1、python的特点

2、python常见函数
print(*objects, sep=' ', end='
', file=sys.stdout, flush=False)
objects -- 复数,表示可以一次输出多个对象。输出多个对象时,需要用 , 分隔。
sep -- 用来间隔多个对象,默认值是一个空格。
end -- 用来设定以什么结尾。默认值是换行符
,我们可以换成其他字符串。
file -- 要写入的文件对象。
flush -- 输出是否被缓存通常决定于 file,但如果 flush 关键字参数为 True,流会被强制刷新。
>>> print("www","runoob","com",sep=".")
# 设置间隔符 www.runoob.com
3、python变量
Python 定义了一些标准类型,用于存储各种类型的数据。
Python有五个标准的数据类型:
Numbers(数字)
String(字符串)
List(列表)
Tuple(元组)
Dictionary(字典)
4、python数据结构
基本数据类型包括:数值(整型、浮点型、复数等) 字符串 布尔(bool) 和 none
复合数据类型包括:列表 元组 字典 和集合
根据数据是否可变,数据类型又可以分为:可变类型和不可变类型,
可变类型包括:列表、集合、字典,上述其他的都属于不可变类型。

➣可变数据类型分析 >>> a = [1, 2, 3] >>> id(a) 41568816 >>> a = [1, 2, 3] >>> id(a) 41575088 >>> a.append(4) >>> id(a) 41575088 >>> a += [2] >>> id(a) 41575088 >>> a [1, 2, 3, 4, 2] --------------------------------------- >>> a=10 >>> b=a >>> print(a is b) True >>> a=22 >>> b=22 >>> print(a is b) True
Python的数据缓存机制探究
5、is和==区别
Python中对象包含的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)。
== 比较对象的值是否相等
is 比较两个对象的id是否相等
数据类型整理 字符串、列表、字典、集合
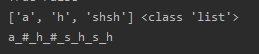
b='a#h#shsh' print(b.split('#'),type(b.split(' '))) print('_'.join(b))
字符串在格式化
print('a=%s,b=%s'%(1,2)) print('a={},b={}'.format(1,2)) print(f"字符{b}")
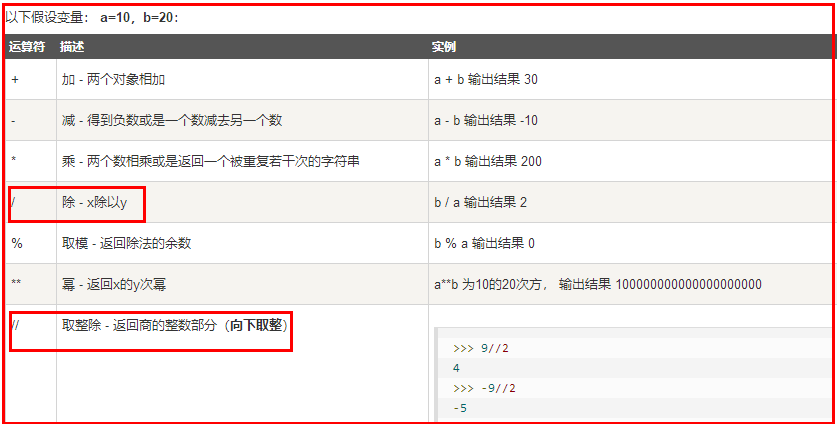
python算术运算符
Python高阶函数(Map、Reduce、Filter)和lambda函数一起使用 ,三剑客
lambda匿名函数
zip函数
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
我们可以使用 list() 转换来输出列表。
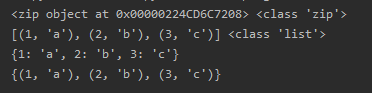
a = [1,2,3] b = ['a','b','c'] zipped = zip(a,b) print(zipped,type(zipped)) print(list(zipped),type(list(zipped))) print(dict(zip(a,b))) print(set(zip(a,b)))
深拷贝和浅拷贝
1,切片可以应用于:列表、元组、字符串,但不能应用于字典。
2,深浅拷贝,既可应用序列(列表、元组、字符串),也可应用字典。
# 浅拷贝和深拷贝 # 浅拷贝 li=[1,2,3,4] li2=li print('li=',li,' ','li2=',li2) li[0]=100 print('li=',li,' ','li2=',li2) print()
# 深拷贝 li3=li.copy() print('li=',li,' ','li3=',li3) li[-1]=120 print('li=',li,' ','li3=',li3)
li= [1, 2, 3, 4] li2= [1, 2, 3, 4]
li= [100, 2, 3, 4] li2= [100, 2, 3, 4]
li= [100, 2, 3, 4] li3= [100, 2, 3, 4]
li= [100, 2, 3, 120] li3= [100, 2, 3, 4]

浅拷贝拷贝一个引用,原值改变,根据引用,跟着改变
深拷贝拷贝在是对象本身
异常值处理语句:
