1、为什么配置高可用HA
- 单点故障:在Hadoop2.0.0之前,每个Hadoop集群只有一个namenode节点,一旦该节点发生了故障,那么整个集群将瘫痪掉,只有重新启动该节点,或者重新移动到另外的节点,才能够重新运行该节点,这也就是所谓的单点故障
2、HA的原理
- 在同一个集群上配置两个名称节点,一个为激活态,一个为待命态。当激活态的名称节点出现了故障,那么可以快速的将待命态的名称节点快速容错,转为激活态
- 两个名称节点通过journal node 进行通信,从而达到同步的状态,一旦激活态的名称空间改变,那么将会将这些改变写入编辑日志然后下发给大部分的journal node,然后待命态的节点将journal node 的编辑日志写入到自己的名称空间中,从而达到同步
- 为了达到快速容错,所有的数据节点都需要知道两个名称节点的位置信息,从而将自己的块信息以及状态发送给两个名称节点,所以两个名称节点也需要及时的更新集群的块位置
- 一个集群在任意时刻只允许一个名称节点为激活态,否则会发生脑裂,导致数据丢失登不可预知的错误。
- 一旦处于待命态的节点处于了激活态,那么就拥有了向journal node写数据的能力。
3、HA配置准备
- 两个硬件条件相同的名称节点,同时他们的硬件条件还应该其他不是HA集群的节点硬件相同
- journal node:相对来说比较轻量级,可以和其他守护进程在节点上找到合适的位置。但是每个HA集群至少有3个journal node。
- 一个集群可以容错的最大限制是(n-1)/ 2个journal node失效,所以HA集群需要运行奇数个journal node
4、注意点
- 在HA集群中,待命态的名称节点也作为名称空间的检查点,因此不需要运行secondary namenode,CheckpointNode, or BackupNode
5、HA配置信息
在HA集群中通过nameservice ID来区分包含了两个名称节点的HDFS 实例,同时也通过namenode ID来区分不同的名称节点
- 配置nameservice——逻辑名称
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>- 配置nameservice里面namenode的唯一标识符dfs.ha.namenodes.[nameservice ID],这里将nn1作为名称节点1,nn2作为名称节点2
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>- 配置名称节点的rpc监听地址dfs.namenode.rpc-address.[nameservice ID].[name node ID]
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>s150:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>s153:8020</value>
