前言
介绍java的常用集合+各个集合使用用例
欢迎转载,请注明作者和出处哦☺参考:
1,《Java核心编程技术(第二版)》
2, http://www.cnblogs.com/LittleHann/p/3690187.html
java 集合基本概念
在《Java核心编程技术(第二版)》中是这样介绍java集合的:
java中的集合框架提供了一套设计优良的接口和类,使程序员操作成批的数据或对象元素极为方便。这些接口和类有很多对抽象数据类型操作的API,这是我们常用的且在数据结构中熟知的,例如:Maps,Sets,Lists,Arrays等,并且Java用面向对象的设计对这些数据结构和算法进行了封装,这极大地减轻了程序员编程时的负担。程序员也可以以这个集合框架为基础,定义更高级别的数据抽象,比如栈,队列和线程安全的集合等,从而满足自己的需要。
在日常编程中,经常需要对多个数据进行存储。从传统意义上讲,数组是一个很好的选择,但是一个数组经常需要指定好长度,且这个长度是不可变得。这时我们需要一个可以动态增长的“数组”,而java的集合类就是一个很好的设计方案。
java的集合框架可以简化为如下图所示(本图来自于《Java核心编程技术(第二版)》):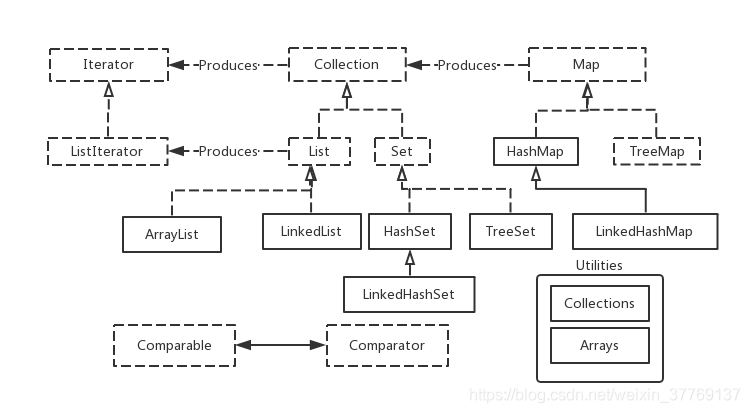
再细化后变为:
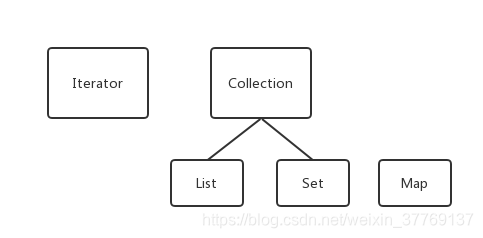
从上图中,我们可以看出java集合框架主要提供三种类型的集合(Set,List,Map)和一个迭代器。
Set 集合
- Set集合中的对象无排列顺序,且没有重复的对象。可以把Set集合理解为一个口袋,往里面丢的对象是无顺序的。
- 对Set集合中成员的访问和操作是通过对集合中对象的引用进行的,所以Set集合不能有重复对象(包括Set的实现类)。
- Set判断集合中两个对象相同不是使用"=="运算符,而是根据equals方法。每次加入一个新对象时,如果这个新对象和当前Set中已有对象进行equals方法比较都返回false时,则允许添加对象,否则不允许。
Set集合的主要实现类:
- HashSet:按照哈希算法来存储集合中的对象,速度较快。
- LinkedHashSet:不仅实现了哈希算法,还实现了链表的数据结构,提供了插入和删除的功能。当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素。
- TreeSet:实现了SortedSet接口(此接口主要用于排序操作,即实现此接口的子类都属于排序的子类)。
- EnumSet:专门为枚举类设计的有序集合类,EnumSet中所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式、或隐式地指定。
Set 集合应用场景
hashSet场景:
public class MyCollectionsDemo {
public static void main(String[] args)
{
HashSet books = new HashSet();
//分别向books集合中添加两个A对象,两个B对象,两个C对象
books.add(new A());
books.add(new A());
books.add(new B());
books.add(new B());
books.add(new C());
books.add(new C());
System.out.println(books);
}
}
//类A的equals方法总是返回true,但没有重写其hashCode()方法。不能保证当前对象是HashSet中的唯一对象
class A {
@Override
public boolean equals(Object obj) {
return true;
}
}
//类B的hashCode()方法总是返回1,但没有重写其equals()方法。不能保证当前对象是HashSet中的唯一对象
class B {
@Override
public int hashCode() {
return 1;
}
}
//类C的hashCode()方法总是返回2,且有重写其equals()方法
class C
{
public int hashCode()
{
return 2;
}
public boolean equals(Object obj)
{
return true;
}
}
输出结果:
[B@1, B@1, A@1b28cdfa, C@2, A@65ab7765]
可以看到,当两个对象equals()方法比较返回true时(即两个对象的equals相同),但hashCode()方法返回不同的hashCode值时,对象可以添加成功(集合中有两个A对象)。如果两个对象的hashCode相同,但是它们的equlas返回值不同,HashSet会在这个位置用链式结构来保存多个对象(B@1, B@1)。而HashSet访问集合元素时也是根据元素的HashCode值来快速定位的。
可以看出,HashSet集合通过hashCode()采用hash算法来决定元素的存储位置,如上输出的(B,B)和(A,A),但是这并不符合Set集合没有重复的对象的规则,所以如果需要把某个类的对象保存到HashSet集合时,在重写这个类的equlas()方法和hashCode()方法时,应该尽量保证两个对象通过equals()方法比较返回true时,它们的hashCode()方法返回值也相等。
LinkedHashSet场景:
public class MyCollectionsDemo {
public static void main(String[] args)
{
HashSet hashSet = new HashSet();
