关注微信公众号:FocusBI 查看更多文章;加QQ群:808774277 获取学习资料和一起探讨问题。
《商业智能教程》pdf下载地址
链接:https://pan.baidu.com/s/1f9VdZUXztwylkOdFLbcmWw 密码:2r4v
在为企业实施商业智能时,大部分都是使用内部数据建模和可视化;以前极少企业有爬虫工程师来为企业准备外部数据,最近一年来Python爬虫异常火爆,企业也开始招爬虫工程师为企业丰富数据来源。
我使用Python 抓取过一些网站数据,如:美团、点评、一亩田、租房等;这些数据并没有用作商业用途而是个人兴趣爬取下来做练习使用;这里我已 一亩田为例使用 scrapy框架去抓取它的数据。
一亩田
它是一个农产品网站,汇集了中国大部分农产品产地和市场行情,发展初期由百度系的人员创建,最初是招了大量的业务员去农村收集和教育农民把产品信息发布到一亩田网上..。
一亩田一开始是网页版,由于爬虫太多和农户在外劳作使用不方便而改成APP版废弃网页版,一亩田App反爬能力非常强悍;另外一亩田有一亩田产地行情和市场行情网页版,它的信息量也非常多,所以我选择爬取一亩田产地行情数据。
爬取一亩田使用的是Scrapy框架,这个框架的原理及dome我在这里不讲,直接给爬取一亩田的分析思路及源码;
一亩田爬虫分析思路
首先登陆一亩田产地行情:http://hangqing.ymt.com/chandi,看到农产品分类
单击水果分类就能看到它下面有很多小分类,单击梨进入水果梨的行情页,能看到它下面有全部品种和指定地区选择一个省就能看到当天的行情和一个月的走势;
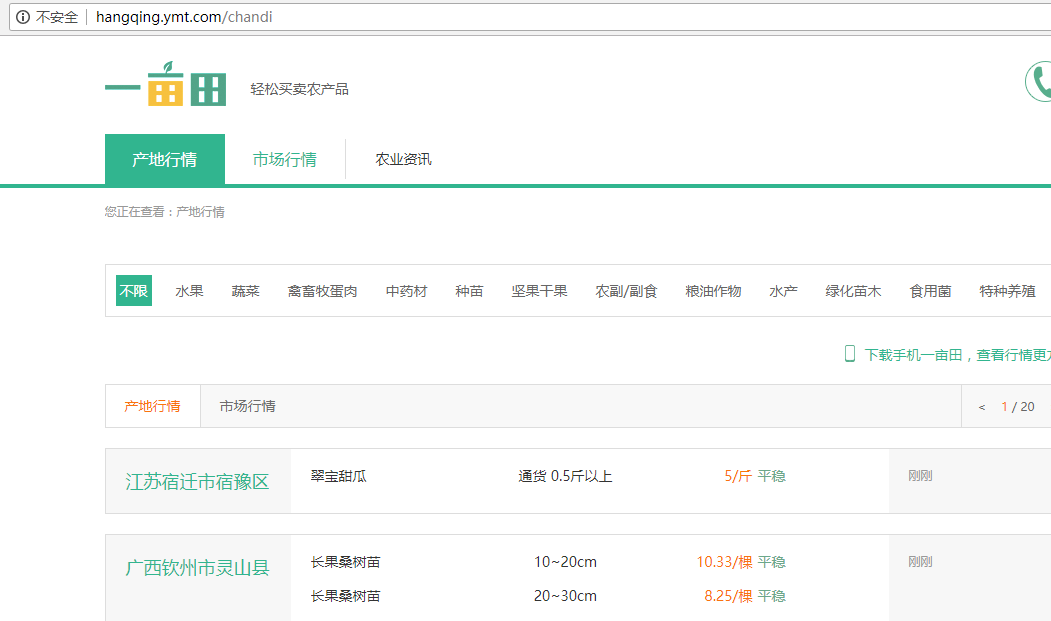
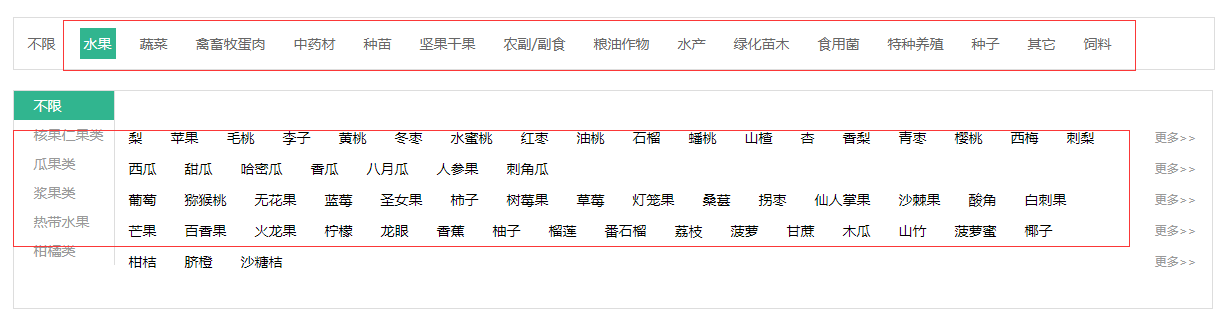
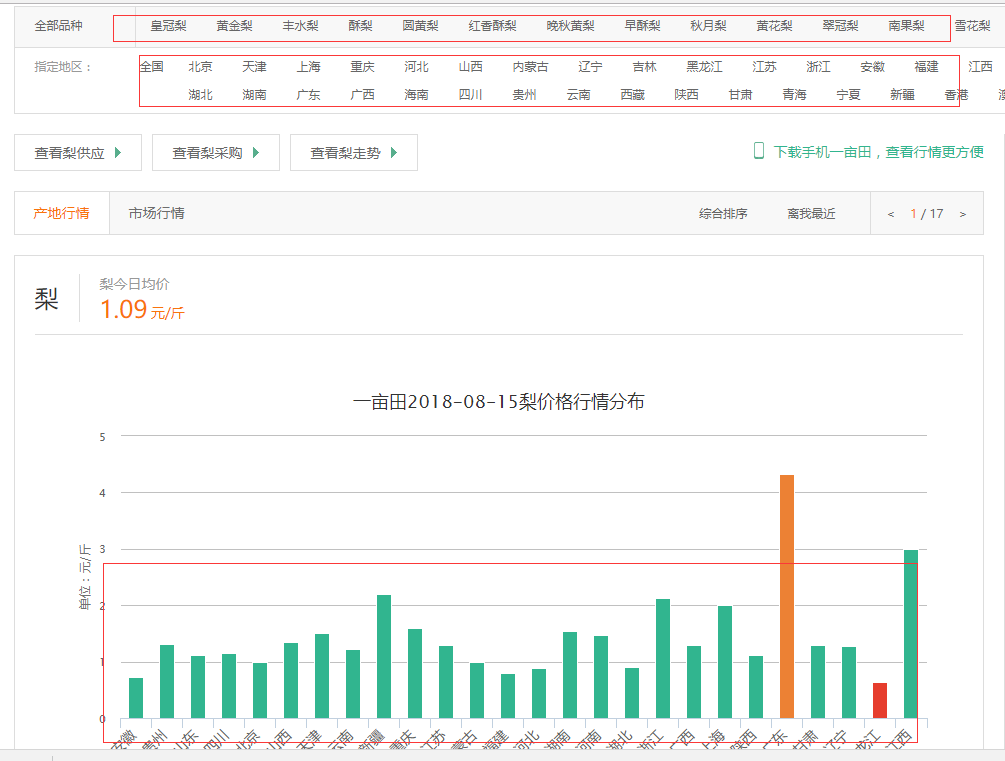
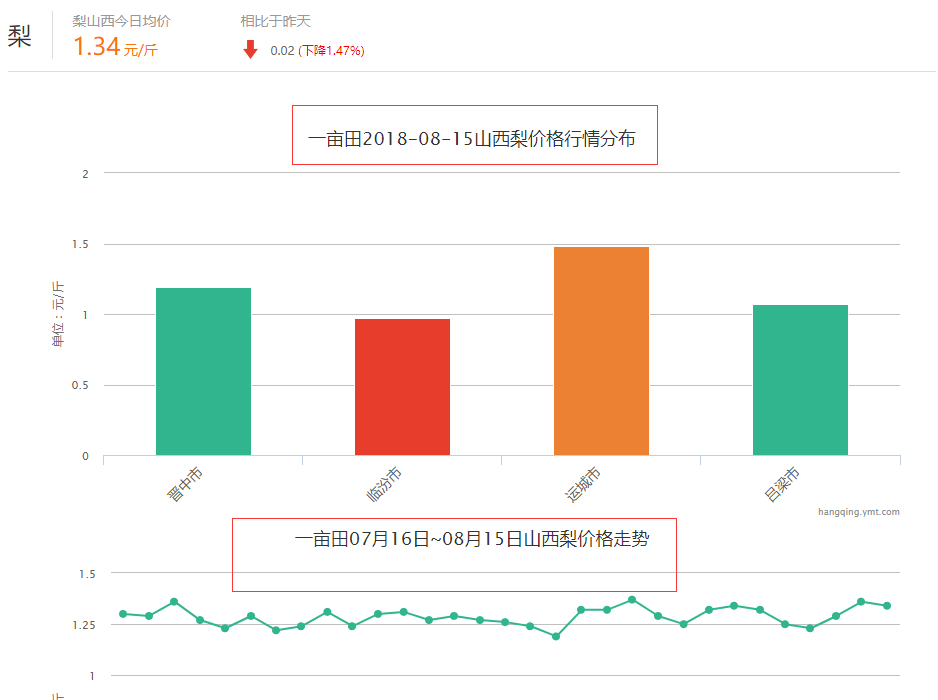
看到这一连串的网页我就根据这个思路去抓取数据。
一亩田爬虫源码
1.首先创建一个Spider
2.行情数据
抓取大类、中类、小类、品种 hangqing.py


1 # -*- coding: utf-8 -*- 2 import scrapy 3 from mySpider.items import MyspiderItem 4 from copy import deepcopy 5 import time 6 7 8 class HangqingSpider(scrapy.Spider): 9 name = "hangqing" 10 allowed_domains = ["hangqing.ymt.com"] 11 start_urls = ( 12 'http://hangqing.ymt.com/', 13 ) 14 15 # 大分类数据 16 def parse(self, response): 17 a_list = response.xpath("//div[@id='purchase_wrapper']/div//a[@class='hide']") 18 19 for a in a_list: 20 items = MyspiderItem() 21 items["ymt_bigsort_href"] = a.xpath("./@href").extract_first() 22 items["ymt_bigsort_id"] = items["ymt_bigsort_href"].replace("http://hangqing.ymt.com/common/nav_chandi_", "") 23 items["ymt_bigsort_name"] = a.xpath("./text()").extract_first() 24 25 # 发送详情页的请求 26 yield scrapy.Request( 27 items["ymt_bigsort_href"], 28 callback=self.parse_medium_detail, 29 meta={"item": deepcopy(items)} 30 ) 31 32 33 # 中分类数据 其中小类也包含在其中 34 def parse_medium_detail(self, response): 35 items = response.meta["item"] 36 li_list = response.xpath("//div[@class='cate_nav_wrap']//a") 37 for li in li_list: 38 items["ymt_mediumsort_id"] = li.xpath("./@data-id").extract_first() 39 items["ymt_mediumsort_name"] = li.xpath("./text()").extract_first() 40 yield scrapy.Request( 41 items["ymt_bigsort_href"], 42 callback=self.parse_small_detail, 43 