delta法则
因此,人们设计了另一个训练法则来克服这个不足,称为 delta 法则(delta rule)。如果训练样本不是线性可分的,那么 delta 法则会收敛到目标概念的最佳 近似。
delta 法则的关键思想是使用梯度下降(gradient descent)来搜索可能权向量的假设空间, 以找到最佳拟合训练样例的权向量。
梯度下降
利用感知器法则的要求是必须训练样本是线性可分的,当样例不满足这条件时,就不能再收敛,为了克服这个要求,引出了delta法则,它会收敛到目标概念的最佳近似!
delta法则的关键思想是利用梯度下降(gradient descent)来搜索可能的权向量的假设空间,以找到最佳拟合训练样例的权向量。
简单的理解,就是训练一个无阈值的感知器,也就是一个线性单元。它的输出o如下:
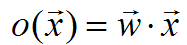
先指定一个度量标准来衡量假设(权向量)相对于训练样例的训练误差(training error)。

其中D是训练样例集合,td 是训练样例d的目标输出,od是线性单元对训练样例d的输出。E(w)是目标输出td和线性单元输出od的差异的平方在所有的训练样例上求和后的一半。我们定义E为w的函数,是因为线性单元的输出o依赖于这个权向量。
在这里,我们对于给定的训练数据使E最小化的假设也就是H中最可能的假设,也就是找到一组权向量能使E最小化。
直观感觉,E函数就是为了让目标输出td 与线性输出od的差距也来越小,也就是越来越接近目标概念。

上图中,红点和绿点是线性不可分的(不能找到一条直线完全分开两类点),但是找到一条线能把两类点尽可能的分开。使错分的点尽可能地少。
为什么感知器不能分开呢?
就在于它是带阈值的,>0 为1,<0为-1。正是这种强制性,使函数输出带有跳跃性(不是可微的),用上图中的图像来表示就是,在训练过程中,线会一直顺时针或着逆时针旋转,而不会收敛到最佳值。

上图中,两个坐标轴表示一个简单的线性单元中两个权可能的取值,而圆圈大小代表训练误差E值的大小。
为了确定一个使E最小化的权向量,梯度下降搜索从一个任意的初始向量开始,然后以很小的步伐反复修改这个向量。每一步都沿误差曲线产生最陡峭的下降方向修改权向量(见蓝线),继续这个过程直到得到全局的最小误差点。
这个最陡峭的下降方向是什么呢?
可以通过计算E相对向量w的的每个分量的导数来得到这个方向。这个向量导数被称为E对于W的梯度(gradient),记作ΔE(w).

ΔE(w)本身是一个向量,它的成员是E对每个wi的偏导数。当梯度被解释为权空间的一个向量时,它确定了使E最陡峭上升的方向。
既然确定了方向,那梯度下降法则就是:
![]()
其中:

这里的η是一个正的常数叫做学习速率,它决定梯度下降搜索中的步长。公式中的符号是想让权向量E下降的方向移动。
这个训练法则也可以写成它的分量形式:

其中:
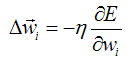 (公式1)
(公式1)
最陡峭的下降可以按照比例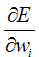 改变
改变 中的每一分量
中的每一分量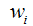 来实现。
来实现。
可以通过前面的训练误差公式中计算E的微分,从而得到组成这个梯度向量的分量 。
。
推导过程略去。
最后得到:
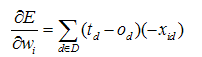
其中xid表示训练样例d的一个输入分量xi。现在我们有了一个公式,能够用线性单元的输入xid,输出od以及训练样例的目标值td表示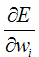 。
。
把次此公式带入公式(1)得到了梯度下降权值更新法则。
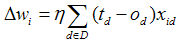 (公式2)
(公式2)
因此,训练线性单元的梯度下降算法如下:选取一个初始的随机权向量;应用线性单元到所有的训练样例,然后根据公式2计算每个权值的Δwi;通过加上Δwi来更新每个权值,然后重复这个过程。
因为这个误差曲面仅包含一个全局的最小值,所以无论训练样例是否线性可分,这个算法都会收敛到具有最小误差的权向量。条件是必须使用一个足够小的学习速率η。
如果η太大,梯度下降搜素就有越过误差面最小值而不是停留在那一点的危险。因此常有的改进方法是随着梯度下降步数的增加逐渐减小η的值。
梯度下降算法的伪代码:

要实现梯度下降的随机近似,删除(T4.2),并把(T4.1)替换为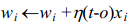 。
。
随机梯度下降算法
梯度下降是一种重要的通用学习范型。它是搜索庞大假设空间或无限假设空间的一种策略,它可以满足以下条件的任何情况:
(1)假设空间包含连续参数化的假设。
(2)误差对于这些假设参数可微。
在应用梯度下降的主要实践问题是:
(1)有时收敛过程可能非常慢;
(2)如果在误差曲面上有多个局部极小值,那么不能保证这个过程会找到全局最小值。
缓解这些困难的一个常见的梯度下降变体被称为增量梯度下降算法(incremental gradient descent)或者随机梯度下降(stochastic gradient descent)。
鉴于公式2给出的梯度下降训练法则在对D中的所有训练样例求和后计算权值更新,随机梯度下降的思想是根据每个单独样例的误差增量计算权值更新,得到近似的梯度下降搜索.
修改后的训练法则与公式2相似,只是在迭代计算每个训练样例时根据下面的公式来更新权值:
 公式3
公式3
其中,t、o和xi分别是目标值、单元输出和第i个训练样例的输入。
随机梯度下降可被看作为每个单独的训练样例d定义不同的误差函数 :
:

其中,td和od是训练样例d的目标输出值和单元输出值。
随机梯度下降迭代计算训练样例集D的每个样例d,在每次迭代过程中按照关于 的梯度来改变权值。在迭代所有训练样例时,这些权值更新的序列给出了对于原来的误差函数
的梯度来改变权值。在迭代所有训练样例时,这些权值更新的序列给出了对于原来的误差函数 的梯度下降的一个合理近似。
的梯度下降的一个合理近似。
标准的梯度下降和随机的梯度下降之间的关键区别:
(1)标准的梯度下降是在权值更新前对所有的样例汇总误差,而随机梯度下降的权值是通过考查每个训练样例来更新的。
(2)在标准的梯度下降中,权值更新的每一步对多个样例求和,这需要大量的计算。
(3)如果![]() 有多个局部极小值,随机的梯度下降有时可能避免陷入这些局部极小值中,因为它使用不同的
有多个局部极小值,随机的梯度下降有时可能避免陷入这些局部极小值中,因为它使用不同的![]() 而不是
而不是![]() 来引导搜索。
来引导搜索。
注意:
公式3的增量法则与之前感知器法则训练法则相似。但是它们是不同的,在增量法则中o是值线性单元的输出![]() ,而对于感知器法则,o是指阈值输出
,而对于感知器法则,o是指阈值输出 ,在公式
,在公式 中。
中。
样例:
输入x1、x2,输出为o,训练w0,w1,w2
满足 w1+x1*w1+x2*x2=o
训练样例为:
x1 x2 o 1 4 19 2 5 26 5 1 19 4 2 20
头文件

#ifndef HEAD_H_INCLUDED #define HEAD_H_INCLUDED #include <iostream> #include <fstream> #include <vector> #include <cstdio> #include <cstdlib> #include <cmath> using namespace std; const int DataRow=4; const int DataColumn=3; const double learning_rate=.01; extern double DataTable[DataRow][DataColumn]; extern double Theta[DataColumn-1]; const double loss_theta=0.001; const int iterator_n =100; #endif // HEAD_H_INCLUDED
源代码
#include "head.h" double DataTable[DataRow][DataColumn]; double Theta[DataColumn-1]; void Init() { ifstream fin("data.txt"); for(int i=0;i<DataRow;i++) { for(int j=0;j<DataColumn;j++) { fin>>DataTable[i][j]; } } if(!fin) { cout<<"fin error"; exit(1); } fin.close(); for(int i=0;i<DataColumn-1;i++) { Theta[i]=0.5; } } void batch_grandient() //标准梯度下降 { double loss=1000; for(int i=0;i<iterator_n&&loss>=loss_theta;i++) { double Thetasum[DataColumn-1]={0}; for(int j=0;j<DataRow;j++) { double error=0; for(int k=0;k<DataColumn-1;k++) { error+=DataTable[j][k]*Theta[k]; } error=DataTable[j][DataColumn-1]-error; for(int k=0;k<DataColumn-1;k++) { Thetasum[k]+=learning_rate*error*DataTable[j][k]; } } double a=0; for(int k=0;k<DataColumn-1;k++) { Theta[k]+=Thetasum[k]; a+=abs(Thetasum[k]); } loss=a/(DataColumn-1); } } void stochastic_gradient() //随即梯度下降 { double loss=1000; for(int i=0;i<iterator_n&&loss>=loss_theta;i++) { double Thetasum[DataColumn-1]={0}; for(int j=0;j<DataRow;j++) { double error=0; for(int k=0;k<DataColumn-1;k++) { error+=DataTable[j][k]*Theta[k]; } error=DataTable[j][DataColumn-1]-error; double a=0; for(int k=0;k<DataColumn-1;k++) { Theta[k]+=learning_rate*error*DataTable[j][k]; a+=abs(learning_rate*error*DataTable[j][k]); } loss=a/(DataColumn-1); if(loss<=loss_theta) break; } } } void printTheta() { for(int i=0;i<DataColumn-1;i++) cout<<Theta[i]<<" "; cout<<endl; } int main() { Init(); //batch_grandient(); stochastic_gradient(); printTheta(); return 0; }