hashSet.add("hello");
hashSet.add("world");
hashSet.add("hashSet");
//输出:[world, hashSet, hello]
System.out.println(hashSet);
LinkedHashSet linkedHashSet = new LinkedHashSet();
linkedHashSet.add("Hello");
linkedHashSet.add("World");
linkedHashSet.add("linkedHashSet");
//输出:[Hello, World, linkedHashSet]
System.out.println(linkedHashSet);
//删除 Hello
linkedHashSet.remove("Hello");
//重新添加 Hello
linkedHashSet.add("Hello");
//输出:[World, linkedHashSet, Hello]
System.out.println(linkedHashSet);
//再次添加 Hello
linkedHashSet.add("Hello");
//输出:[World, linkedHashSet, Hello]
System.out.println(linkedHashSet);
}
}
可以看出,linkedHashSet最大的特点就是有排序(以元素添加的顺序)。同时,linkedHashSet作为HashSet的子类且实现了Set接口,所以不允许集合元素重复。
TreeSet场景:
public class MyCollectionsDemo {
public static void main(String[] args)
{
TreeSet treeSet = new TreeSet();
//添加四个Integer对象
treeSet.add(9);
treeSet.add(6);
treeSet.add(-4);
treeSet.add(3);
//输出:[-4, 3, 6, 9](集合元素自动排序)
System.out.println(treeSet);
//输出:-4
System.out.println(treeSet.first()); //输出集合里的第一个元素
//输出:9
System.out.println(treeSet.last()); //输出集合里的最后一个元素
//输出:[-4, 3]
System.out.println(treeSet.headSet(6)); //返回小于6的子集,不包含6
//输出:[3, 6, 9]
System.out.println(treeSet.tailSet(3)); //返回大于3的子集,包含3
//输出:[-4, 3]
System.out.println(treeSet.subSet(-4 , 6)); //返回大于等于-4,小于6的子集
}
}
可以看出TreeSet会自动排序好存入的数据。TreeSet采用红黑树的数据结构来存储集合元素,支持两种排序方式: 自然排序、定制排序。
- 自然排序:调用集合元素的compareTo(Object obj)方法来比较元素之间的大小关系,然后将集合元素按升序排序。如果试图把一个对象添加到TreeSet时,则该对象的类必须实现Comparable接口,否则程序会抛出异常。
- 定制排序:TreeSet的自然排序是根据集合元素的大小,TreeSet将它们以升序排序。如果我们需要实现定制排序,则可以通过Comparator接口里的int compare(T o1, T o2)方法,该方法用于比较大小。
如下为定制排序实例:
public class MyCollectionsDemo {
public static void main(String[] args)
{
TreeSet treeSet = new TreeSet(new Comparator()
{
//根据M对象的age属性来决定大小
public int compare(Object o1, Object o2)
{
M m1 = (M)o1;
M m2 = (M)o2;
return m1.age > m2.age ? -1
: m1.age < m2.age ? 1 : 0;
}
});
treeSet.add(new M(5));
treeSet.add(new M(-3));
treeSet.add(new M(9));
System.out.println(treeSet);
}
}
class M
{
int age;
public M(int age)
{
this.age = age;
}
public String toString()
{
return "M[age:" + age + "]";
}
}
TreeSet总结
- 当把一个对象加入TreeSet集合时,TreeSet会调用该对象的compareTo(Object obj)方法与容器中的其他对象比较大小,然后根据红黑树结构找到它的存储位置(如果两个对象通过compareTo(Object obj)方法比较相等,则添加失败)。
- 自然排序、定制排序、Comparator决定的是谁大的问题,即按什么顺序(升序、降序)进行排序。
EnumSet场景:
enum SeasonEnum
{
SPRING,SUMMER,FALL,WINTER
}
public class MyCollectionsDemo {
public static void main(String[] args)
{
//allOf:集合中的元素就是SeasonEnum枚举类的全部枚举值
EnumSet es1 = EnumSet.allOf(SeasonEnum.class);
