简介
上篇文章我们讲到了JIT中的LogCompilation,将编译的日志都收集起来,存到日志文件里面,并且详细的解释了LogCompilation日志文件中的内容定义。今天我们再和小师妹一起学习LogCompilation的姊妹篇PrintCompilation,看看都有什么妙用吧。
PrintCompilation
小师妹:F师兄,上次你给讲的LogCompilation实在是太复杂了,生成的日志文件又多,完全看不了,我其实只是想知道有哪些方法被编译成了机器码,有没有什么更加简单的办法呢?
真理的大海,让未发现的一切事物躺卧在我的眼前,任我去探寻- 牛顿(英国)
当然有的,那就给你介绍一下LogCompilation的妹妹PrintCompilation,为什么是妹妹呢?因为PrintCompilation输出的日志要比LogCompilation少太多了。
老规矩,上上我们的JMH运行代码,文章中使用的代码链接都会在文末注明,这里使用图片的原因只是为了方便读者阅读代码:
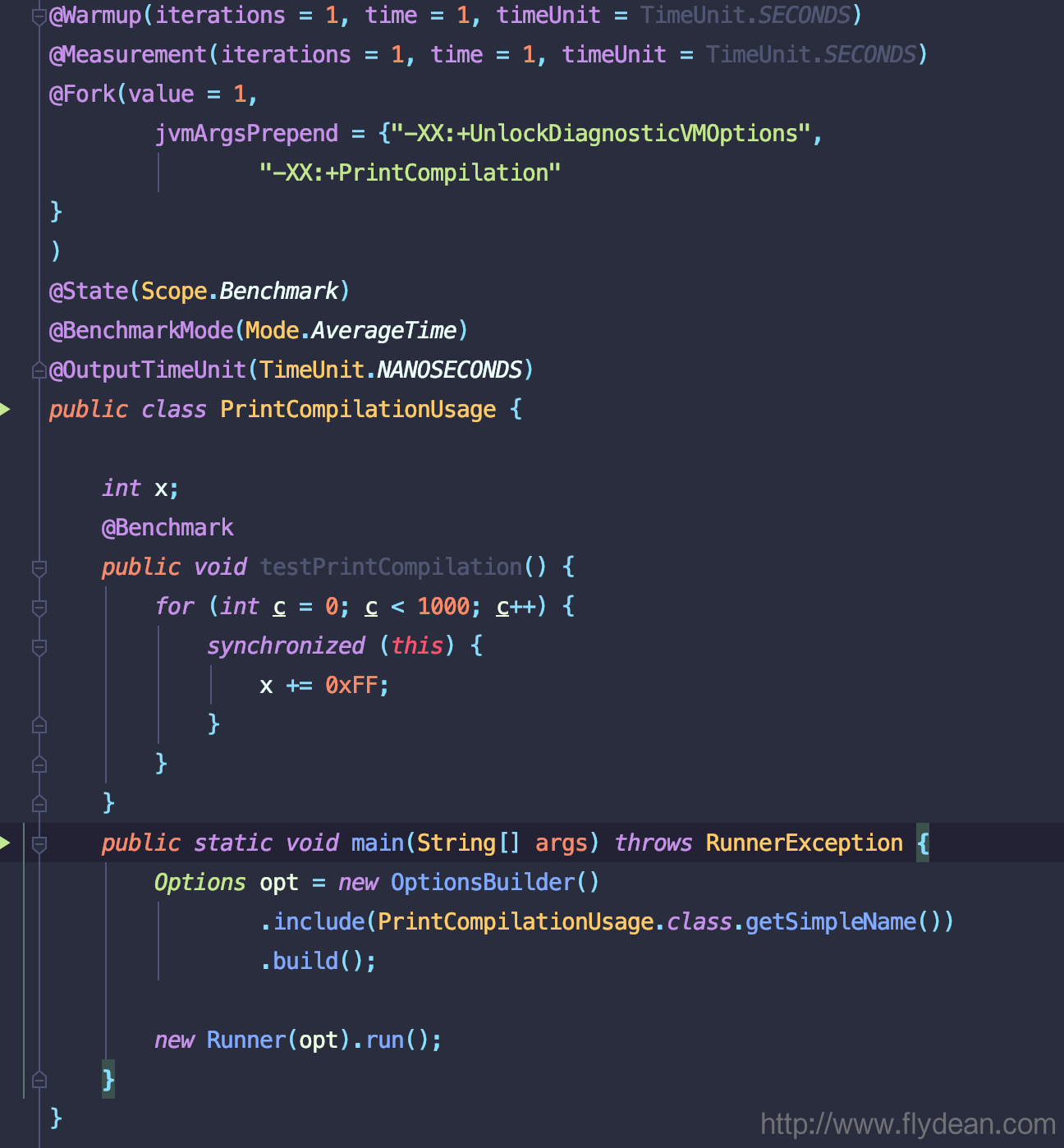
这里和上次的LogCompilation不同的是,我们使用:-XX:+PrintCompilation参数。
其实我们还可以添加更多的参数,例如:
-Xbatch -XX:-TieredCompilation -XX:+PrintCompilation
先讲一下-Xbatch。
一般来说JIT编译器使用的是和主线程完全不同的新的线程。这样做的好处就是JIT可以和主线程并行执行,编译器的运行基本上不会影响到主线程的的运行。
但是有阴就有阳,有利就有弊。多线程在提高的处理速度的同时,带给我们的就是输出日志的混乱。因为是并行执行的,我们主线程的日志中,穿插了JIT编译器的线程日志。
如果使用-Xbatch就可以强迫JIT编译器使用主线程。这样我们的输出日志就是井然有序的。真棒。
再讲一下TieredCompilation。
为了更好的提升编译效率,JVM在JDK7中引入了分层编译Tiered compilation的概念。
大概来说分层编译可以分为三层:
第一层就是禁用C1和C2编译器,这个时候没有JIT进行。
第二层就是只开启C1编译器,因为C1编译器只会进行一些简单的JIT优化,所以这个可以应对常规情况。
第三层就是同时开启C1和C2编译器。
在JDK8中,分层编译是默认开启的。因为不同的编译级别处理编译的时间是不一样的,后面层级的编译器启动的要比前面层级的编译器要慢,但是优化的程度更高。
这样我们其实会产生很多中间的优化代码,这里我们只是想分析最终的优化代码,所以我们需要停止分层编译的功能。
最后是今天的主角:PrintCompilation。
