http://www.cnblogs.com/artech/archive/2007/08/24/868956.html
在第一部分中,我们讨论了APPLY和CTE这两个T-SQL Enhancement。APPLY实现了Table和TVF的Join,CTE通过创建“临时的View”的方式使问题化繁为简。现在我们接着来讨论另外两个重要的T-SQL Enhancement Items:PIVOT和Ranking。
三、 PIVOT Operator
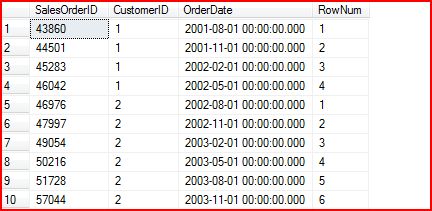
PIVOT的中文意思是“在枢轴上转动”,比如对于一个2维坐标,将横坐标变成纵坐标,将纵坐标变成横坐标。反映在一个Relational Table上的意思就是:变成为列,变列为行。相信大家在进行报表设计的时候都遇到过类似于这样的需求:统计2002年内某个销售人员第一季度每个月处理的订单数。在AdventureWorks Sample Databse中,Sales Order存储于SaleOrderHeader这张表中,它的结果如下:
我们一般情况下通过下面的SQL实现我们提出的统计功能:
 SELECT SalesPersonID,SUM(CASE DATEPART(MM,OrderDate)WHEN 1 THEN 1 ELSE 0 END) AS JAN,SUM(CASE DATEPART(MM,OrderDate)WHEN 2 THEN 1 ELSE 0 END) AS FEB,SUM(CASE DATEPART(MM,OrderDate)WHEN 3 THEN 1 ELSE 0 END) AS MAR,SUM(CASE DATEPART(MM,OrderDate)WHEN 4 THEN 1 ELSE 0 END) AS APRFROM Sales.SalesOrderHeaderWHERE DATEPART(yyyy,OrderDate) = 2002GROUP BY SalesPersonID
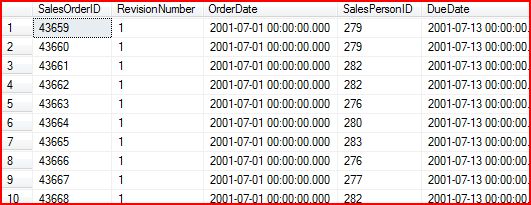
SELECT SalesPersonID,SUM(CASE DATEPART(MM,OrderDate)WHEN 1 THEN 1 ELSE 0 END) AS JAN,SUM(CASE DATEPART(MM,OrderDate)WHEN 2 THEN 1 ELSE 0 END) AS FEB,SUM(CASE DATEPART(MM,OrderDate)WHEN 3 THEN 1 ELSE 0 END) AS MAR,SUM(CASE DATEPART(MM,OrderDate)WHEN 4 THEN 1 ELSE 0 END) AS APRFROM Sales.SalesOrderHeaderWHERE DATEPART(yyyy,OrderDate) = 2002GROUP BY SalesPersonID于是我们得到了这样的统计数据:
通过数据在原表的结构和我们最终获得的结果进行比较,我们发现就像是“旋转”了90度,原来的OrderDate是存储在每行的基于Order的一个属性(行),现在我们要把Order Date按照不同月份统计,这样行变成了列。
像这样的需求,我们都可以可以通过PIVOT这个操作符来实现,下面就是基于PIVOT的SQL:
SELECT SalesPersonID, [1] AS JAN,[2] AS FEB, [3] AS MAR, [4] AS APRFROM ( SELECT SalesPersonID, DATEPART(MM,OrderDate) AS MON FROM Sales.SalesOrderHeader WHERE DATEPART(yyyy,OrderDate) = 2002) SPIVOT ( COUNT(MON) FOR MON IN ([1],[2],[3],[4]))AS P在上面的例子中,同过下面的SELECT语句筛选出来的是为经过PIVOT的数据。
SELECT SalesPersonID, DATEPART(MM,OrderDate) AS MON FROM Sales.SalesOrderHeader WHERE DATEPART(yyyy,OrderDate) = 2002通过下面的PIVOT(COUNT(MON)是我们需要统计的数据,FOR MON IN ([1],[2],[3],[4]是统计的范围)就成了我们最终输出的结构了。
PIVOT ( COUNT(MON) FOR MON IN ([1],[2],[3],[4]))如果你第一次见到PIVOT,可以不能一下明白它的实现,但是只要你是使用了一两次,相信就会很容易地掌握它。与PIVOT对应的还以一个操作符UNPIVOT,它完成PIVOT的逆操作,在这里就不介绍了,如果有兴趣的话,可以参考SQL Server Books Online。
四、 Ranking
排序与排名是我们最为常用的统计方式,比如对班级的学生根据成员进行排名,或者按照成绩高低把学生划分成若干梯队:比如最好成绩的10名学生属于第一梯队,后10名又划分为第二梯队,以此类推。Ranking设计的Key Words包括:ROW_NUMBER(),RANK(),DENSE_RANK(),NTILE()。我们现在就来介绍一下他们的用法和相互之间的差异。
1. 1. ROW_NUMBER()
看到ROW_NUMBER(),我想绝大多数人会像想到Oracle的ROWNUM。他们的作用相似,都是表示某条记录所处的Index。ROW_NUMBER()比Oracle的ROWNUM更加强大的是,它可以通过OVER语句指定一个进行排序的Column,比如:ROW_NUMBER() OVER (ORDER BY CustomerID)。
我们来看一个例子:对Sales.SalesOrderHeader按照CustomerID进行排序,并显示每条记录的Row Number。
SELECT SalesOrderID,CustomerID,ROW_NUMBER() OVER (ORDER BY CustomerID) AS RowNumFROM Sales.SalesOrderHeader下面是查询结果:
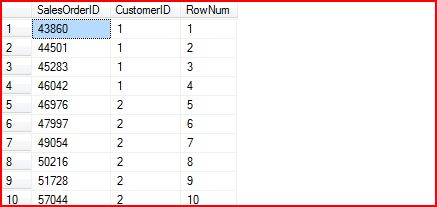
我们发现最终的结果按照CutomerID进行排序,RowNum从1开始以此递增,每条记录(不管是否具有相同的CustomerID)拥有不同的RowNum。
提到排序,我们就不得不提到Order BY,如果我们在后面加上ORDER BY,并指定不同的排序字段,会出现怎样的结果呢?
