作业需求:
1.基于Spider或者CrawlSpider进行租房信息的爬取 2.本机搭建分布式环境对租房信息进行爬取 3.搭建多台机器的分布式环境,多台机器同时进行租房数据爬取 建议:用Pycharm开发
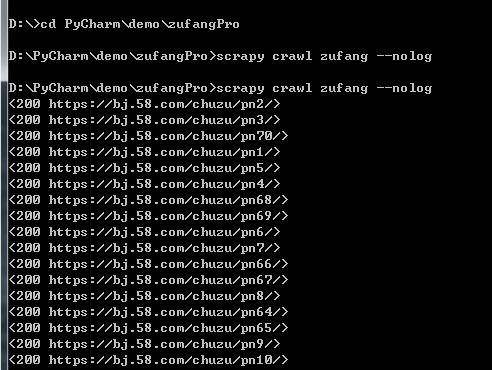
爬取北京全站租房信息
爬取全站用基于crawlspider建立爬虫文件
对北京出租下的70页信息进行爬取:
https://bj.58.com/chuzu/

-------------------------------------------
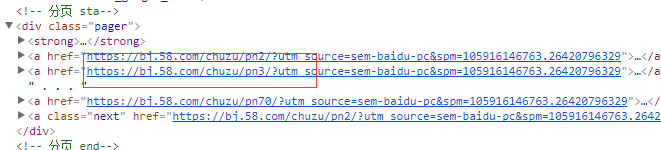
分析页码网页

https://bj.58.com/chuzu/pn2 bj代表北京

包括四种类型的房源:个人房源;经纪人;安选房源;品牌公寓
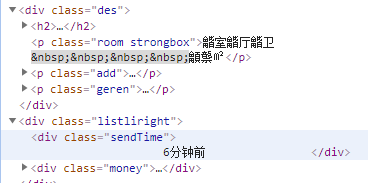
个人房源:

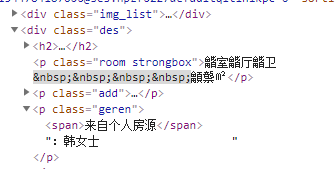
经纪人:

安选房源:
品牌公寓:不同

详情页面
class ZufangSpider(CrawlSpider): name = 'zufang' #allowed_domains = ['https://www.bj.58.com'] start_urls = ['https://bj.58.com/chuzu/pn1'] #('https://bj.58.com/chuzu/pn2/') rules = ( Rule(LinkExtractor(allow=r'https://bj.58.com/chuzu/pnd+'), callback='parse_item', follow=True), ) def parse_item(self, response): print(response)