PrintCompilation将会输出被编译方法的统计信息,因此使用PrintCompilation可以很方便的看出哪些是热点代码。热点代码也就意味着存在着被优化的可能性。
分析PrintCompilation的结果
小师妹:F师兄,我照着你的例子运行了一下,结果果然清爽了很多。可是我还是看不懂。
没有一个人能全面把握真理。小师妹,我们始终在未知的路上前行。不懂就问,不会就学。
我们再截个图看一下生成的日志吧。

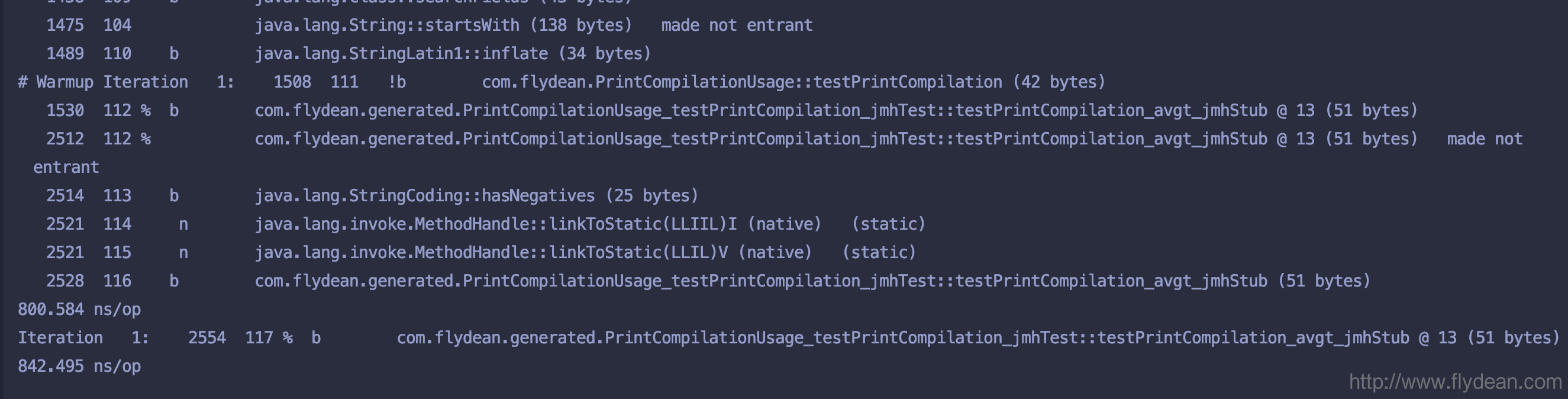
因为日志太长了,为了节约大家的流量,我只截取了开头的部分和结尾的部分。
大家可以看到开头部分基本上都是java自带的类的优化。只有最后才是我们自己写的类。
第一列是方法开始编译的时间。
第二列是简单的index。
第三列是一系列的flag的组合,有下面几个flag:
b Blocking compiler (always set for client)
* Generating a native wrapper
% On stack replacement (where the compiled code is running)
! Method has exception handlers
s Method declared as synchronized
n Method declared as native
made non entrant compilation was wrong/incomplete, no future callers will use this version
made zombie code is not in use and ready for GC
如果我们没有关闭分层编译的话,在方法名前面还会有数字,表示是使用的那个编译器。

分层编译详细的来说可以分为5个级别。
0表示是使用解释器,不使用JIT编译。
1,2,3是使用C1编译器(client)。
4是使用C2编译器(server)。
现在让我们来看一下最后一列。
最后一列包含了方法名和方法的长度。注意这里的长度指的是字节码的长度。
如果字节码被编译成为机器码,长度会增加很多倍。
总结
本文介绍了JIT中PrintCompilation的使用,并再次复习了JIT中的分层编译架构。希望大家能够喜欢。
本文的例子https://github.com/ddean2009/learn-java-base-9-to-20
本文作者:flydean程序那些事
本文链接:http://www.flydean.com/jvm-jit-printcompilation/
本文来源:flydean的博客
欢迎关注我的公众号:程序那些事,更多精彩等着您!