meta={"item": deepcopy(items)}, 44 dont_filter=True 45 ) 46 47 # 小分类数据 48 def parse_small_detail(self, response): 49 item = response.meta["item"] 50 mediumsort_id = item["ymt_mediumsort_id"] 51 if int(mediumsort_id) > 0: 52 nav_product_id = "nav-product-" + mediumsort_id 53 a_list = response.xpath("//div[@class='cate_content_1']//div[contains(@class,'{}')]//ul//a".format(nav_product_id)) 54 for a in a_list: 55 item["ymt_smallsort_id"] = a.xpath("./@data-id").extract_first() 56 item["ymt_smallsort_href"] = a.xpath("./@href").extract_first() 57 item["ymt_smallsort_name"] = a.xpath("./text()").extract_first() 58 yield scrapy.Request( 59 item["ymt_smallsort_href"], 60 callback=self.parse_variety_detail, 61 meta={"item": deepcopy(item)} 62 ) 63 64 # 品种数据 65 def parse_variety_detail(self, response): 66 item = response.meta["item"] 67 li_list = response.xpath("//ul[@class='all_cate clearfix']//li") 68 if len(li_list) > 0: 69 for li in li_list: 70 item["ymt_breed_href"] = li.xpath("./a/@href").extract_first() 71 item["ymt_breed_name"] = li.xpath("./a/text()").extract_first() 72 item["ymt_breed_id"] = item["ymt_breed_href"].split("_")[2] 73 74 yield item 75 76 else: 77 item["ymt_breed_href"] = "" 78 item["ymt_breed_name"] = "" 79 item["ymt_breed_id"] = -1 80 81 yield item
3.产地数据
抓取省份、城市、县市 chandi.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from mySpider.items import MyspiderChanDi 4 from copy import deepcopy 5 6 7 class ChandiSpider(scrapy.Spider): 8 name = 'chandi' 9 allowed_domains = ['hangqing.ymt.com'] 10 start_urls = ['http://hangqing.ymt.com/chandi_8031_0_0'] 11 12 # 省份数据 13 def parse(self, response): 14 # 产地列表 15 li_list = response.xpath("//div[@class='fl sku_name']/ul//li") 16 for li in li_list: 17 items = MyspiderChanDi() 18 items["ymt_province_href"] = li.xpath("./a/@href").extract_first() 19 items["ymt_province_id"] = items["ymt_province_href"].split("_")[-1] 20 items["ymt_province_name"] = li.xpath("./a/text()").extract_first() 21 22 yield scrapy.Request( 23 items["ymt_province_href"], 24 callback=self.parse_city_detail, 25 meta={"item": deepcopy(items)} 26 ) 27 28 # 城市数据 29 def parse_city_detail(self, response): 30 item = response.meta["item"] 31 option = response.xpath("//select[@class='location_select'][1]//option") 32 33 if len(option) > 0: 34 for op in option: 35 name = op.xpath("./text()").extract_first() 36 if name != "全部": 37 item["ymt_city_name"] = name 38 item["ymt_city_href"] = op.xpath("./@data-url").extract_first() 39 item["ymt_city_id"] = item["ymt_city_href"].split("_")[-1] 40 yield scrapy.Request( 41 item["ymt_city_href"], 42 callback=self.parse_area_detail, 43 meta={"item": deepcopy(item)} 44 ) 45 else: 46 item["ymt_city_name"] = "" 47 item["ymt_city_href"] = "" 48 item["ymt_city_id"] = 0 49 yield scrapy.Request( 50 item["ymt_city_href"], 51 callback=self.parse_area_detail, 52 meta={"item": deepcopy(item)} 53 54 ) 55 56 # 县市数据 57 def parse_area_detail(self, response): 58 item = response.meta["item"] 59 area_list = response.xpath("//select[@class='location_select'][2]//option") 60 61 if len(area_list) > 0: 62 for area in area_list: 63 name = area.xpath("./text()").extract_first() 64 if name != "全部": 65 item["ymt_area_name"] = name 66 item["ymt_area_href"] = area.xpath("./@data-url").extract_first() 67 item["ymt_area_id"] = item["ymt_area_href"].split("_")[-1] 68 yield item 69 else: 70 item["ymt_area_name"] = "" 71 item["ymt_area_href"] = "" 72 item["ymt_area_id"] = 0 73 yield item
4.行情分布
location_char.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 import pymysql 4 import json 5 from copy import deepcopy 6 from mySpider.items import MySpiderSmallProvincePrice 7 import datetime 8 9 10 class LocationCharSpider(scrapy.Spider): 11 name = 'location_char' 12 allowed_domains = ['hangqing.ymt.com'] 13 start_urls = ['http://hangqing.ymt.com/'] 14 15 i = datetime.datetime.now() 16 dateKey = str(i.year) + str(i.month) + str(i.day) 17 db = pymysql.connect( 18 host="127.0.0.1", port=3306, 19 user='root', password='mysql', 20 db='ymt_db', charset='utf8' 21 ) 22 23 def parse(self, response): 24 cur = self.db.cursor() 25 location_char_sql = "select small_id from ymt_price_small where dateKey = {} and day_avg_price > 0".format(self.dateKey) 26 27 cur.execute(location_char_sql) 28 location_chars = cur.fetchall() 29 for ch in location_chars: 30 item = MySpiderSmallProvincePrice() 31 item["small_id"] = ch[0] 32 location_char_url = "http://hangqing.ymt.com/chandi/location_charts" 