//输出:[SPRING,SUMMER,FALL,WINTER]
System.out.println(es1);
//noneOf:指定SeasonEnum类的枚举值。
EnumSet es2 = EnumSet.noneOf(SeasonEnum.class);
//输出:[]
System.out.println(es2);
//手动添加两个元素
es2.add(SeasonEnum.WINTER);
es2.add(SeasonEnum.SPRING);
//输出:[SPRING,WINTER](EnumSet会自动排序)
System.out.println(es2);
//of:指定枚举值
EnumSet es3 = EnumSet.of(SeasonEnum.SUMMER , SeasonEnum.WINTER);
//输出:[SUMMER,WINTER]
System.out.println(es3);
}
}
Set 集合总结
- HashSet的性能比TreeSet好(包括添加、查询元素等操作),因为TreeSet需要额外的红黑树算法来维护集合元素的次序。
当需要一个始终保持排序的Set时,才使用TreeSet,否则使用HashSet。 - 对于LinkedHashSet,普通的插入、删除操作比HashSet要略慢一点,因为维护链表会带来的一定的开销。好处是,遍历比HashSet会更快
- EnumSet是所有Set实现类中性能最好的。
- HashSet、TreeSet、EnumSet都是"线程不安全"的,可以通过Collections工具类的synchronizedSortedSet方法来"包装"该Set集合。
SortedSet s = Collections.synchronizedSortedSet(new TreeSet(...));
List 集合
- 集合中的对象按照索引的顺序排序,可以有重复的对象。List与数组相似。
- List以线型方式存储,默认按元素的添加顺序设置元素的索引。
List集合的主要实现类:
- ArrayList:可以理解为长度可变的数组。可以对集合中的元素快速随机访问,但是做插入或删除操作时效率较低。
- LinkedList:使用链表的数据接口。与ArrayList相反,插入或删除操作时速度快,但是随机访问速度慢。同时实现List接口和Deque接口,能对它进行队列操作,即可以根据索引来随机访问集合中的元素,也能将LinkedList当作双端队列使用,自然也可以被当作"栈来使用(可以实现“fifo先进先出,filo后入先出”)
List 集合应用场景
ArrayList场景:
public class MyCollectionsDemo {
public static void main(String[] args)
{
List list = new ArrayList();
//添加三个元素
list.add(new String("list第一个元素"));
list.add(new String("list第二个元素"));
list.add(new String("list第三个元素"));
//输出:[list第一个元素, list第二个元素, list第三个元素]
System.out.println(list);
//在list第二个位置插入新元素
list.add(1 , new String("在list第二个位置插入的元素"));
for (int i = 0 ; i < list.size() ; i++ )
{
/**
* 输出:
* list第一个元素
* 在list第二个位置插入的元素
* list第二个元素
* list第三个元素
*/
System.out.println(list.get(i));
}
//删除第三个元素
list.remove(2);
//输出:[list第一个元素, 在list第二个位置插入的元素, list第三个元素]
System.out.println(list);
//判断指定元素在List集合中位置:输出1,表明位于第二位
System.out.println(list.indexOf(new String("在list第二个位置插入的元素")));
//将第二个元素替换成新的字符串对象
list.set(1, new String("第二个元素替换成新的字符串对象"));
//输出:[list第一个元素, 第二个元素替换成新的字符串对象, list第三个元素]
System.out.println(list);
//将list集合的第二个元素(包括)~到第三个元素(不包括)截取成子集合
//输出:[第二个元素替换成新的字符串对象]
System.out.println(list.subList(1 , 2));
}
}
LinkedList场景:
public class MyCollectionsDemo {
public static void main(String[] args)
{
LinkedList linkedList = new LinkedList();
//将字符串元素加入队列的尾部(双端队列)
linkedList.offer("队列的尾部");
//将一个字符串元素加入栈的顶部(双端队列)
linkedList.push("栈的顶部");
//将字符串元素添加到队列的头(相当于栈的顶部)
linkedList.offerFirst("队列的头");
for (int i = 0; i < linkedList.size() ; i++ )
{
/**
* 输出:
* 队列的头
* 栈的顶部
* 队列的尾部
*/
System.out.println(linkedList.get(i));
}
//访问、并不删除栈顶的元素
