有null的情况吗?
return;
}
//5,slotToExpunge == staleSlot 表示 左边没有失效entry, 右边遇见第一失效entry,标记此处索引,以便后文确定从哪里开始清除无效entry
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
//解除value的引用,gc会回收
tab[staleSlot].value = null;
//数组失效Entry位置,赋值新的Entry
tab[staleSlot] = new Entry(key, value);
//6,不相等,肯定有失效索引需要清理,执行清除
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
replaceStaleEntry 情景图1如下:
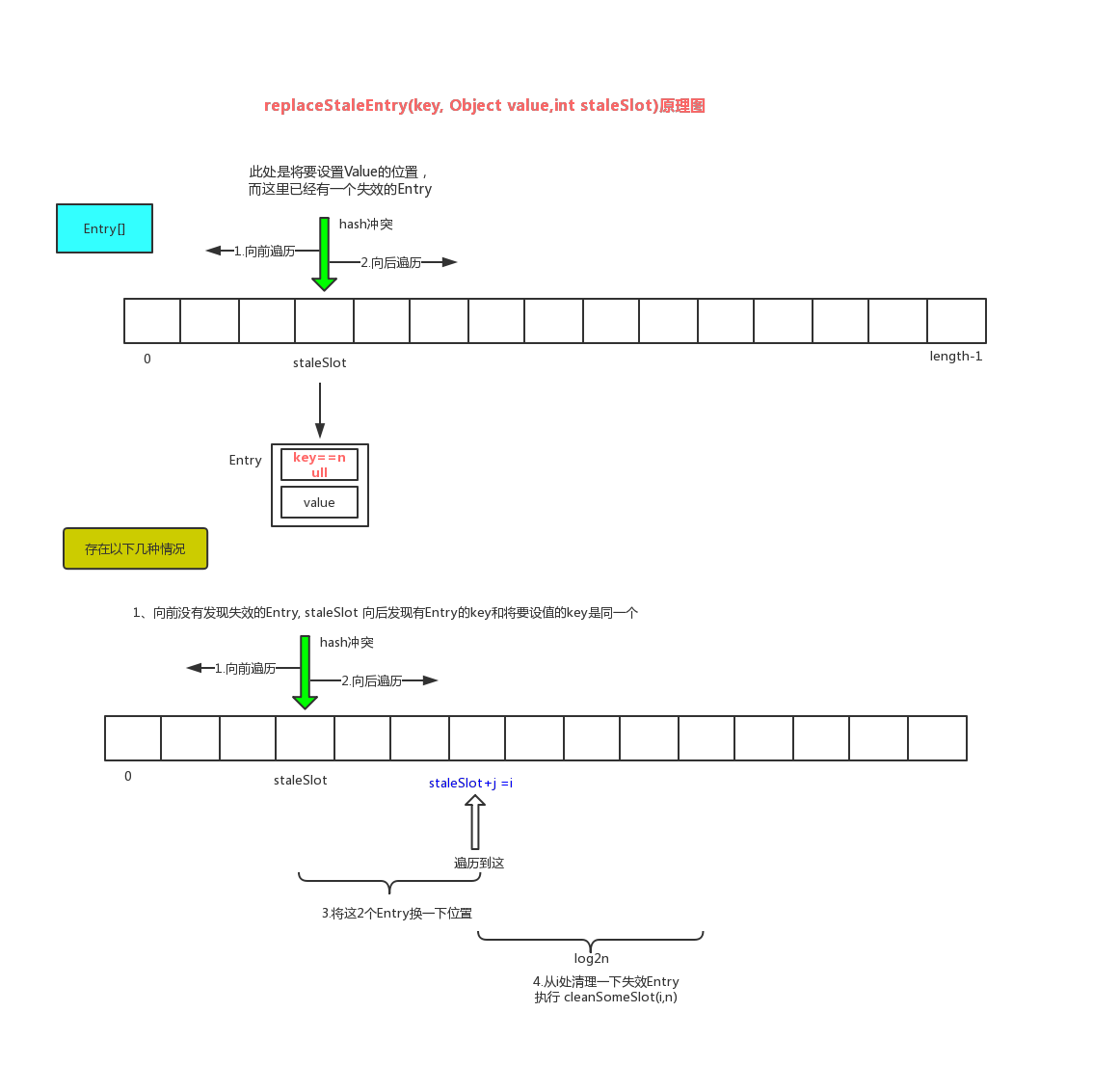
replaceStaleEntry 情景图2如下:

3.3、set(T): void
set 方法,是代码最多的,也是最重要的。其中expungeStaleEntry, replaceStaleEntry,cleanSomeSlots 三个方法较为主要,目的是找出、清理失效的Entry的过程,其中replaceStaleEntry 较难理解。
//一、从 set() 着手,入口
public void set(T value) {
//1,获取当前线程对象
Thread t = Thread.currentThread();
//2,获取当前线程的map, 每个线程持有一个threadLocals对象,通过该map来实现线程之间数据的隔离,达到每个线程拥有自己独立的局部变量。 见代码分析二
ThreadLocalMap map = getMap(t);
if (map != null)
// 见代码分析四
map.set(this, value);
else
//3,如果当前线程持有的map为空,创建map,见代码分析三
createMap(t, value);
}
//二、 获取ThreadLocalMap 方法,获取当前线程持有的map对象
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
// Thread类中持有hreadLocalMap类型的对象,该map是ThreadLocal的静态内部类
ThreadLocal.ThreadLocalMap threadLocals = null;
//三、代码分析
void createMap(Thread t, T firstValue) {
// 创建 map对象,下见ThreadLocalMap的构造方法,很关键,该map与常用的HashMap等不同
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
//构造方法,ThreadLocalMap 能够实现key-value的map集合结构,底层实际是一个数组,Entry为其每个节点对象,Entry 包含key和value
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
//1,初始化容量为16的Entry[]数组
table = new Entry[INITIAL_CAPACITY];
//2,这一步目的就是根据传入的ThreadLocal对象作为key,为了求放在数组下的索引位置,确定放在哪
//两个要求:1)求的索引位置一定要在数组大小内(这里即0-15范围)
// 2)索引足够均分分散,要求hashcode足够散列,目的减少hash冲突。
//firstKey.threadLocalHashCode,就是为了达到要求2
// &(INITIAL_CAPACITY - 1) 为了落在数组范围内,常用进行模运算,这里是巧妙运用位运算,效率更高, %2^n与 &(2^n-1)等价
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
//求得索引位置,放入数组中
table[i] = new Entry(firstKey, firstValue);
size = 1;
//设置数组容量阈值,即填充因子,用于后续判断是否需要扩容
setThreshold(INITIAL_CAPACITY);
}
//为了使传入的ThreadLocal对象求在数组索引位置,求的其hashcode,加上了0x61c88647增量,目的是为了足够分散
private static final int HASH_INCREMENT = 0x61c88647;