33 small_id = str(item["small_id"]) 34 form_data = { 35 "locationId": "0", 36 "productId": small_id, 37 "breedId": "0" 38 } 39 yield scrapy.FormRequest( 40 location_char_url, 41 formdata=form_data, 42 callback=self.location_char, 43 meta={"item": deepcopy(item)} 44 ) 45 46 def location_char(self, response): 47 item = response.meta["item"] 48 49 html_str = json.loads(response.text) 50 status = html_str["status"] 51 if status == 0: 52 item["unit"] = html_str["data"]["unit"] 53 item["dateKey"] = self.dateKey 54 dataList = html_str["data"]["dataList"] 55 for data in dataList: 56 if type(data) == type([]): 57 item["province_name"] = data[0] 58 item["province_price"] = data[1] 59 elif type(data) == type({}): 60 item["province_name"] = data["name"] 61 item["province_price"] = data["y"] 62 63 location_char_url = "http://hangqing.ymt.com/chandi/location_charts" 64 small_id = str(item["small_id"]) 65 province_name = str(item["province_name"]) 66 province_id_sql = "select province_id from ymt_1_dim_cdProvince where province_name = "{}" ".format(province_name) 67 cur = self.db.cursor() 68 cur.execute(province_id_sql) 69 province_id = cur.fetchone() 70 71 item["province_id"] = province_id[0] 72 73 province_id = str(province_id[0]) 74 form_data = { 75 "locationId": province_id, 76 "productId": small_id, 77 "breedId": "0" 78 } 79 yield scrapy.FormRequest( 80 location_char_url, 81 formdata=form_data, 82 callback=self.location_char_province, 83 meta={"item": deepcopy(item)} 84 ) 85 86 def location_char_province(self, response): 87 item = response.meta["item"] 88 89 html_str = json.loads(response.text) 90 status = html_str["status"] 91 92 if status == 0: 93 dataList = html_str["data"]["dataList"] 94 for data in dataList: 95 if type(data) == type([]): 96 item["city_name"] = data[0] 97 item["city_price"] = data[1] 98 elif type(data) == type({}): 99 item["city_name"] = data["name"] 100 item["city_price"] = data["y"] 101 102 location_char_url = "http://hangqing.ymt.com/chandi/location_charts" 103 small_id = str(item["small_id"]) 104 city_name = str(item["city_name"]) 105 city_id_sql = "select city_id from ymt_1_dim_cdCity where city_name = "{}" ".format(city_name) 106 cur = self.db.cursor() 