这部分我们讨论结构学习,也就是 graph 的边我们并不清楚。很自然我们可以用 fully observed 数据来做,但是也可能碰到有 missing data 的情况。一般来说前者是比较常见的。就方法而言,我们有 constraint-based structure learning 与 score-based structure learning 两种选择,后者在实际中更常用一些。具体做之前我们需要清楚这样一件事情,我们能做到的只是发现 I-equivalent 的 graph 结构,同一个分布的 perfect map 之间我们无法区分开来。多数情况下,我们如果少做了 independency assertion 就会导致获得的 graph 边增多,这带来许多额外的参数;而少做获得的不精确的结构可能导致不能捕获数据中特殊的结构。实际操作中,由于数据的有限,我们往往倾向于更简单的模型(边较少),这样泛化能力会相对较好。
constraint-based structure learning
所谓 constraint-based structure learning 的思路实际上来源于前面关于 perfect map 的研究,以下算法可以帮助我们通过多项式次的 independence test 解决问题:
- 首先构造一个 skeleton,我们从完全图开始,对所有的
对,进行检验,同时遍历所有的 candidate set(大小不超过给定值的子集)中的,看看当前数据是否支持给定这个子集后
记录下来,获得的图和
就是我们的 skeleton
- 在 skeleton 中寻找 immoral 情形,即将以上无向图转换成有向,这主要是需要对 intercausal 的情形进行特殊处理:因为无向图给定 V 型转折点后两头是独立的,而对有向图来说这恰好不是独立的。为此我们在 skeleton 中寻找具有连接
但没有
的三元组,如果的确
,那么就印证了前面的 intercausal 的情形,因此将边设为我们需要的方向即可。
- 在此之后还有一些边仍未获得有向边,我们利用三条规则不断的加上方向即可:
- 如果
,则替换为
- 如果
,则将
- 如果
。
- 如果

这个算法将返回一个 PDAG(partially directed acyclic graph)。那么现在的问题就是如何检验条件独立性了,这部分在统计里面是一个重要的研究课题。对离散 r.v.s 来说,
")
Pr(Y)")
除了这些思路以外,很重要的一个处理连续 r.v.s 的思路是 kernel-based independence test,这最早来源于一个很著名的命题,即如果两个随机变量 
 g(Y) = mathbb{E} f(X) mathbb{E} g(Y)")
score-based structure learning
既然前面这么强调 MLE,没有结构的时候很自然的想法是是否我们可以拿 log-likelihood 也作为评估 graph 好坏的的标准呢?比如我们可以如下定义一个 ML score,
 = max_ heta frac{1}{N}log Pr (D mid heta, G)")
很可惜的是这样做一般不会 work。这是因为,一般的有
亦即最大对数似然等于 empirical 分布下,每个随机变量与其 parent r.v.s 的互信息减去每个随机变量的熵。这意味着我们通过增加“边”,也就是引入随机变量与其 parent 之间的依赖关系会在该 score 上获得额外的互信息项,而这个互信息是非负的,换言之这个 score 就会变大,因此 empirically speaking 当我们的样本有限的时候,使用 ML score 总会倾向增加边,因此获得的是一个 overfit 的 graph。这不是我们想要看到的事情。避免 overfit 的做法我们仍旧回到 Bayesian 的思路上来,
 propto Pr(D mid G) Pr (G)")
而这里
 = int Pr(Dmid heta) Pr( heta mid G)\,mathrm{d} heta")
与 ML score 不同在于,我们这里并没有仅仅使用一个参数(即 MLE)来进行估计,而是在所有可能的 
 approx mathbb{E} logPr(X mid D, G)")
因此得到的是类似泛化误差的东西。对于 CPD 是 multinomial 的情形,我们可以选用 Dirichlet 作为先验(即 ")

 = ell(hat{ heta}mid D) - frac{log N}{2} mathrm{dim}\, G + O(1)")
注意到前面两项,我们不难发现它就是 BIC(见这里),这里 

这里一直都没介绍 ")
 propto c^{|G|}")
")

搜索问题
前面求得了一个合适的 score 来评估不同 graph 的性能以后,我们还需要一个算法帮助我们将这个最优的结构搜索出来。这个搜索问题有训练数据、scoring function,候选网络结构。相对来说候选网络结构如果是 tree (如果不联通,可以是 forest)的话,我们可以很容易求解。当我们的 score 是 decomposable 的时候我们发现一个重要的观察,tree 意味着每个 r.v. 最多有一个 parent,这样我们根据 decomposability 把每个局部的如果是 parent 的 score 算出来,
 - S(G^varnothing) = sum_i left( mathrm{Fam}_G (X_i mid pi(X_i)) - mathrm{Fam}_{G^varnothing} (X_i mid pi(X_i))
ight)")
然后根据这个 weight
 - mathrm{Fam}_{G^varnothing} (X_i)")
加入边直到或者出现环,或者我们的 score 不再增加即可。这样问题就等价于寻找 maximum weighting tree/forest 了。如果 I-equivalent class 具有相同的 score,这里 
对一般的 graph 来说,比如我们限制 parent 个数为 
的特例,很不幸的是如果

关于 missing data
由于 hidden r.v.s 我们甚至不晓得其取值、类型,这使得存在 missing data 时候的 structure learning 变得更为复杂。在前面的积分  Pr( heta mid G)\, mathrm{d} heta")
\, mathrm{d} w")
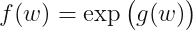
")
 approx (w - w_0)^ op C (w - w_0) + log f(w_0)")
除了这种近似以外还有所谓 Cheeseman-Stutz score,这是用 Laplace approximation 的极限情况推出的更紧的近似。另外我们可以从 中进行 sampling,用样本来近似这个积分,这被称为 candidate method。最后是使用 variational bound 对这个进行近似。
有这些选择好的 score 以后,我们就可以进行 search 了。除了直接应用以上讲述的策略以外,我们还可以将 EM 的思想引入到这个问题上来。前面 Cheeseman-Stutz score 里面其实也用到了这个思想,就是我们如果用 complete data 一切就很容易计算了,继而我们就可以直接应用 structure learning 测策略学习结构,并且最后更新对应的参数。而给定参数后,我们又能生成新的 complete data。这也就是所谓的 structure EM 的策略。比起前面的 EM 多了一步对结构的学习。
关于 undirected graph
对 MRF 进行结构学习相对容易,前面的 constraint-based 方法由于只需要判定到第一步就完了,所以更简单。相反使用 score-based 方法会变的复杂(由于 partition function 的存在)。我们只考虑 log-linear model,这个时候将 ML score 或者 BIC 代入后一个很重要的观点就变成了 model selection 向 feature selection 的转化,因为 feature 是定义在 clique 上的函数,那么如果某些 feature 被剔除掉了,就等价于某些边消失了。这时由于 BIC 不是一个连续可通过梯度优化的东西,我们找到了 
关于 Bayesian averaging
想法很简单,如果 structure 未知,我们会在 structure 上设定先验,然后在后验上进行对测试的推断;就跟我们对参数的处理如出一辙。问题是我们有必要这么做吗?如果我们有很多数据,关于结构的概率分布就会集中在 true structure 上,因此我们这样做有点得不偿失,不如直接先 learn structure 而后在一个 structure 上进行预测,这样近似就是有道理的。但是如果数据较少,这时我们会发现可能有多个 structure(未必是 true structure)都会有相当的 score,这时我们就有理由不再做前面这种近似了。
在一般情况下我们也能猜出来是很难做到这些的,一个比较重要的情况是如果我们已知 graph 仅仅出现在符合某个 r.v.s 的序关系 


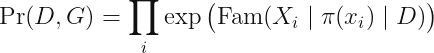
可以得到一个简化的表达。一般情况下只能借助 sampling 的策略来做了。
——————
And God heard the voice of the lad; and the angel of God called to Hagar out of heaven, and said to her, What ails you, Hagar? fear not; for God has heard the voice of the lad where he is.