MySQL内建的复制功能是构建大型,高性能应用程序的基础。将MySQL的数据分布到多个系统上去,这种分布的机制,是通过将mysql的某一台主机的数据复制到其它主机(slave)上,并重新执行一遍来实现。
复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器。主服务器将更新写入二进制日志文件,并维护文件的一个索引以跟踪日志循坏,这些日志可以记录发送到从服务器的更新。当一个从服务器
连接主服务器时,它通知主服务器从服务器在日志中读取的最后一次成功更新的位置。从服务器接收从那时起发生的任何更新,然后封锁并等待主服务器通知的更新。
需注意的是:
在进行mysql复制时,所有对复制中的表的更新必须在主服务器上进行。否则必须要小心,以避免用户对主服器上的表进行更新与对从服务器上的表所进行更新之间的冲突。
(1)mysql支持哪些复制
a.基于语句的复制:在主服务器上执行的sql语句,在从服务器上执行同样的语句。mysql默认采用基于语句的复制,效率边角高。一旦发现没法精确复制时,会自动选着基于行的复制。
b.基于行的复制:把改变的内容复制过去,而不是把命令在从服务器上执行一遍。从mysql 5.0开始支持
c.混合类型的复制:默认采用基于语句的复制,一旦发现基于语句的无法精确复制时,就会采用基于行的复制。
(2)mysql复制解决的问题
a.数据分布(data distribution)
b.负载平衡(load balancing)
c.数据备份(backup),保证数据安全
d.高可用性与容错行(high availability and failover)
e.实现读写分离,缓解数据库压力
(3)mysql主从复制原理
master服务器将数据的改变记录二进制binlog日志,当master上的数据发生改变时,则将其改变写入二进制日志中;slave服务器会在一定时间间隔内对master二进制日志进行探测其是否发生改变,
如果发生改变,则开始一个I/O Thread请求master二进制事件,同时主节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至从节点本地的中继日志中,从节点将启动SQL线程从中继日志
中读取二进制日志,在本地重放,使得其数据和主节点的保持一致,最后I/O Thread和SQL Thread将进入睡眠状态,等待下一次被唤醒。
注意几点:
1--master将操作语句记录到binlog日志中,然后授予slave远程连接的权限(master一定要开启binlog二进制日志功能;通常为了数据安全考虑,slave也开启binlog功能)。
2--slave开启两个线程:IO线程和SQL线程。其中:IO线程负责读取master的binlog内容到中继日志relay log里;SQL线程负责从relay log日志里读出binlog内容,并更新到slave的数据库里,这样就能保证slave数据和 master数据保持一致了。
3--Mysql复制至少需要两个Mysql的服务,当然Mysql服务可以分布在不同的服务器上,也可以在一台服务器上启动多个服务。
4--Mysql复制最好确保master和slave服务器上的Mysql版本相同(如果不能满足版本一致,那么要保证master主节点的版本低于slave从节点的版本)
5--master和slave两节点间时间需同步
Mysql复制的流程图如下:
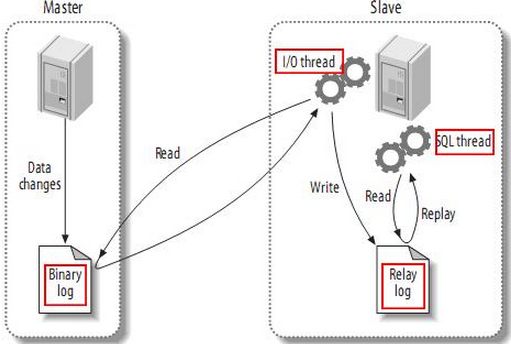
如上图所示:
Mysql复制过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。
第二部分就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。
SQL slave thread(SQL从线程)处理该过程的最后一步。SQL线程从中继日志读取事件,并重放其中的事件而更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。复制过程有一个很重要的限制——复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。
(4)mysql复制的模式
1--主从复制:主库授权从库远程连接,读取binlog日志并更新到本地数据库的过程;主库写数据后,从库会自动同步过来(从库跟着主库变);
2--主主复制:主从相互授权连接,读取对方binlog日志并更新到本地数据库的过程;只要对方数据改变,自己就跟着改变;
(5)mysql主从复制优点
1--在从服务器可以执行查询工作(即我们常说的读功能),降低主服务器压力;(主库写,从库读,降压)
2--在从主服务器进行备份,避免备份期间影响主服务器服务;(确保数据安全)
3--当主服务器出现问题时,可以切换到从服务器。(提升性能)
(6)mysql主从复制工作流程细节
a. MySQL支持单向、异步复制,复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器。MySQL复制基于主服务器在二进制日志中跟踪所有对数据库的更改(更新、删除等等)。因此,要进行复制,必须在主服务器上启用二进制日志。每个从服务器从主服务器接收主服务器上已经记录到其二进制日志的保存的更新。当一个从服务器连接主服务器时,它通知主服务器定位到从服务器在日志中读取的最后一次成功更新的位置。从服务器接收从那时起发生的任何更新,并在本机上执行相同的更新。然后封锁并等待主服务器通知新的更新。从服务器执行备份不会干扰主服务器,在备份过程中主服务器可以继续处理更新。
b. MySQL使用3个线程来执行复制功能,其中两个线程(Sql线程和IO线程)在从服务器,另外一个线程(IO线程)在主服务器。
当发出START SLAVE时,从服务器创建一个I/O线程,以连接主服务器并让它发送记录在其二进制日志中的语句。主服务器创建一个线程将二进制日志中的内容发送到从服务器。该线程可以即为主服务器上SHOW PROCESSLIST的输出中的Binlog Dump线程。从服务器I/O线程读取主服务器Binlog Dump线程发送的内容并将该数据拷贝到从服务器数据目录中的本地文件中,即中继日志。第3个线程是SQL线程,由从服务器创建,用于读取中继日志并执行日志中包含的更新。在从服务器上,读取和执行更新语句被分成两个独立的任务。当从服务器启动时,其I/O线程可以很快地从主服务器索取所有二进制日志内容,即使SQL线程执行更新的远远滞后。
(7)总结:
主从数据完成同步的过程:
1)在Slave 服务器上执行sart slave命令开启主从复制开关,开始进行主从复制。
2)此时,Slave服务器的IO线程会通过在master上已经授权的复制用户权限请求连接master服务器,并请求从执行binlog日志文件的指定位置(日志文件名和位置就是在配置主从
复制服务时执行change master命令指定的)之后开始发送binlog日志内容
3)Master服务器接收到来自Slave服务器的IO线程的请求后,其上负责复制的IO线程会根据Slave服务器的IO线程请求的信息分批读取指定binlog日志文件指定位置之后的binlog
日志信息,然后返回给Slave端的IO线程。返回的信息中除了binlog日志内容外,还有在Master服务器端记录的IO线程。返回的信息中除了binlog中的下一个指定更新位置。
4)当Slave服务器的IO线程获取到Master服务器上IO线程发送的日志内容、日志文件及位置点后,会将binlog日志内容依次写到Slave端自身的Relay Log(即中继日志)文件
(Mysql-relay-bin.xxx)的最末端,并将新的binlog文件名和位置记录到master-info文件中,以便下一次读取master端新binlog日志时能告诉Master服务器从新binlog
日志的指定文件及位置开始读取新的binlog日志内容
5)Slave服务器端的SQL线程会实时检测本地Relay Log 中IO线程新增的日志内容,然后及时把Relay LOG 文件中的内容解析成sql语句,并在自身Slave服务器上按解析SQL语句
的位置顺序执行应用这样sql语句,并在relay-log.info中记录当前应用中继日志的文件名和位置点
主从复制条件
1)开启Binlog功能
2)主库要建立账号
3)从库要配置master.info(CHANGE MASTER to...相当于配置密码文件和Master的相关信息)
4)start slave 开启复制功能
需要了解的:
1)3个线程,主库IO,从库IO和SQL及作用
2)master.info(从库)作用
3)relay-log 作用
4)异步复制
5)binlog作用(如果需要级联需要开启Binlog)
需要注意:
1)主从复制是异步的逻辑的SQL语句级的复制
2)复制时,主库有一个I/O线程,从库有两个线程,I/O和SQL线程
3)实现主从复制的必要条件是主库要开启记录binlog功能
4)作为复制的所有Mysql节点的server-id都不能相同
5)binlog文件只记录对数据库有更改的SQL语句(来自主库内容的变更),不记录任何查询(select,show)语句
...................................................................................................
