简介
字符串是我们日常编码过程中使用到最多的java类型了。全球各个地区的语言不同,即使使用了Unicode也会因为编码格式的不同采用不同的编码方式,如UTF-8,UTF-16,UTF-32等。
我们在使用字符和字符串编码的过程中会遇到哪些问题呢?一起来看看吧。
使用变长编码的不完全字符来创建字符串
在java中String的底层存储char[]是以UTF-16进行编码的。
注意,在JDK9之后,String的底层存储已经变成了byte[]。
StringBuilder和StringBuffer还是使用的是char[]。
那么当我们在使用InputStreamReader,OutputStreamWriter和String类进行String读写和构建的时候,就需要涉及到UTF-16和其他编码的转换。
我们来看一下从UTF-8转换到UTF-16可能会遇到的问题。
先看一下UTF-8的编码:
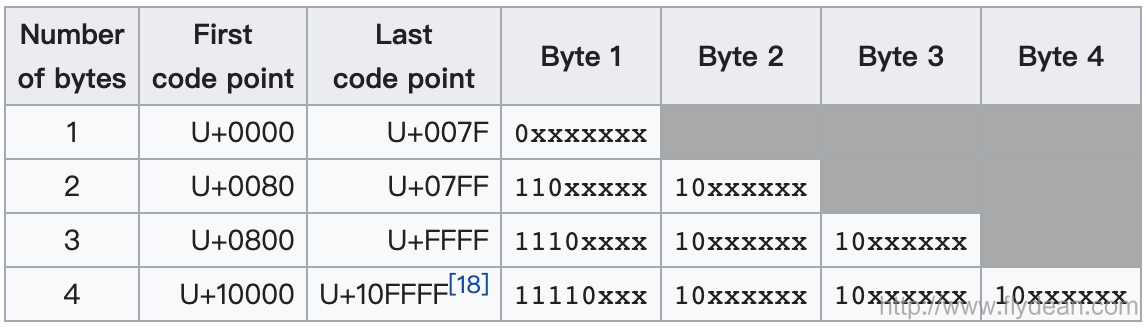
UTF-8使用1到4个字节表示对应的字符,而UTF-16使用2个或者4个字节来表示对应的字符。
转换起来可能会出现什么问题呢?
public String readByteWrong(InputStream inputStream) throws IOException {
byte[] data = new byte[1024];
int offset = 0;
int bytesRead = 0;
String str="";
while ((bytesRead = inputStream.read(data, offset, data.length - offset)) != -1) {
str += new String(data, offset, bytesRead, "UTF-8");
offset += bytesRead;
if (offset >= data.length) {
throw new IOException("Too much input");
}
}
return str;
}
上面的代码中,我们从Stream中读取byte,每读一次byte就将其转换成为String。很明显,UTF-8是变长的编码,如果读取byte的过程中,恰好读取了部分UTF-8的代码,那么构建出来的String将是错误的。
我们需要下面这样操作:
public String readByteCorrect(InputStream inputStream) throws IOException {
Reader r = new InputStreamReader(inputStream, "UTF-8");
char[] data = new char[1024];
int offset = 0;
int charRead = 0;
String str="";
while ((charRead = r.read(data, offset, data.length - offset)) != -1) {
str += new String(data, offset, charRead);
offset += charRead;
if (offset >= data.length) {
throw new IOException("Too much input");
}
}
return str;
}
我们使用了InputStreamReader,reader将会自动把读取的数据转换成为char,也就是说自动进行UTF-8到UTF-16的转换。
所以不会出现问题。
char不能表示所有的Unicode
因为char是使用UTF-16来进行编码的,对于UTF-16来说,U+0000 to U+D7FF 和 U+E000 to U+FFFF,这个范围的字符,可以直接用一个char来表示。
但是对于U+010000 to U+10FFFF是使用两个0xD800–0xDBFF和0xDC00–0xDFFF范围的char来表示的。
这种情况下,两个char合并起来才有意思,单独一个char是没有任何意义的。
考虑下面的我们的的一个subString的方法,该方法的本意是从输入的字符串中找到第一个非字母的位置,然后进行字符串截取。
public static String subStringWrong(String string) {
char ch;
int i;
for (i = 0; i < string.length(); i += 1) {
ch = string.charAt(i);
if (!Character.isLetter(ch)) {
break;
}
}
return string.substring(i);
}
上面的例子中,我们一个一个的取出string中的char字符进行比较。如果遇到U+010000 to U+10FFFF范围的字符,就可能报错,误以为该字符不是letter。
我们可以这样修改:
public static String subStringCorrect(String string) {
int ch;
int i;
for (i = 0; i < string.length(); i += Character.charCount(ch)) {
ch = string.codePointAt(i);
if (!Character.isLetter(ch)) {
break;
}
}
return string.substring(i);
}
我们使用string的codePointAt方法,来返回字符串的Unicode code point,然后使用该code point来进行isLetter的判断就好了。
注意Locale的使用
为了实现国际化支持,java引入了Locale的概念,而因为有了Locale,所以会导致字符串在进行转换的过程中,产生意想不到变化。
考虑下面的例子:
public void toUpperCaseWrong(String input){
if(input.toUpperCase().equals("JOKER")){
System.out.println("match!");
}
}
我们期望的是英语,如果系统设置了Locale是其他语种的话,input.toUpperCase()可能得到完全不一样的结果。
幸好,toUpperCase提供了一个locale的参数,我们可以这样修改:
public void toUpperCaseRight(String input){
if(input.toUpperCase(Locale.ENGLISH).equals("JOKER")){
System.out.println("match!");
}
}
同样的, DateFormat也存在着问题:
public void getDateInstanceWrong(Date date){
String myString = DateFormat.getDateInstance().format(date);
}
public void getDateInstanceRight(Date date){
String myString = DateFormat.getDateInstance(DateFormat.MEDIUM, Locale.US).format(date);
}
我们在进行字符串比较的时候,一定要考虑到Locale影响。
文件读写中的编码格式
我们在使用InputStream和OutputStream进行文件对写的时候,因为是二进制,所以不存在编码转换的问题。
但是如果我们使用Reader和Writer来进行文件的对象,就需要考虑到文件编码的问题。
如果文件是UTF-8编码的,我们是用UTF-16来读取,肯定会出问题。
考虑下面的例子:
public void fileOperationWrong(String inputFile,String outputFile) throws IOException {
BufferedReader reader = new BufferedReader(new FileReader(inputFile));
PrintWriter writer = new PrintWriter(new FileWriter(outputFile));
int line = 0;
while (reader.ready()) {
line++;
writer.println(line + ": " + reader.readLine());
}
reader.close();
writer.close();
}
我们希望读取源文件,然后插入行号到新的文件中,但是我们并没有考虑到编码的问题,所以可能会失败。
上面的代码我们可以修改成这样:
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(inputFile), Charset.forName("UTF8")));
PrintWriter writer = new PrintWriter(new OutputStreamWriter(new FileOutputStream(outputFile), Charset.forName("UTF8")));
通过强制指定编码格式,从而保证了操作的正确性。
不要将非字符数据编码为字符串
我们经常会有这样的需求,就是将二进制数据编码成为字符串String,然后存储在数据库中。
二进制是以Byte来表示的,但是从我们上面的介绍可以得知不是所有的Byte都可以表示成为字符。如果将不能表示为字符的Byte进行字符的转化,就有可能出现问题。
看下面的例子:
public void convertBigIntegerWrong(){
BigInteger x = new BigInteger("1234567891011");
System.out.println(x);
byte[] byteArray = x.toByteArray();
String s = new String(byteArray);
byteArray = s.getBytes();
x = new BigInteger(byteArray);
System.out.println(x);
}
上面的例子中,我们将BigInteger转换为byte数字(大端序列),然后再将byte数字转换成为String。最后再将String转换成为BigInteger。
先看下结果:
1234567891011
80908592843917379
发现没有转换成功。
虽然String可以接收第二个参数,传入字符编码,目前java支持的字符编码是:ASCII,ISO-8859-1,UTF-8,UTF-8BE, UTF-8LE,UTF-16,这几种。默认情况下String也是大端序列的。
上面的例子怎么修改呢?
public void convertBigIntegerRight(){
BigInteger x = new BigInteger("1234567891011");
String s = x.toString(); //转换成为可以存储的字符串
byte[] byteArray = s.getBytes();
String ns = new String(byteArray);
x = new BigInteger(ns);
System.out.println(x);
}
我们可以先将BigInteger用toString方法转换成为可以表示的字符串,然后再进行转换即可。
我们还可以使用Base64来对Byte数组进行编码,从而不丢失任何字符,如下所示:
public void convertBigIntegerWithBase64(){
BigInteger x = new BigInteger("1234567891011");
byte[] byteArray = x.toByteArray();
String s = Base64.getEncoder().encodeToString(byteArray);
byteArray = Base64.getDecoder().decode(s);
x = new BigInteger(byteArray);
System.out.println(x);
}
本文的代码:
learn-java-base-9-to-20/tree/master/security
本文已收录于 http://www.flydean.com/java-security-code-line-string/
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!
欢迎关注我的公众号:「程序那些事」,懂技术,更懂你!