107 cur.execute(city_id_sql) 108 city_id = cur.fetchone() 109 110 item["city_id"] = city_id[0] 111 112 city_id = str(city_id[0]) 113 form_data = { 114 "locationId": city_id, 115 "productId": small_id, 116 "breedId": "0" 117 } 118 yield scrapy.FormRequest( 119 location_char_url, 120 formdata=form_data, 121 callback=self.location_char_province_city, 122 meta={"item": deepcopy(item)} 123 ) 124 125 def location_char_province_city(self, response): 126 item = response.meta["item"] 127 128 html_str = json.loads(response.text) 129 status = html_str["status"] 130 131 if status == 0: 132 dataList = html_str["data"]["dataList"] 133 for data in dataList: 134 if type(data) == type([]): 135 item["area_name"] = data[0] 136 item["area_price"] = data[1] 137 elif type(data) == type({}): 138 item["area_name"] = data["name"] 139 item["area_price"] = data["y"] 140 area_name = item["area_name"] 141 area_id_sql = "select area_id from ymt_1_dim_cdArea where area_name = "{}" ".format(area_name) 142 cur1 = self.db.cursor() 143 cur1.execute(area_id_sql) 144 area_id = cur1.fetchone() 145 146 item["area_id"] = area_id[0] 147 148 breed_id_sql = "select breed_id from ymt_all_info_sort where small_id = {} and breed_id > 0".format(item["small_id"]) 149 cur1.execute(breed_id_sql) 150 breed_ids = cur1.fetchall() 151 # print(len(breed_ids)) 152 location_char_url = "http://hangqing.ymt.com/chandi/location_charts" 153 for breed_id in breed_ids: 154 item["breed_id"] = breed_id[0] 155 form_data = { 156 "locationId": str(item["city_id"]), 157 "productId": str(item["small_id"]), 158 "breedId": str(breed_id[0]) 159 } 160 # print(form_data, breed_id) 161 yield scrapy.FormRequest( 162 location_char_url, 163 formdata=form_data, 164 callback=self.location_char_province_city_breed, 165 meta={"item": deepcopy(item)} 166 ) 167 168 def location_char_province_city_breed(self, response): 169 item = response.meta["item"] 170 171 html_str = json.loads(response.text) 172 status = html_str["status"] 173 174 if status == 0: 175 dataList = html_str["data"]["dataList"] 176 for data in dataList: 177 if type(data) == type([]): 178 item["breed_city_name"] = data[0] 179 item["breed_city_price"] = data[1] 180 elif type(data) == type({}): 181 item["breed_city_name"] = data["name"] 182 item["breed_city_price"] = data["y"] 183 184 yield item