</property>- 配置名称节点的HTTP监听地址dfs.namenode.http-address.[nameservice ID].[name node ID]
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>s150:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>s153:50070</value>
</property>- 配置journal node的共享编辑日志地址,以便激活态的namenode进行日志的写入,以及待命态的namenode读取日志dfs.client.failover.proxy.provider.[nameservice ID]
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://s150:8485;s151:8485;s152:8485/mycluster</value>
</property>- 配置容错时防护namenode方法dfs.ha.fencing.methods
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/xiaoqiu/.ssh/id_rsa</value>
</property>- 配置HDFS文件系统名称服务
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>- 配置journal node的编辑日志的本地存放目录
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/xiaoqiu/hadoop_tmp/journal</value>
</property>
6、HA配置过程
- 配置文件core-site.xml 和hdfs-site.xml
- 由于我这里的s153是通过s150克隆的,所以他的的公钥和私钥和s150一摸一样,首先我需要删除他原来的.ssh 文件,重新生成公钥和私钥
[xiaoqiu@s153 /home/xiaoqiu]$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
- 然后将刚才生成的公钥发给s150,让s150分发给各个节点
[xiaoqiu@s153 /home/xiaoqiu/.ssh]$ scp id_rsa.pub s150:/home/xiaoqiu/.ssh/id_rsa.pub.s153.0
[xiaoqiu@s150 /home/xiaoqiu/.ssh]$ xrsync.sh id_rsa.pub.s153.0
- 在各个节点将s153的公钥追加到authorized-keys
[xiaoqiu@s150 /home/xiaoqiu/.ssh]$ xcall.sh "cat /home/xiaoqiu/.ssh/id_rsa.pub.s153.0 >> /home/xiaoqiu/.ssh/authorized_keys "
