生成模式以及判别模式
Time: 2017-3-1
learning model
监督学习的主要任务就是要学习一个模型,基于这个模型,给定输入预测可以得到相应的输入,一般这个模型叫做决策函数,表示为
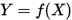
或者是表达为一个概率分布:
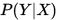
根据求取概率分布的方式,我们又可以分为生成方法(generative approach)和判别方法(discriminative approa)
generative approach
生成方法由数据学习联合概率分布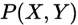 , 然后再求出条件概率分布
, 然后再求出条件概率分布 作为预测的模型,即:
作为预测的模型,即:
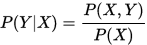
这种方法之所以称之为生成方法,是因为模型表示了给定输入X产生输出Y的生成关系,典型的生成模型有:朴素贝叶斯法、隐马尔可夫模型
discriminative approach
判别方法由数据直接学习决策函数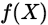 或者是概率分布
或者是概率分布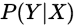 作为预测模型,具体的来说就是它只关心的是对给定的X, 应该预测什么样的输出Y。
作为预测模型,具体的来说就是它只关心的是对给定的X, 应该预测什么样的输出Y。
典型的判别模型有:k-近邻、感知机、决策树、逻辑回归、最大熵模型、支持向量机、提升方法、和条件随机场
difference
这两个方法各有优点,适合不同条件下的学习问题。
生成方法的特点:
- 可以还原出联合概率分布
 , 而判别方法则不能。
, 而判别方法则不能。 - 收敛速度快,即当样本容量增加的时候, 学到的模型可以更快的收敛于真是模型
- 当存在隐变量时,只能用生成方法去学习,而其他方法就不适用
判别方法的特点:
- 因为是直接面对预测,往往学习效率更高
- 由于直接学习决策函数,可以对数据进行各种程度上的抽象,定义特征并使用特征,因此可以简化学习问题
reference
[1] 统计学习方法. 李航