/**
* Returns the next hash code.
*/
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
//设置数组扩容阈值
private void setThreshold(int len) {
//初始填充因子为2/3,数组容量的2/3,即 16*2/3=10
threshold = len * 2 / 3;
}
//四、代码分析 set(key,value)
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
//求数组索引位置
int i = key.threadLocalHashCode & (len-1);
//这里用for循环,是为了解决hash冲突时,查找下一个可用 slot(卡槽,位置; 即生成的索引i,发现已有Entry占用了,找下一个位置插入,这里解决hash冲突方式不同于hashmap的拉链法(在冲突位置,以链表形式串接),这里采用的是线性寻址法,即数组当前i位置被占用了,看第i+1个位置,如果i+1已经大于等于数组length,再从数组下标0 从头开始,从该i = nextIndex(i, len)可知道是逻辑上这是一个首尾循环式数组)
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
//1,从i向后遍历,若Entry为null,跳出循环; 不为null,获取Entry的key,线程初始化 threadLocalMap集合就有3个 Entry(此处不解?debug看了)
ThreadLocal<?> k = e.get();
//2,如果数组当前位置key与将要设值的 threadlocal对象相等,覆盖原value,返回
if (k == key) {
e.value = value;
return;
}
if (k == null) {
//3,如果数组当前位置key为空,需要替换失效的Entry(stale:不新鲜的,Entry的key ==null)
//见代码分析五
replaceStaleEntry(key, value, i);
return;
}
}
//4,如果上面for循环,出现hash冲突了,跳出循环,此时索引i位置 Entry==null,在此插入新Entry
tab[i] = new Entry(key, value);
int sz = ++size;
//5,cleanSomeSlots,顺便清理一下失效的Entry,避免内存泄漏,见代码分析六
if (!cleanSomeSlots(i, sz) && sz >= threshold)
// 6,清理失败且当前数组的Entry数量达到设定阈值了,执行 rehash,见代码分析八
rehash();
}
//五、 分析 replaceStaleEntry(key, value, i) 替换失效的Entry
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
// 1,要清除的位置
int slotToExpunge = staleSlot;
//2,从i 向前遍历,找到左边第一个失效的位置(指的是Entry !=null,key==null)
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
//3,从i向后遍历
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
//4,传入 staleSlot的 key==null,是一个失效的Entry, 从staleSlot+1个向后遍历,如果
//遇见 k==key,将staleSlot索引位置与此处i替换位置,即将失效的Entry往后面放,
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
// Start expunge at preceding stale entry if it exists
//如果相等,staleSlot左边没有失效的entry,赋值为此处i,此处已经替换为失效Entry了,如果不相等,那么就清除失效Entry,以staleSlot最左边那一个失效entry开始清除
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
//cleanSomeSlots的目的:expungeStaleEntry返回的是entry ==null的索引i,
//清理i到len这一段的失效entry,中间会有null的情况吗?