//输出:队列的头
System.out.println(linkedList.peekFirst());
//访问、并不删除队列的最后一个元素
//输出:队列的尾部
System.out.println(linkedList.peekLast());
System.out.println("end");
//将栈顶的元素弹出"栈"
//输出:队列的头
System.out.println(linkedList.pop());
//下面输出将看到队列中第一个元素被删除
//输出:[栈的顶部, 队列的尾部]
System.out.println(linkedList);
//访问、并删除队列的最后一个元素
//输出:队列的尾部
System.out.println(linkedList.pollLast());
//下面输出将看到队列中只剩下中间一个元素:
//输出:[栈的顶部]
System.out.println(linkedList);
}
}
Map 集合
- Map是一种把键对象(key)和值对象(value)进行映射的集合(k-v)。k相当于v的索引,v仍然可以是Map类型(k-v)。
- key和value都可以是任何引用类型的数据。
- Map的key不允许重复,即同一个Map对象的任何两个key通过equals方法比较结果总是返回false。
- key集的存储形式和Set集合完全相同(即key不能重复)
- value集的存储形式和List非常类似(即value可以重复、根据索引来查找)
Map集合的主要实现类:
- HashMap:按照哈希算法来存取key,有很好的存取性能,和HashSet一样,要求覆盖equals()方法和hasCode()方法,同时也不能保证集合中每个key-value对的顺序。
- LinkedHashMap:使用双向链表来维护key-value对的次序,该链表负责维护Map的迭代顺序,与key-value对的插入顺序一致。
- TreeMap:一个红黑树数据结构,每个key-value对即作为红黑树的一个节点。实现了SortedMap接口,能对key进行排序。TreeMap可以保证所有的key-value对处于有序状态。同样,TreeMap也有两种排序方式(自然排序、定制排序)
Map 集合应用场景
Hashtable场景:
public class MyCollectionsDemo {
public static void main(String[] args)
{
Hashtable hashtable = new Hashtable();
hashtable.put(new A(10086) , "hashtable10086");
hashtable.put(new A(10010) , "hashtable10010");
hashtable.put(new A(10011) , new B());
//输出:{A@2766=hashtable10086, A@271b=B@65ab7765, A@271a=hashtable10010}
System.out.println(hashtable);
//只要两个对象通过equals比较返回true,Hashtable就认为它们是相等的value。
//由于Hashtable中有一个B对象,
//它与任何对象通过equals比较都相等,所以下面输出true。
System.out.println(hashtable.containsValue("测试字符串"));
//只要两个A对象的count相等,它们通过equals比较返回true,且hashCode相等
//Hashtable即认为它们是相同的key,所以下面输出true。
System.out.println(hashtable.containsKey(new A(10086)));
//删除最后一个key-value对
hashtable.remove(new A(10011));
//通过返回Hashtable的所有key组成的Set集合,
//从而遍历Hashtable每个key-value对
for (Object key : hashtable.keySet())
{
/**
* 输出:
* A@2766---->hashtable10086
* A@271a---->hashtable10010
*/
System.out.print(key + "---->");
System.out.print(hashtable.get(key) + "
");
}
}
}
class A
{
int count;
public A(int count)
{
this.count = count;
}
//根据count的值来判断两个对象是否相等。
public boolean equals(Object obj)
{
if (obj == this)
return true;
if (obj!=null && obj.getClass()==A.class)
{
A a = (A)obj;
return this.count == a.count;
}
return false;
}
//根据count来计算hashCode值。
public int hashCode()
{
return this.count;
}
}
class B
{
//重写equals()方法,B对象与任何对象通过equals()方法比较都相等
public boolean equals(Object obj)
{
return true;
}
}
当使用自定义类作为HashMap、Hashtable的key时,如果重写该类的equals(Object obj)和hashCode()方法,则应保证两个方法的判断标准一致(当两个key通过equals()方法比较返回true时,两个key的hashCode()的返回值也应该相同)