5.价格走势
pricedata.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 import pymysql.cursors 4 from copy import deepcopy 5 from mySpider.items import MySpiderSmallprice 6 7 import datetime 8 import json 9 10 11 class PricedataSpider(scrapy.Spider): 12 name = 'pricedata' 13 allowed_domains = ['hangqing.ymt.com'] 14 start_urls = ['http://hangqing.ymt.com/chandi_8031_0_0'] 15 i = datetime.datetime.now() 16 17 def parse(self, response): 18 db = pymysql.connect( 19 host="127.0.0.1", port=3306, 20 user='root', password='mysql', 21 db='ymt_db', charset='utf8' 22 ) 23 cur = db.cursor() 24 25 all_small_sql = "select distinct small_id,small_name,small_href from ymt_all_info_sort" 26 27 cur.execute(all_small_sql) 28 small_all = cur.fetchall() 29 30 for small in small_all: 31 item = MySpiderSmallprice() 32 item["small_href"] = small[2] 33 # item["small_name"] = small[1] 34 item["small_id"] = small[0] 35 yield scrapy.Request( 36 item["small_href"], 37 callback=self.small_breed_info, 38 meta={"item": deepcopy(item)} 39 ) 40 41 def small_breed_info(self, response): 42 item = response.meta["item"] 43 item["day_avg_price"] = response.xpath("//dd[@class='c_origin_price']/p[2]//span[1]/text()").extract_first() 44 item["unit"] = response.xpath("//dd[@class='c_origin_price']/p[2]//span[2]/text()").extract_first() 45 item["dateKey"] = str(self.i.year)+str(self.i.month)+str(self.i.day) 46 47 if item["day_avg_price"] is None: 48 item["day_avg_price"] = 0 49 item["unit"] = "" 50 51 yield item
6.设计字典
items.py
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # http://doc.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 # 行情爬虫字段 11 12 13 class MyspiderItem(scrapy.Item): 14 ymt_bigsort_href = scrapy.Field() 15 ymt_bigsort_id = scrapy.Field() 16 ymt_bigsort_name = scrapy.Field() 17 ymt_mediumsort_id = scrapy.Field() 18 ymt_mediumsort_name = scrapy.Field() 19 ymt_smallsort_id = scrapy.Field() 20 ymt_smallsort_href = scrapy.Field() 21 ymt_smallsort_name = scrapy.Field() 22 ymt_breed_id = scrapy.Field() 23 ymt_breed_name = scrapy.Field() 24 ymt_breed_href = scrapy.Field() 25 26 27 # 产地爬虫字段 28 29 30 class