return;
}
//5,slotToExpunge == staleSlot 表示 左边没有失效entry, 右边遇见第一失效entry,标记此处索引,以便后文确定从哪里开始清除无效entry
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
//解除value的引用,gc会回收
tab[staleSlot].value = null;
//数组失效Entry位置,赋值新的Entry
tab[staleSlot] = new Entry(key, value);
//6,不相等,肯定有失效索引需要清理,执行清除
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
//六、分析 cleanSomeSlots(int i, int n),清理某些失效的Entry方法
//i为 失效位置, n分2种传入场景
// 1)数组的实际Entry数量 size
// 2) 数组的容量 length
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
Entry e = tab[i];
// 遇见有失效的Entry,当n传入的是size,即数组实际容纳的数量,n扩大到数组长度了,
//影响在于,原来清理遍历的只是数组的一个小范围,一下子扩大到了整个数组。我理解这样做为了提高执行效率,没有检测到失效entry就小范围清理一下,检测到就大范围清理。
if (e != null && e.get() == null) {
n = len;
removed = true;
i = expungeStaleEntry(i);
}
// n >>>= 1,即 n向右位移1位,即 n/2, 可循环次数log2n次
} while ( (n >>>= 1) != 0);
return removed;
}
//七、分析清理失效Entry方法,清理起始位置是staleSlot
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// 清理当前位置的Entry
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// Rehash until we encounter null
Entry e;
int i;
//向后循环遍历,直到遇到 null
//做2件事:
//1)遇到其他失效Entry,顺手清除
//2)没有失效的Entry,重新hash一下,安排新位置;因为可能之前某些位置有hash冲突,导致根据key生成hash的值与当前的位置i不一致(冲突,会往后顺延,这里是逻辑上往后,达到数组长度,从0开始),而这时又清理了不少失效的Entry,可能会有空位了,所以重新hash调一下顺序,提高效率。
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
//1,失效Entry,清除
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
//2,hash值与当前数组索引位置不同
if (h != i) {
tab[i] = null;
//3,向后遍历,找合适空位置插入
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
//返回i位置, Entry ==null
return i;
}
//八、rehash
//首先扫描全表,清除所有失效的Entry, 如果这还不能充分地缩小数组的大小,扩容为当前的2倍
private void rehash() {
//1,清除所有失效的entry,见代码分析九
expungeStaleEntries();
//2,threshold = length * 2/ 3
//size >= threshold - threshold / 4 = threshold*3/4 ,
//即size >= length *2/3 *3/4= length* 1/2, 只要数组的大小>=于数组容量的一半,就扩容。
if (size >= threshold - threshold / 4)
//见代码分析十
resize();
}
//九、遍历数组全部节点,清除失效的Entry
private void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j < len; j++) {
Entry e = tab[j];
if (e != null && e.get() == null)
expungeStaleEntry(j);
}
}
//十、扩容为原来的2倍
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
// 旧数组数据向新数组迁移,顺便清除失效的entry的value,帮助Gc容易发现它,直接回收
//Entry不清除了吗?这里旧数组之后就没有被人引用了,下次Gc会直接回收
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null; // Help the GC
} else {
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}
3.4、get():T
//一、从get() 着手
public T get() {
//1,获取当前线程对象
Thread t = Thread.currentThread();
//2,获取该线程的 map集合,每个线程都有单独的map
ThreadLocalMap map = getMap(t);
if (map != null) {
//3,this指的是 ThreadLocal对象,以它为key,去map中获取相应的Entry,
//易混淆:ThreadLocalMap 中存储的Entry键值对,key是ThreadLocal对象,而不是线程对象。
//此处 map.getEntry(this) 下面代码二 分析
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
//4,返回value
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
//该线程若没有map对象, 返回初始默认值,详见代码分析四
return setInitialValue();
}
// 二、分析 map.getEntry(this)
private Entry getEntry(ThreadLocal<?> key) {
//1,获取数组索引位置
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
//2,直接就命中,没有hash冲突,返回
return e;
else
//3,遍历其他Entry,见代码分析三
return getEntryAfterMiss(key, i, e);
}
//三、根据key获取Entry,没有直接命中,继续遍历查找
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal<?> k = e.get();
if (k == key)
//1,命中返回,为啥重复判断一次? 因为这是在while循环,会往后执行再判断
return e;
if (k == null)
//2,当前位置Entry失效,清除
expungeStaleEntry(i);
else
//3,hash冲突,获取下一个索引
i = nextIndex(i, len);
e = tab[i];
}
//4,数组中没有找到该key
return null;
}
//四、没有map,返回默认值,初始化操作
private T setInitialValue() {
//1,调用默认的初始化方法, 如下,一般用来被重写的,给定一个初始值
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
protected T initialValue() {
return null;
}
3.5、remove():void
// 一、入口
public void remove() {
//1,获取当前线程的map集合
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
//2,见代码分析二
m.remove(this);
}
// 二、 m.remove(this);
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
//1、获取该key在数组中索引位置
int i = key.threadLocalHashCode & (len-1);
//2,从i位置向后循环判断,考虑hash冲突
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
//3,找到该key,
if (e.get() == key) {
//4,引用置空
e.clear();
// 5,从i开始清除失效的Entry,避免内存泄漏
expungeStaleEntry(i);
return;
}
}
}
//引用置空
public void clear() {
this.referent = null;
}
3.6、总结
从set,get,remove代码可见,每个方法都会去清除失效的Entry,说明设计者也考虑到内存泄漏的问题,所以建议在使用完ThreadLocal,及时执行remove方法清除一下,避免潜在的内存泄漏问题。