SELECT SalesOrderID,CustomerID,ROW_NUMBER() OVER (ORDER BY CustomerID) AS RowNumFROM Sales.SalesOrderHeaderORDER BY SalesOrderID查询获得的结果是:
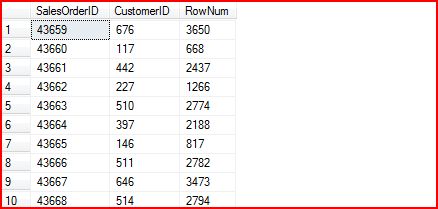
从上图中可以看到,最终的结果以ORDER BY中指定的SalesOrderID进行排序,但是ROW_NUMBER()体现的值却是基于CustmerID排序的。
由于ROW_NUMBER()体现是基于某个确定的字段进行排序后某个DataRow所处的位置,所以它不能直接使用到Aggregate的Column中。比如下面的SQL是不合法的:
SELECT CustomerID,COUNT(*) AS OrderCount,ROW_NUMBER() OVER (ORDER BY OrderCount)FROM Sales.SalesOrderHeaderGROUP BY CustomerID要是想按照OrderCount,可以使用第一部分介绍的CTE:
WITH CTE_Order(CustomerID,OrderCount)AS(SELECT CustomerID,COUNT(*) AS OrderCountFROM Sales.SalesOrderHeaderGROUP BY CustomerID)SELECT CustomerID,OrderCount,ROW_NUMBER() OVER (ORDER BY OrderCount)FROM CTE_Order2. RANK()
RANK()的使用和ROW_NUMBER()类似。不过它与ROW_NUMBER()所不同的是:对于被指定为排序的字段,具有相同值得Row对应的返回值相同。比如:
SELECT SalesOrderID,CustomerID,RANK() OVER (ORDER BY CustomerID) AS RowNumFROM Sales.SalesOrderHeader下面是相应的查询结果:
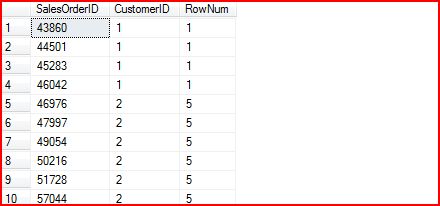
对于RANK(),还有一点需要说明的是,它的回返值不是连续的, 比如第五条记录的Row_Num是5而不是2。如果想实现这样需求,就需要用下面一个Function:DENSE_RANK()。
3. 3. DENSE_RANK()
DENSE_RANK()实现了一个连续的Ranking。比如下面的SQL:
SELECT SalesOrderID,CustomerID,DENSE_RANK() OVER (ORDER BY CustomerID) AS RowNumFROM Sales.SalesOrderHeader就来产生如下的查询结果: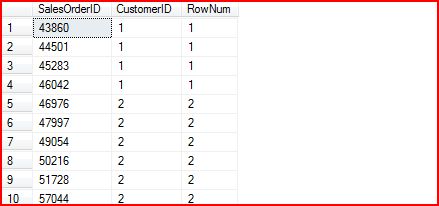
4. NTILE()
上面我们说到划分梯队的问题,这样的问题可以通过NTILE() Function来实现。比如我们现在按照CustomerID排序,把CustomerID为1和2的划分到3梯队中:
SELECT SalesOrderID,CustomerID,NTILE(3) OVER (ORDER BY CustomerID) AS RowNumFROM Sales.SalesOrderHeaderWHERE CustomerID <3其查询结果为:
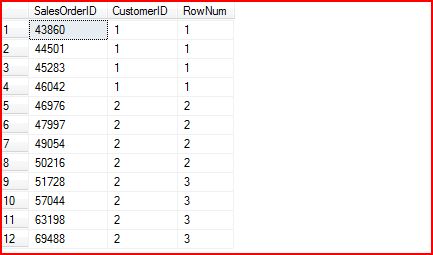
我们可以看到,一共12条记录,划分为3组,平均下来每组4条记录。
5. 5.PARTITION BY
上面提到的所有Ranking都是基于真个结果基的。而有的时候我们需要将真个结果集按照某个Column 进行分组,进行基于组的Ranking。这就需要PARTITION BY了。PARTITION BY置于OVER Clause中,和ORDER BY 平级。
比如下面的SQL将Order记录按照CustomerID进行分组,在每组中输出排名(安OrderDate排序):
SELECT SalesOrderID,CustomerID,RANK() OVER (PARTITION BY CustomerID ORDER BY OrderDate) AS RowNumFROM Sales.SalesOrderHeader相应的查询结果: