memcached是一个高性能的分布式内存对象缓存系统:
Memcached简介
Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。Memcached基于一个存储键/值对的hashmap。其守护进程(daemon )是用C写的,但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信。
为什么用Memcached
网站的高并发读写需求,传统的数据库开始出现瓶颈
单机Mysql时代
在90年代,一个网站的访问量一般都不大,用单个数据库完全可以轻松应付。在那个时候,更多的都是静态网页,动态交互类型的网站不多。
90年代的架构遇到的问题
1.数据量的总大小 一个机器放不下时
2.数据的索引(B+ Tree)一个机器的内存放不下时
3.访问量(读写混合)一个实例不能承受
Memcached(缓存)+MySQL+垂直拆分
随着访问量的上升,几乎大部分使用MySQL架构的网站在数据库上都开始出现了性能问题,web程序不再仅仅专注在功能上,同时也在追求性能。程序员们开始大量的使用缓存技术来缓解数据库的压力,优化数据库的结构和索引。开始比较流行的是通过文件缓存来缓解数据库压力,但是当访问量继续增大的时候,多台web机器通过文件缓存不能共享,大量的小文件缓存也带了了比较高的IO压力。在这个时候,Memcached出现了。
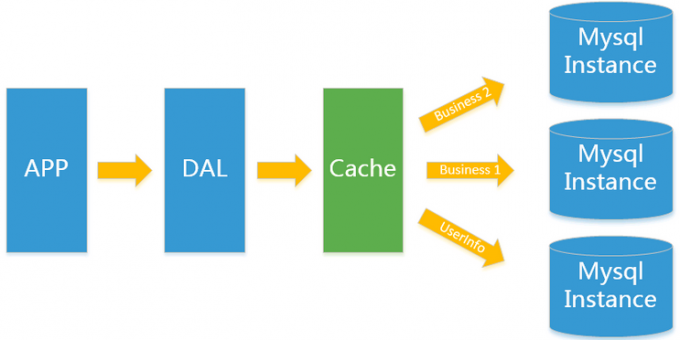
Memcached作为一个独立的分布式的缓存服务器,为多个web服务器提供了一个共享的高性能缓存服务,在Memcached服务器上,又发展了根据hash算法来进行多台Memcached缓存服务的扩展,然后又出现了一致性hash来解决增加或减少缓存服务器导致重新hash带来的大量缓存失效的弊端
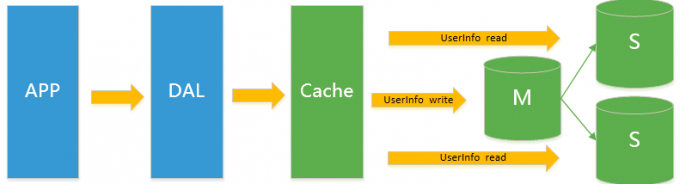
Mysql主从读写分离
由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。Mysql的master-slave模式成为这个时候的网站标配了。
分表分库+水平拆分+mysql集群
在Memcached的高速缓存,MySQL的主从复制,读写分离的基础之上,这时MySQL主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁,在高并发下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB引擎代替MyISAM。
同时,开始流行使用分表分库来缓解写压力和数据增长的扩展问题。这个时候,分表分库成了一个热门技术,是面试的热门问题也是业界讨论的热门技术问题。也就在这个时候,MySQL推出了还不太稳定的表分区,这也给技术实力一般的公司带来了希望。虽然MySQL推出了MySQL Cluster集群,但性能也不能很好满足互联网的要求,只是在高可靠性上提供了非常大的保证。
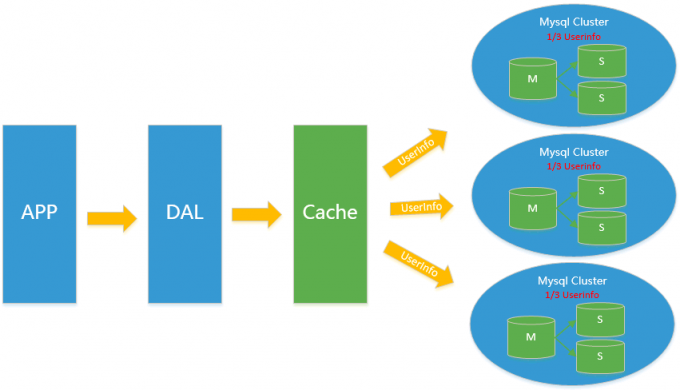
Mysql的拓展性能
MySQL数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常的慢,不容易快速恢复数据库。比如1000万4KB大小的文本就接近40GB的大小,如果能把这些数据从MySQL省去,MySQL将变得非常的小。关系数据库很强大,但是它并不能很好的应付所有的应用场景。MySQL的扩展性差(需要复杂的技术来实现),大数据下IO压力大,表结构更改困难,正是当前使用MySQL的开发人员面临的问题。
今天的架构
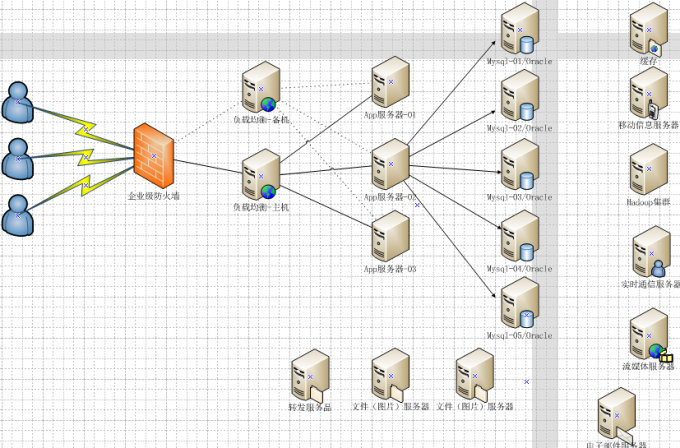
解答
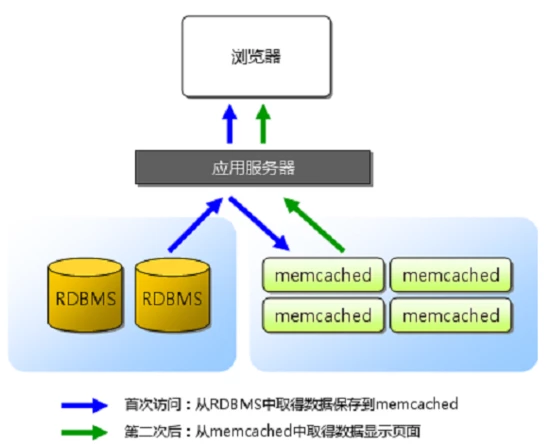
多数的Web数据应用都保存到了关系型数据库中,如Mysq,Web服务器从中读取数据并在浏览器中显示.但是随着数据量的增大,访问的集中,关系型数据库性能出现瓶颈,响应速度慢导致网站打开延迟等问题,所以Memcached的主要的目的是通过自身内存中缓存关系型数据库查询的查询结果,减少数据库自身被访问的次数,以提高动态Web应用速度,提高网站架构的并发能力和拓展属性
通过事先规划好的系统内存空间中临时缓存数据库中的各种数据,已达到减少前端业务服务对关系型数据库的直接高并发访问,从而达到提升大规模数据集群中动态服务的并发访问能力.
Web服务器读取数据时先读Memcached服务器,如果Memcached没有.则向数据库请求数据.然后Web再报请求到的数据发送到Memcached.
Memcached 特征
协议简单
因此,通过telnet也能在memcached上保存数据、取得数据。下面是例子。
$ telnet localhost 11211 Trying 127.0.0.1 Connected to localhost.localdomain (127.0.0.1). Escape character is '^]'. set foo 0 0 3 (保存命令) bar (数据) STORED (结果) get foo (取得命令) VALUE foo 0 3 (数据) bar (数据)
事件处理
libevent是个程序库,它将Linux的epoll、BSD类操作系统的kqueue等事件处理功能封装成统一的接口。即使对服务器的连接数增加,也能发挥O(1)的性能。memcached使用这个libevent库,
因此能在Linux、BSD、Solaris等操作系统上发挥其高性能。关于事件处理,可以参考Dan Kegel的The C10K Problem。
内存存储方式
为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重启memcached、重启操作系统会导致全部数据消失。
另外,内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。memcached本身是为缓存而设计的服务器,因此并没有过多考虑数据的永久性问题。
Memcached 不互通信的分布式
memcached尽管是“分布式”缓存服务器,但服务器端并没有分布式功能。各个memcached不会互相通信以共享信息。那么,怎样进行分布式呢?这完全取决于客户端的实现。本文也将介绍memcached的分布式。

memcached的分布式
memcached的内存存储
最近的memcached默认的情况下采用了名为Slab Allocation的机制分配,在该机制出现之前,内存的分配通过对所有记录进行简单的malloc和free来进行的.但是这种方式会导致内存碎片,家中操作系统内存管理的负担,在最坏的情况下会导致操作系统memcached进程,Slab Allocation就是为了解决这个问题的
原理
将分配的内存分割成各种尺寸的块(chunk), 并把尺寸相同的块分成组(chunk的集合),每个chunk集合被称为slab。

Slab Allocation可以重复使用已分配的内存的目的.分配到的内存不会被释放,而是被重复利用.
主要术语
Page
分配给Slab的内存空间,默认是1MB.会分配给Slab之后跟库slab的大小切分成chunk.
Chunk
用于缓存记录的内存空间
Slab Class
特定大小的chunk的组
选择存储记录的组的方法
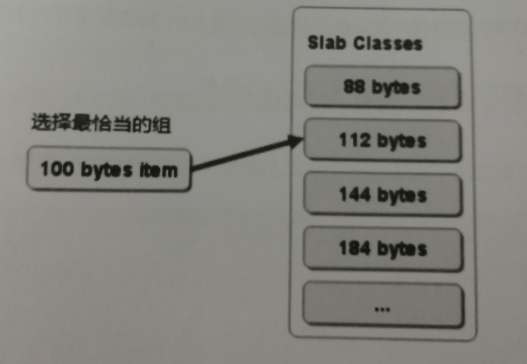
缺点
由于分配的时特定长度的内存,因此无法又想利用分配的内存.比如将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费掉了
对于该问题目前还没有完美的解决方案,但在文档中记载了比较有效的解决方案。
The most efficient way to reduce the waste is to use a list of size classes that closely matches (if that’s at all possible) common sizes of objects that the clients of this particular installation of memcached are likely to store.
就是说,如果预先知道客户端发送的数据的公用大小,或者仅缓存大小相同的数据的情况下, 只要使用适合数据大小的组的列表,就可以减少浪费。
但是很遗憾,现在还不能进行任何调优,只能期待以后的版本了。 但是,我们可以调节slab class的大小的差别。 接下来说明growth factor选项。
使用Growth Factor进行调优
memcached在启动时指定 Growth Factor因子(通过-f选项), 就可以在某种程度上控制slab之间的差异。默认值为1.25。 但是,在该选项出现之前,这个因子曾经固定为2,称为“powers of 2”策略。
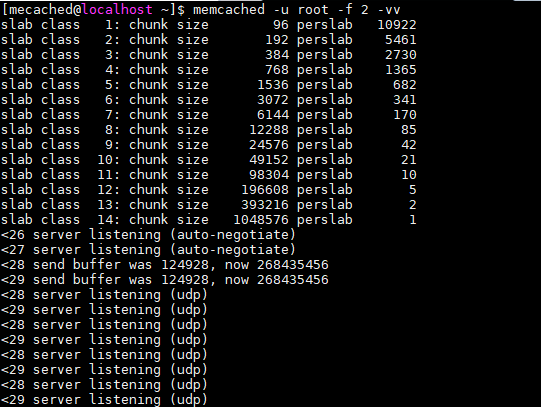
可以看到从从1字节开始组的大小增大为原来的2倍,这样设置的问题是slab之间的差别比较大,有些情况下就比较浪费内存,因此,为了减少内存浪费,两年前追加了growth facthor这个选项

从图中可见,组间的差距比2时小的多,更合适缓存几百字节的记录,从上面的输出结果来看,可能会有些计算误差.这些误差是为了保持字节数的对齐故意设置的.
将memcached引入产品,或是直接使用默认值进行部署时,最好是重新计算一下数据的预期平均长度,调整growth factor以获得恰当的长度,避免内存的浪费.
查看memcached的内部状态
首先开启memcached服务
其次连接服务
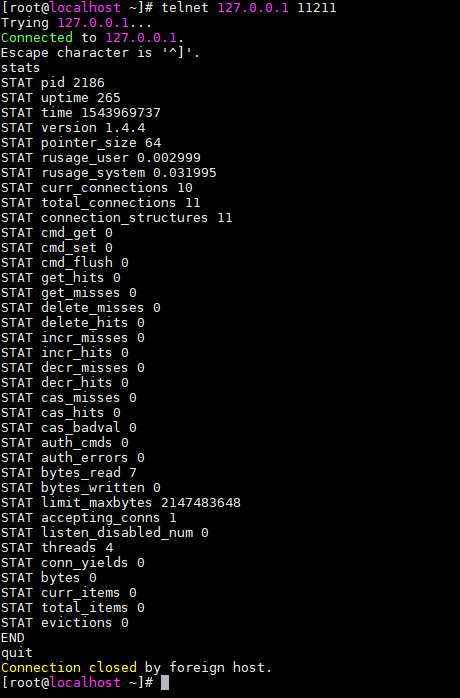
详细的信息可以参考memcached软件包内的protocol.txt
查看slabs的使用状况

参数的含义
| 列 | 含义 |
|---|---|
| # | slab class编号 |
| Item_Size | Chunk大小 |
| Max_age | LRU内最旧的记录生存时间 |
| Pages | 分配给Slab的页数 |
| Count | Slab内的记录数 |
| Full? | Slab内是否含有空闲chunk |
| Evicted | 从LRU中移除未过期item的次数 |
| Evict_Time | 最后被移除缓存的时间,0表示当前就有被移除 |
| OOM | M参数 |
memcached的分布式
下面假设memcached有三台服务器node1-node3,保存的键名是”tokyo”,“kanagawa”,“chiba”,“saitma”,“gunma”
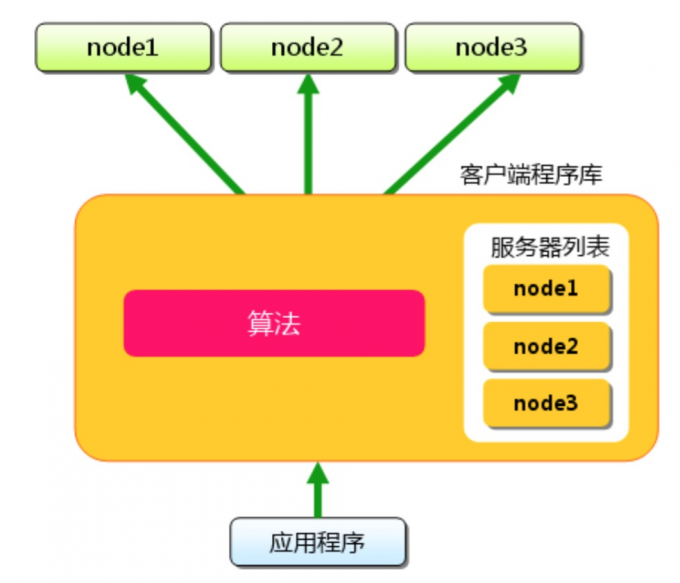
首先向memcached中添加“tokyo”,将“tokyo”传给客户端程序库后,客户端实现的算法就会根据”键”来决定保存数据的memcached服务器,服务器选定之后,命令他保存”totyo”及其值.同样的”kanagawa”,“chiba”,“saitma”,“gunma”都是先选择服务器再保存的.

接下来获取保存的数据,获取时也要获取的键”tokyo”传递给函数库.函数库通过与数据库保存相同的算法,根据”键”选择服务器.使用的算法相同,就能选中与保存相同的服务器,然后发送get命令.只要数据没有因为某些原因被删除,就能获得保存的值.
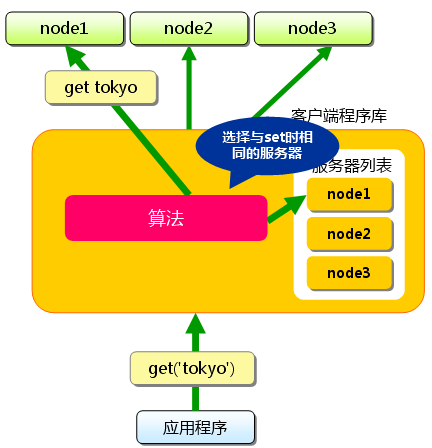
这样不同的键保存到不同的不同的不同的服务器上,就实现memcached的分布式,memcached服务器增多后,键就会分散,即使一台memcached服务器发生故障无法链接,也不会影响其他的缓存,系统依旧能够继续运行.
算法实现
首先求的字符串的CRC根据该值处于服务器节点数目得到的余数决定服务器,当选择的服务器无法连接的时候,Cache:Memcached将会链接次数添加到键之后,再次计算哈希值并尝试链接.这个动作叫做rehash.
use strict;
use warnings;
use String::CRC32;
my @nodes = @ARGV;
my @keys = (’a’..’z');
my %nodes;
foreach my $key ( @keys ) {
my $hash = crc32($key);
my $mod = $hash % ( $#nodes + 1 );
my $server = $nodes[ $mod ];
push @{ $nodes{ $server } }, $key;
}
foreach my $node ( sort keys %nodes ) {
printf “%s: %s
”, $node, join “,”, @{ $nodes{$node} };
执行结果 tokyo => node2 kanagawa => node3 chiba => node2 saitama =>node1 gunma =>node1
求余算法缺点
添加或移除服务器时,缓存重组的代价相当巨大。 添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器, 从而影响缓存的命中率。
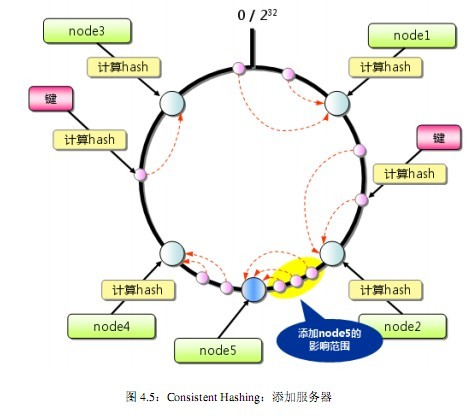
Consistent Hashing算法
1) 首先求出memcached服务器(节点)的哈希值,并将其配置到0~232的圆(continuum)上。 2) 然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。 3) 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。
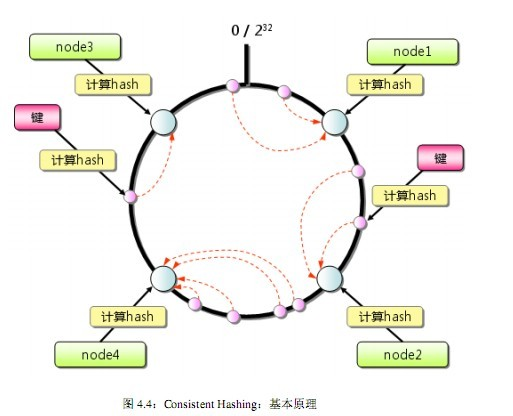
Consistent Hashing:添加服务器