MyspiderChanDi(scrapy.Item): 31 ymt_province_id = scrapy.Field() 32 ymt_province_name = scrapy.Field() 33 ymt_province_href = scrapy.Field() 34 ymt_city_id = scrapy.Field() 35 ymt_city_name = scrapy.Field() 36 ymt_city_href = scrapy.Field() 37 ymt_area_id = scrapy.Field() 38 ymt_area_name = scrapy.Field() 39 ymt_area_href = scrapy.Field() 40 41 # 小类产地价格 42 43 44 class MySpiderSmallprice(scrapy.Item): 45 small_href = scrapy.Field() 46 small_id = scrapy.Field() 47 day_avg_price = scrapy.Field() 48 unit = scrapy.Field() 49 dateKey = scrapy.Field() 50 51 # 小分类 省份/城市/县市 价格 52 53 54 class MySpiderSmallProvincePrice(scrapy.Item): 55 small_id = scrapy.Field() 56 unit = scrapy.Field() 57 province_name = scrapy.Field() 58 province_price = scrapy.Field() # 小类 省份 均价 59 province_id = scrapy.Field() 60 city_name = scrapy.Field() 61 city_price = scrapy.Field() # 小类 城市 均价 62 city_id = scrapy.Field() 63 area_name = scrapy.Field() 64 area_price = scrapy.Field() # 小类 县市均价 65 area_id = scrapy.Field() 66 67 breed_city_name = scrapy.Field() 68 breed_city_price = scrapy.Field() 69 breed_id = scrapy.Field() 70 71 dateKey = scrapy.Field()
7.数据入库
pipelines.py
1 # -*- coding: utf-8 -*- 2 3 from pymongo import MongoClient 4 import pymysql.cursors 5 6 7 class MyspiderPipeline(object): 8 def open_spider(self, spider): 9 # client = MongoClient(host=spider.settings["MONGO_HOST"], port=spider.settings["MONGO_PORT"]) 10 # self.collection = client["ymt"]["hangqing"] 11 pass 12 13 def process_item(self, item, spider): 14 db = pymysql.connect( 15 host="127.0.0.1", port=3306, 16 user='root', password='mysql', 17 db='ymt_db', charset='utf8' 18 ) 19 cur = db.cursor() 20 21 if spider.name == "hangqing": 22 23 # 所有 分类数据 24 all_sort_sql = "insert into ymt_all_info_sort(big_id, big_name, big_href, " 25 "medium_id, medium_name, " 26 "small_id, small_name, small_href, " 27 "breed_id, breed_name, breed_href) " 28 "VALUES({},"{}","{}","{}","{}","{}","{}","{}","{}","{}","{}")".format( 29 item["ymt_bigsort_id"], item["ymt_bigsort_name"], item["ymt_bigsort_href"], 30 item["ymt_mediumsort_id"], item["ymt_mediumsort_name"], 31 item["ymt_smallsort_id"], item["ymt_smallsort_name"], item["ymt_smallsort_href"], 32 item["ymt_breed_id"], item["ymt_breed_name"], item["ymt_breed_href"]) 