彻底解除主从复制关系
1)stop slave;
2)reset slave; 或直接删除master.info和relay-log.info这两个文件;
3)修改my.ini删除主从相关配置参数。
让slave不随MySQL自动启动
修改my.ini 在[mysqld]中增加 skip-slave-start 选项。
做了MySQL主从复制以后,使用mysqldump对数据备份时,一定要注意按照如下方式:
mysqldump --master-data --single-transaction --user=username --password=password dbname> dumpfilename
这样就可以保留 file 和 position 的信息,在新搭建一个slave的时候,还原完数据库, file 和 position 的信息也随之更新,接着再start slave 就可以很迅速
的完成增量同步!
需要限定同步哪些数据库,有3个思路:
1)在执行grant授权的时候就限定数据库;
2)在主服务器上限定binlog_do_db = 数据库名;
3)主服务器上不限定数据库,在从服务器上限定replicate-do-db = 数据库名;
如果想实现 主-从(主)-从 这样的链条式结构,需要设置:
log-slave-updates 只有加上它,从前一台机器上同步过来的数据才能同步到下一台机器。
当然,二进制日志也是必须开启的:
log-bin=/opt/mysql/binlogs/bin-log
log-bin-index=/opt/mysql/binlogs/bin-log.index
还可以设置一个log保存周期:
expire_logs_days=14
主从服务器具体配置
说明:本方式使用冷备份方式,需要将数据库与主数据库手动同步后做下面的设置
1、主服务器设置(设置mysql目录中的my.ini)
#开启bin-log,并指定文件目录和文件名前缀
log_bin=mysql_bin
#需要同步liting数据库。如果是多个同步库,就以此格式另写几行即可。如果不指明对某个具体库同步,就去掉此行,表示同步所有库(除了ignore忽略的库)。
binlog-do-db=newszsczx
#数据库唯一ID,主从的标识号绝对不能重复
server_id=10

使用命令创建复制账号

grant replication slave,replication client on *.* to repl@192.168.1.11.% identified by "pass13";
配置后重启mysql服务器:在命令行输入 show master status;命令查看主服务器是否配置成功
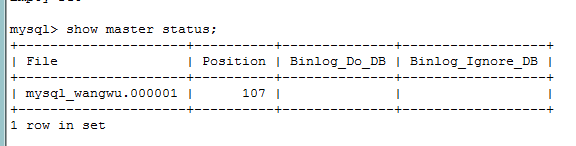
记住这个命令行下的file中 mysql_wang.00001这个文件名
从服务器配置:
#开启bin-log,并指定文件目录和文件名前缀
log_bin=mysql_bin
#数据库唯一ID,主从的标识号绝对不能重复
server_id=2
change master to master_host='180.76.147.125',master_user='repl2019', master_password='1234676',master_port=2658,master_log_file='mysql-wangwu.00001',master_log_pos=0;
同步部分数据有两个思路,1.master只发送需要的;2.slave只接收想要的。
master端:
binlog-do-db 二进制日志记录的数据库(多数据库用逗号,隔开)
binlog-ignore-db 二进制日志中忽略数据库 (多数据库用逗号,隔开)
举例说明:
1)binlog-do-db=YYY 需要同步的数据库,不在内的不同步。(不添加这行表示同步所有)
————————————————
或者slave端配置
replicate-do-db 设定需要复制的数据库(多数据库使用逗号,隔开)
replicate-ignore-db 设定需要忽略的复制数据库 (多数据库使用逗号,隔开)
replicate-do-table 设定需要复制的表
replicate-ignore-table 设定需要忽略的复制表
replicate-wild-do-table 同replication-do-table功能一样,但是可以通配符
replicate-wild-ignore-table 同replication-ignore-table功能一样,但是可以加通配符
如设置要忽略的表名:replicate-ignore-table=newszsczx.dsc_sessions(数据库名.表名)
增加通配符的两个配置
replicate-wild-do-table=db_name.% 只复制哪个库的哪个表
replicate-wild-ignore-table=mysql.% 忽略哪个库的哪个表
查看线程是否在运行中: show processlist;