LinkedHashMap场景:
public class MyCollectionsDemo {
public static void main(String[] args)
{
LinkedHashMap scores = new LinkedHashMap();
scores.put("语文" , 80);
scores.put("英文" , 82);
scores.put("数学" , 76);
//遍历scores里的所有的key-value对
for (Object key : scores.keySet())
{
/**
* 输出:
* 语文------>80
* 英文------>82
* 数学------>76
*/
System.out.println(key + "------>" + scores.get(key));
}
}
}
LinkedHashMap中的集合排序与插入的顺序保持一致
TreeMap场景:
class R implements Comparable
{
int count;
public R(int count)
{
this.count = count;
}
public String toString()
{
return "R[count:" + count + "]";
}
//根据count来判断两个对象是否相等。
public boolean equals(Object obj)
{
if (this == obj)
return true;
if (obj!=null
&& obj.getClass()==R.class)
{
R r = (R)obj;
return r.count == this.count;
}
return false;
}
//根据count属性值来判断两个对象的大小。
public int compareTo(Object obj)
{
R r = (R)obj;
return count > r.count ? 1 :
count < r.count ? -1 : 0;
}
}
public class MyCollectionsDemo {
public static void main(String[] args)
{
TreeMap treeMap = new TreeMap();
treeMap.put(new R(10010) , "treemap10010");
treeMap.put(new R(-4396) , "treemap-4396");
treeMap.put(new R(10086) , "treemap10086");
//treeMap自动排序
//输出:{R[count:-4396]=treemap-4396, R[count:10010]=treemap10010, R[count:10086]=treemap10086}
System.out.println(treeMap);
//返回该TreeMap的第一个Entry对象
//输出:R[count:-4396]=treemap-4396
System.out.println(treeMap.firstEntry());
//返回该TreeMap的最后一个key值
//输出:R[count:10086]
System.out.println(treeMap.lastKey());
//返回该TreeMap的比new R(2)大的最小key值。
//输出:R[count:10010]
System.out.println(treeMap.higherKey(new R(2)));
//返回该TreeMap的比new R(2)小的最大的key-value对。
////输出:R[count:-4396]=treemap-4396
System.out.println(treeMap.lowerEntry(new R(2)));
//返回该TreeMap的子TreeMap
////输出:{R[count:-4396]=treemap-4396, R[count:10010]=treemap10010}
System.out.println(treeMap.subMap(new R(-5000) , new R(10086)));
}
}
Map 集合总结
- Set和Map的关系十分密切,java源码就是先实现了HashMap、TreeMap等集合,然后通过包装一个所有的value都为null的Map集合实现了Set集合类。
- HashMap和Hashtable的效率大致相同,因为它们的实现机制几乎完全一样。但HashMap通常比Hashtable要快一点,因为Hashtable需要额外的线程同步控制
- TreeMap通常比HashMap、Hashtable要慢(尤其是在插入、删除key-value对时更慢),因为TreeMap底层采用红黑树来管理key-value对
- 使用TreeMap的一个好处就是: TreeMap中的key-value对总是处于有序状态,无须专门进行排序操作
结束
欢迎对本文持有不同意见的人在评论中留言,大家一起互相讨论,学习进步。
最后祝大家生活愉快,大吉大利!
如果我的文章对您有帮助的话,欢迎给我打赏,生活不易,工作艰苦,您的打赏是是对我最大的支持!
打赏6元,祝您合家幸福,生活安康。
打赏7元,祝您事业有成,实现梦想。
打赏8元,祝您财源滚滚,一生富贵。
。。。
听说,打赏我的人最后都找到了真爱并进了福布斯排行榜。

- 本文标题:java集合介绍
- 文章作者:我不是陈浩南(Fooss)
- 发布时间:2018-12-26 22:09 星期三
- 最后更新:2018-12-26 22:09 星期三