33 34 try: 35 cur.execute(all_sort_sql) 36 db.commit() 37 38 except Exception as e: 39 db.rollback() 40 finally: 41 cur.close() 42 db.close() 43 44 return item 45 46 elif spider.name == "chandi": 47 48 # 所有的产地数据 49 all_cd_sql = "insert into ymt_all_info_cd(" 50 "province_id, province_name, province_href, " 51 "city_id, city_name, city_href," 52 "area_id, area_name, area_href) " 53 "VALUES({},"{}","{}",{},"{}","{}",{},"{}","{}")".format( 54 item["ymt_province_id"], item["ymt_province_name"], item["ymt_province_href"], 55 item["ymt_city_id"], item["ymt_city_name"], item["ymt_city_href"], 56 item["ymt_area_id"], item["ymt_area_name"], item["ymt_area_href"]) 57 try: 58 # 产地数据 59 cur.execute(all_cd_sql) 60 db.commit() 61 except Exception as e: 62 db.rollback() 63 64 finally: 65 cur.close() 66 db.close() 67 68 return item 69 70 elif spider.name == "pricedata": 71 avg_day_price_sql = "insert into ymt_price_small(small_href, small_id, day_avg_price, unit, dateKey) " 72 "VALUES("{}",{},{},"{}","{}")".format(item["small_href"], item["small_id"], item["day_avg_price"], item["unit"], item["dateKey"]) 73 try: 74 cur.execute(avg_day_price_sql) 75 db.commit() 76 except Exception as e: 77 db.rollback() 78 finally: 79 cur.close() 80 db.close() 81 82 elif spider.name == "location_char": 83 location_char_sql = "insert into ymt_price_provice(small_id, province_name, provice_price, city_name, city_price, area_name, area_price,unit, dateKey, area_id, city_id, provice_id, breed_city_name, breed_city_price, breed_id) " 84 "VALUES({},"{}",{},"{}",{},"{}",{},"{}",{},{},{},{},"{}",{},{})".format(item["small_id"], item["province_name"], item["province_price"], item["city_name"], item["city_price"], 85 item["area_name"], item["area_price"], item["unit"], item["dateKey"], 86 item["area_id"], item["city_id"], item["province_id"], 87 item["breed_city_name"], item["breed_city_price"], item["breed_id"]) 88 try: 89 cur.execute(location_char_sql) 90 db.commit() 91 except Exception as e: 92 db.rollback() 93 finally: 94 cur.close() 95 db.close() 96 97 else: 98 cur.close() 99 db.close()
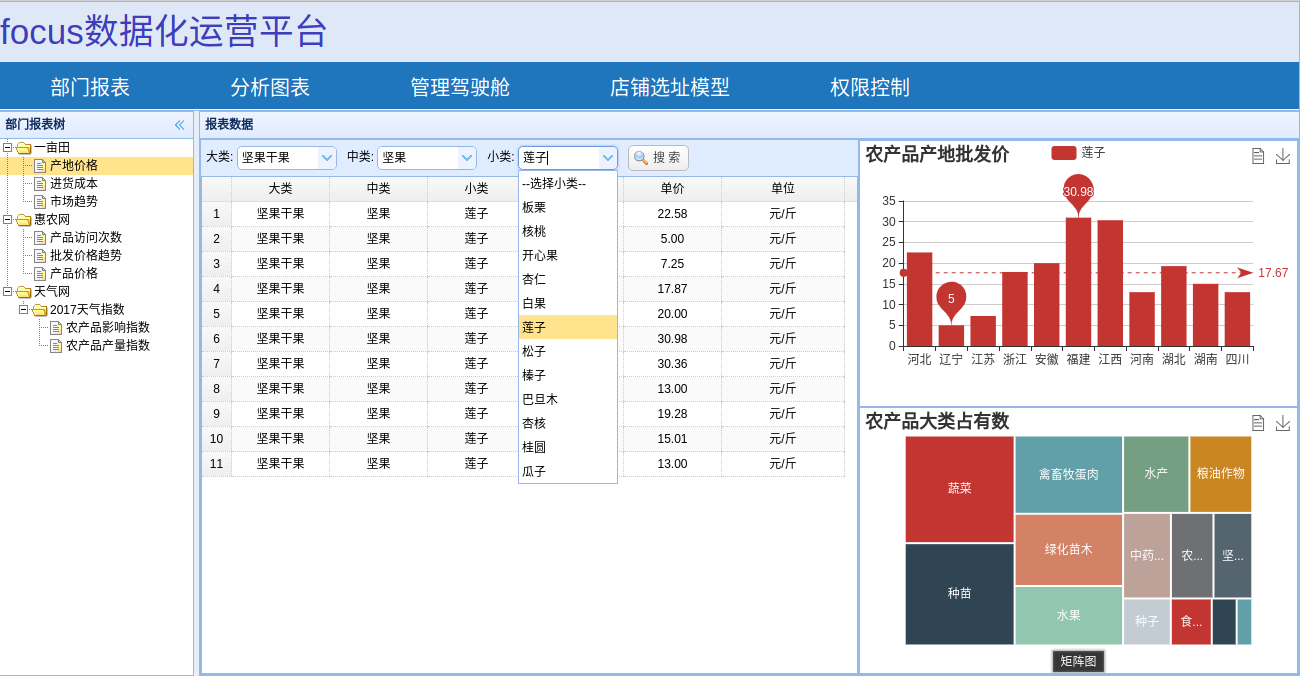
最后结果
出于个人兴趣,最后把爬取下来的农产品信息变成了一个WEB系统。
历史文章:
FocusBI: 使用Python爬虫为BI准备数据源(原创)