前述
本篇文章写完需要半个小时,阅读需要十分钟,读完后,你将学会在Python中使用NLPIR,以及关于使用它的一些有用的基础知识
NLPIR 是中科院的汉语分词系统,在Python中使用也比较广泛,而且曾多次夺得汉语分词比赛的冠军,并且其可以在多个语言上都实现了接口甚至在Hadoop中也可以使用,博主比较推荐NLPIR
github地址:https://github.com/NLPIR-team/NLPIR
官网地址:http://ictclas.nlpir.org/
NLPIR在Python中的两种实现方式的比较
NLPIR在Python中有两种实现方式
1. pip install pynlpir(即下载,python封装的nlpir类库)
2. 直接在项目中引入NLPIR,使用官方的py文件,直接调用dll文件接口
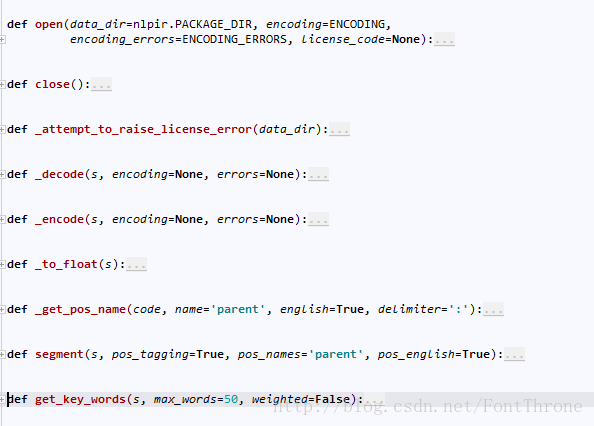
第一种方式的好处在于便于使用?只需要pip install 即可,但是博主不推荐这种方式,因为pynlpir功能太少,根本无法满足我们的使用要求,而且与其安装pynlpir还不如直接安装jieba,其源码中实现的接口如下:
在下载了pynlpir之后,我就开始上手使用,然而…它似乎没有实现用户添加词典的功能,除非去包里面直接把词典换了,这样一来,假如我们又遇到了”路明非”的问题,就是错分新词”路明非”为两个词”路明”,”明非”,原文例子请点击http://blog.csdn.net/fontthrone/article/details/72782499,在NLPIR没有识别其为新词的情况下,那么我们根本无法通过pynlpir本身解决,虽然可以利用from pynlpir import nlpir来实现在pynlpir中引用nlpir但是该版本的nlpir仍然是阉割版本的nlpir,比如用户无法直接修改nlpir词库,而在每次程序运行时手动执行import userdict,这就意味这程序本身的性能被大打折扣.
而相对之下,原版的NLPIR虽然配置略显麻烦,但是无论更全面,因此在需要更强大的功能时,博主推荐使用NLPIR,而他们的功能我将会在下面的部分说明.
Python 类库 pynlpir
1.安装
无论py2/3,只需pip install pynlpir即可
2. demo code
# - * - coding: utf - 8 -*-
#
# 作者:田丰(FontTian)
# 创建时间:'2017/5/24'
# 邮箱:fonttian@163.com
# CSDN:http://blog.csdn.net/fontthrone
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import pynlpir
# from pynlpir import nlpir
# 可以引用和原nlpir中差不多的py文件
pynlpir.open()
s = '欢迎科研人员、技术工程师、企事业单位与个人参与NLPIR平台的建设工作。'
str = s.encode('utf-8')
print str
wordslist1 = pynlpir.segment(str)
wordslist2 = pynlpir.get_key_words(str)
wordslist3 = pynlpir._get_pos_name(str)
# 下面的代码是在pynlpir中添加用户自定义词语
# pynlpir.AddUserWord('路明非')
print wordslist1
for item in wordslist1:
print item[0]
print item[1]
for item in wordslist2:
print item
(1)即使是在python2中设定了文件的默认格式为utf-8但是因为在windows中控制台的中文默认编码格式为gbk,所以控制台的窗口依然会显示乱码,但是请放心,通过
import sys
reload(sys)
sys.setdefaultencoding('utf8')
其实str的默认编码格式已经成了utf-8.
(2)为了在控制台查看demo中的分词,可以使用迭代器循环输出,同时也因为编码格式确实是utf-8,所以这是即使不再使用encode(‘utf-8’),但是控制台仍然不会乱码.
下面是wordslist2中的分词

效果良好
在Python中使用NLPIR的接口
在博主在Python中使用NLPIR的时候参考了这篇文章:Python调用中科院NLPIR(ICTCLAS2015)详解,但是只是部分借鉴,博主使用的是2016,其实使用NLPIR非常简单,只要自己看看官方的文档就可以很好的使用,不过官方文档是真的乱.而且是分散的.