- 在s150节点下的Hadoop/etc文件夹下面新建一个文件夹ha,作为高可用配置的Hadoop集群
[xiaoqiu@s150 /soft/hadoop/etc]$ cp -r full ha
- 配置core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>- 配置hdfs-site.xml
- 分发ha给各个节点,查看
[xiaoqiu@s150 /soft/hadoop/etc]$ xcall.sh "ls /soft/hadoop/etc/"- 将符号链接转换到ha上
[xiaoqiu@s150 /soft/hadoop/etc]$ xcall.sh "ln -sfT /soft/hadoop/etc/ha /soft/hadoop/etc/hadoop"- 查看符号链接
[xiaoqiu@s150 /soft/hadoop/etc]$ xcall.sh " ls -al /soft/hadoop/etc/"- 启动journal node节点
- 分别启动节点s150,s151,s152的journal node
[xiaoqiu@s150 /soft/hadoop/etc]$ hadoop-daemon.sh start journalnode
- 初始化同步两个名称节点的磁盘元数据信息
- 如果是新搭建的集群,需要在其中一个名称节点上进行格式化文件系统,如果是之前就搭建好的集群就不用再格式化了,因为格式化就相当于删除了所有节点的目录
- 其次在向HA集群转换的时候,需要将已经格式化或者原来的名称节点的元数据目录拷贝到另外一个名称节点上
[xiaoqiu@s150 /home/xiaoqiu/hadoop_tmp]$ scp -r /home/xiaoqiu/hadoop_tmp/dfs s153:/home/xiaoqiu/hadoop_tmp/
- 引导使s153节点处于待命态
xiaoqiu@s153 /home/xiaoqiu]$ hdfs namenode -bootstrapStandby注意这里不用选择再重新格式化,因为已经把集群的VERSION文件拷贝过来了
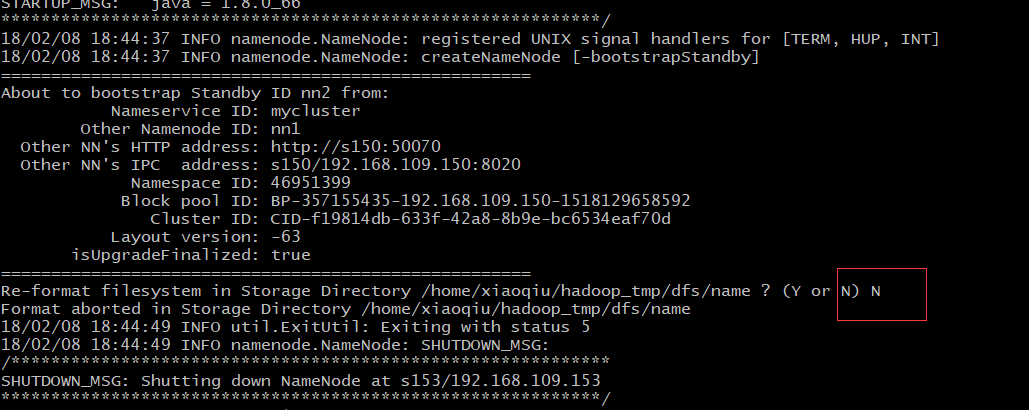
- 初始化journal node的编辑日志,从namenode的编辑日志中初始化
[xiaoqiu@s153 /home/xiaoqiu/hadoop_tmp]$ hdfs namenode -initializeSharedEdits
- 启动s153的名称节点
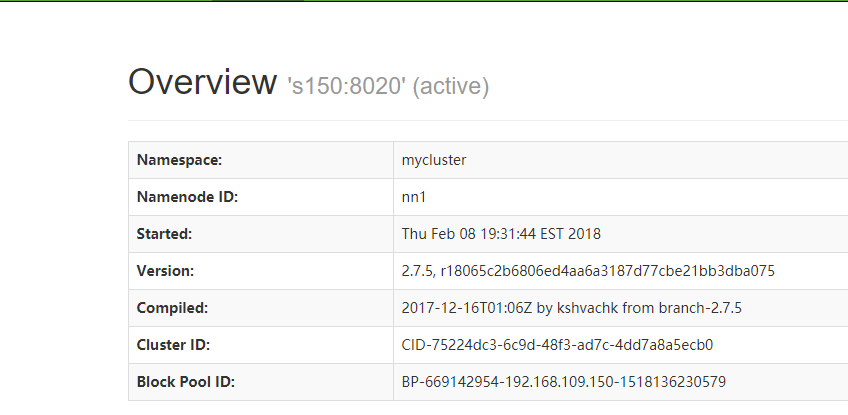
- 访问两个名称节点的http端口
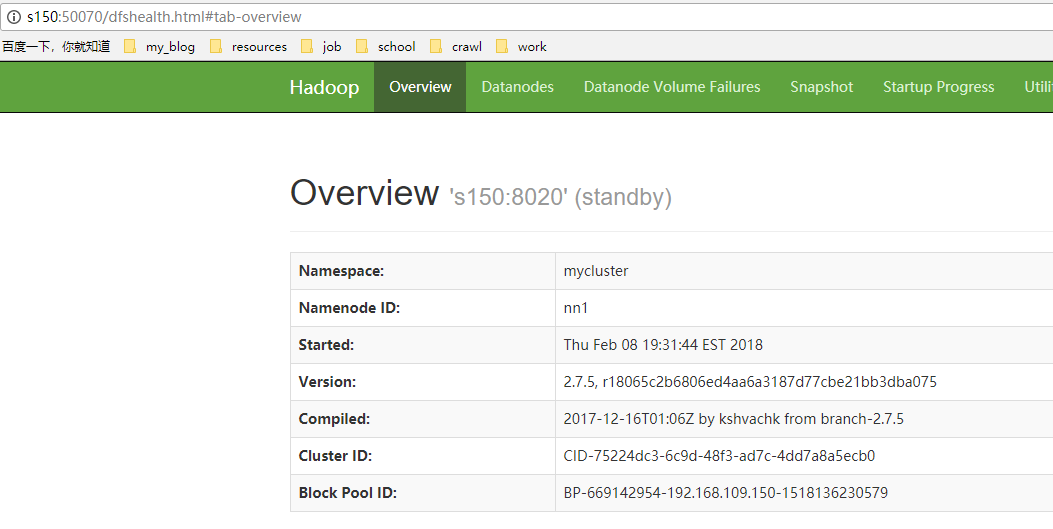
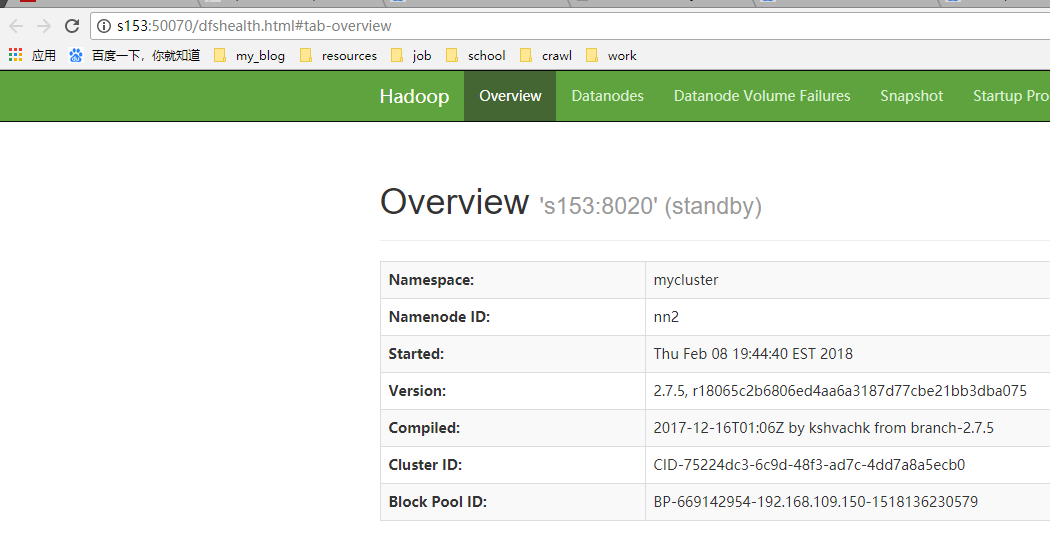
- 修改其中一个节点为激活态
[root@s150 /home/xiaoqiu]# hdfs haadmin -transitionToActive nn1