1.根据博主之前参考的博客,似乎想要使用NLPIR,首先要在电脑上搭建swig
下面是一段引用,github下载地址swig官网下载地址
友情提示:如果是swig问题,自己处理。首先下载swig,swig可以帮助我们将C或者C++编写的DLL或者SO文件绑定到包括Python在内的多种语言。Windows下将安装包下载到一定目录下将该目录加入环境变量的path中即可使用swig(当然也可以输入完整的路径来使用swig)。可以打开命令行窗口,在里面输入swig,如果出现“Must specify an input file. Use -help for available options.”则表示一切顺利。
2.下载NLPIR
官网下载页面:NLPIR的官网下载页面
3.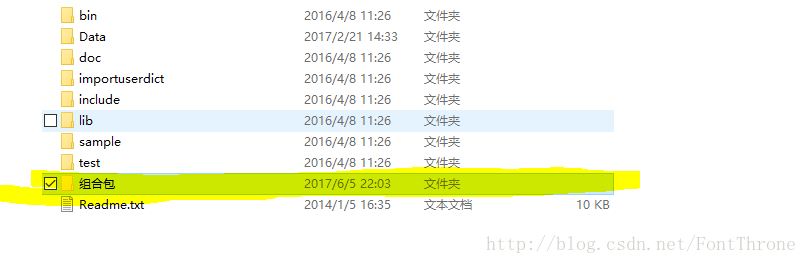
(1)在下载文件之后,解压文件,然后新建文件夹”组合包”,其它名称亦可
(2)组合包内成员包括:
1. 汉语分词20140928samplepythonsample下所有文件
2. Data文件夹,直接复制拖入即可
3. 新建文件夹”bin”下为”importuserdict”中的zip文件解压后文件,注意此处为NLPIR的自带词典,如果你想添加自己的词典,你可以阅读此文件下的REAME.txt,来添加自己的词库
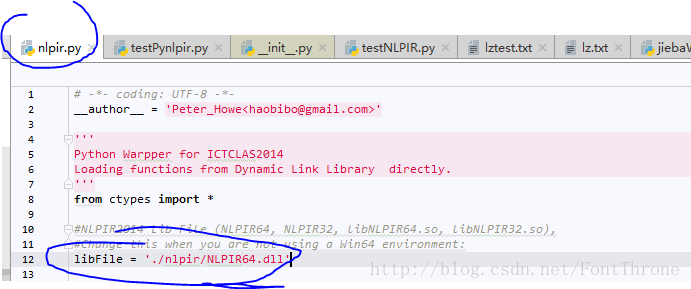
4. 根据机器的位数(64/32)修改配置文件
5. 证书问题:当你一次在Python中调用NLPIR时会报:Initialization failed!
放心第一次运行出现这个错误这一般是正常的你只要去现在最新的授权证书就可以了.
具体请参考我之前的文章:http://blog.csdn.net/fontthrone/article/details/72692691
6. 注意默认的nlpir的默认Python接口为Python2.如果你想在python3中使用nlpir你可以参考官方文档,同时这篇文章中也对python接口的其他问题进行了说明:
https://github.com/haobibo/ICTCLAS_Python_Wrapper
7.在Python2.7中使用NLPIR2016
(1)直接将刚才做好的文件夹中的所有文件拖入你的项目即可使用:
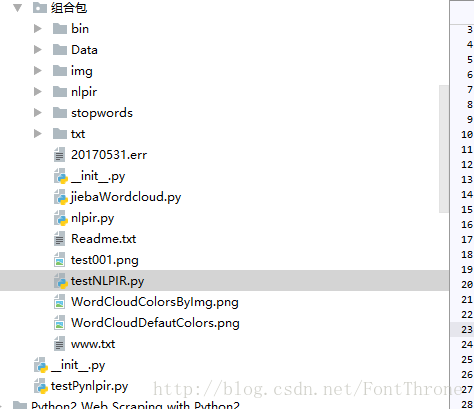
(2)然后按照普通的引用Python文件来使用nlpir即可:
(3)具体可引用的方法直接查询官方给的nlpir文件即可
在测试之后,确实直接引用官方接口,功能确实强了很多
最后附上一个简单的测试代码,我将会在下一篇文章详细介绍nlpir2016Python接口使用(最近有点忙,可能在这个周周末才能更新,故而附上小生qq:2404846224,有兴趣一起学习的小伙伴,请备注来自csdn博客)
# - * - coding: utf - 8 -*-
#
# 作者:田丰(FontTian)
# 创建时间:'2017/5/31'
# 邮箱:fonttian@163.com
# CSDN:http://blog.csdn.net/fontthrone
from os import path
from nlpir import *
from scipy.misc import imread
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
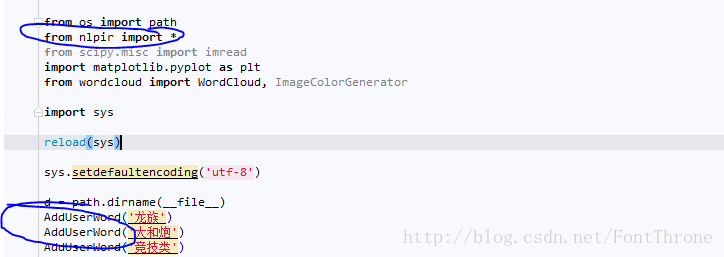
d = path.dirname(__file__)
AddUserWord('龙族')
AddUserWord('大和炮')
AddUserWord('竞技类')
# Init()
# SaveTheUsrDic('路明非')
text_path = 'txt/lztest.txt' #设置要分析的文本路径
stopwords_path = 'stopwordsstopwords1893.txt' # 停用词词表
text = open(path.join(d, text_path)).read()
txt = seg(text)
seg_list =[]
for t in txt:
seg_list.append(t[0].encode('utf-8'))
seg_list += ' '
# 使用NLPIR进行中文分词
print seg_list
# 去除停用词
def jiebaclearText(text):
mywordlist = []
liststr = "/ ".join(seg_list)
f_stop = open(stopwords_path)
try:
f_stop_text = f_stop.read()
f_stop_text = unicode(f_stop_text, 'utf-8')
finally:
f_stop.close()
f_stop_seg_list = f_stop_text.split('
')
for myword in liststr.split('/'):
if not (myword.strip() in f_stop_seg_list) and len(myword.strip()) > 1:
mywordlist.append(myword)
return ''.join(mywordlist)
# 去除完停用词的文本
s = jiebaclearText(seg_list)
print s