1 原理
我们做很多事情都离不开原理二字,只有懂得了背后的原理,才能把事情做到极致。本文意在向一个初学者展示如何分析访问一个https网站时的流量,作者也是一只流量分析的入门和初学者,实属菜鸟,有错误之处,敬请指正。从所周知,从在浏览器中输入一个网站的domain并按下回车键后,浏览器需要经历DNS解析->发送request->等待response这样一个过程,中间或许会夹杂一些网站回复的304等重定向和再次发图片request等步骤,但整体流程如此。无论是对HTTP还是对HTTPS网站的流量进行分析,首先都必须截获流量,这类工具有很多,比如常用的就有Wireshark和Fiddler。由于HTTPS网站的流量都是经过非对称加密的,所以若想解密,就得找到浏览器与网站之间协商的加密密钥。就技术而言,破解协商的密钥比较困难,好在HTTPS连接的建立是一个复杂的过程。哲学上讲,越是复杂的东西功能就越强大,但同时也就越脆弱。于是我们就可以采用常见的MITM(Man in the middle,中间人攻击)来破解HTTPS流量了。
2 Fiddler
Fiddler是一个HTTP协议调试代理工具,它能够记录并检查所有与互联网站之间的HTTP通讯。另外,它还在本地建立一个简易的proxy并生成自己的证书系统,采用MITM的方式对HTTPS流量进行解密,这对我们分析Youtube网站的访问流量提供了极大的方便(需要手动打开https解密选项)。
这里简单的介绍一下Fiddler的使用,若想详细了解Fiddler的强大功能,可以自行搜索相关教程。Fiddler的主界面如下:

工欲善其事,必先利其器。这里先对各个功能按键做一个介绍:
-- Stream: 这里设置的是Fiddler的工作模式,Fiddler支持Stream和Buffering两种模式。Stream模式下会实时地将浏览器与网站之间的流量包逐一列出来,直到网站处理完毕。Buffering模式下则会等到网站处理完毕后再把流量包列出来。
-- Decode:顾名思义,对所有的流量包数据进行解码,这里值得一提的是,就就是HTTPS流量也可以成功解码。Fiddler真心强大,而且使用起来方便,都不用自己配置浏览器证书。
-- Browse : 这里选择捕获流量的目标浏览器,可以是Firefox,Chrome等。这对过滤某个浏览器的流量包太有用处了。
-- Inspectors: 将每个流量数据包都解析成request和response.如上图所示,上半部分显示的是浏览器发送的request,下半部分是网站的response.
-- Capturing : 显示Capturing时才会捕捉流量,否则不捕捉。
3 Youtobe首页数据包分析
从google搜索的结果中点击Youtobe的链接将会访问Youtube的首页,捕捉到的流量如下所示:
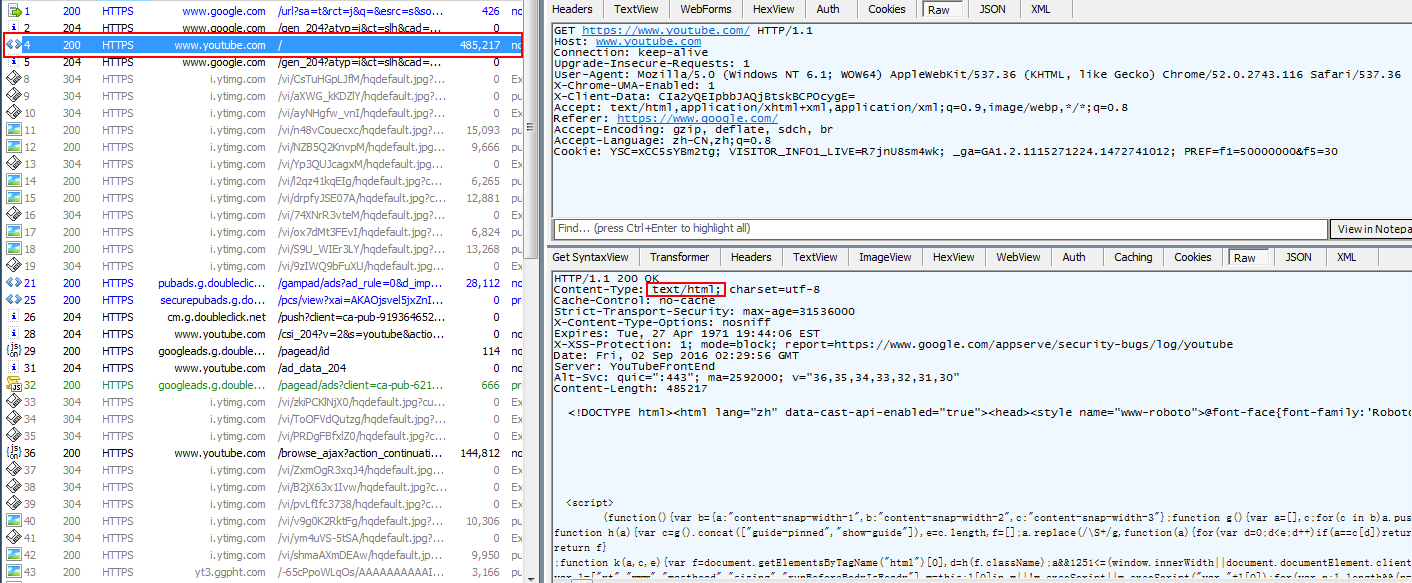
可以在左侧的红色方框内看到访问的host是www.youtube.com,而URL是'/',这表示的是网站的首页。在Inspector标签页可以清晰地看到对应的request和response。
3.1 首页request分析
这里选择 Raw,表示查看request的原始数据,截图如下:

从上图可以看到,除了Raw还有许多其他的标签页。这些标签页并不对request做任何修改,只是把request按照不同的格式需要解析并显示出来。这里对request的每一行进行说明:
-- 第一行 : 说明当前访问的方法为 GET, URL为:https://www.youtube.com/, 使用HTTP的版本是 1.1。
-- Host: 指明接收request的服务器的主机名和端口号,http是80,https是443。
-- Connection: 这里是告诉服务器可以使用的与request/response连接有关的选项。
-- Upgrade-Insecure-Requests: 告诉服务器端自己支持将http升到https并且在以后的发送request中均使用https。
-- User-Agent : 告诉服务端发起request的应用程序名称和一些平台,系统等信息。
-- X-Chrome-UMA-Enabled : 与chrome浏览器有关。
-- X-Client-Data : 与chrome浏览器有关。
-- Accept: 告诉服务端在此request的response中能包含的媒体类型。
-- Referer : 提供包含当前请求URI的文档的URL,这里是从google搜索出来的。
-- Accept-Encoding : 告诉服务端自己支持哪些编码方式。
-- Accept-Language : 告诉服务端自己支持哪些语言。
-- Cookie: 告诉服务端一些关于Session的信息。
分析报文得知,访问Youtube时发送的是GET请求,由于是首页,无需要携带任何参数等信息。
3.2 首页response分析
这里同样选择 Raw,查看response的原始数据,截图如下:

-- 第一行 : 表示response的状态码
-- Content-Type : response中实体的数据类型,这里指明类型为采用utf-8编码的text/html。
-- Cache-Control : 随报文传送用于指示是否缓存。
-- Strict-Transport-Security : 通知浏览器禁止使用HTTP加载数据,而要用HTTPS。后跟的参数指定在接下来的多长时间内保持这一行为。
-- X-Content-Type-Options : 通常浏览器依据response头中的content-type来分辨响应的类型,但是当有些资源的content-type是错误的或者是未定义的时候,有些浏览器就会启用MIME-sniffing来猜测资源的类型,解析内容并执行。这容易被攻击者所利用,于是可以通过这个选项禁用浏览器的猜测行为。值只能为nosniff
-- Expires : response实体的有效期。
-- X-XSS-Protection : 为1时启动XSS攻击(跨站脚本攻击),当用户关闭时可以防止被XSS攻击。
-- Date: response产生的日间戳。
-- Server : 服务端应用程序软件的名称和版本等信息。
-- Alt-Svc :
-- Content-Length : response实体的长度。
到这里,我们已经分析了访问Youtube首页的request和response。大部分内容都是与HTTP协议相关的,而且没有复杂的方法。接下来我们分析下在Youtube中按关键字查找视频时的协议数据包是怎样的。
4 关键字查询分析
触发场景如下:在已经打开的Youtube网页的搜索栏中输入“骑行”二字,然后按下回车键,截图如下:

接下来分析一下这个过程中抓取到的数据包。截取的数据流如下:

先看第一个数据包,让人奇怪的是,在Youtube上输入“骑行”后还没有按下回车键浏览器就发送了一个request到clients.1.google.com。查看一下这次交互的内容就知道它究竟在干什么了。

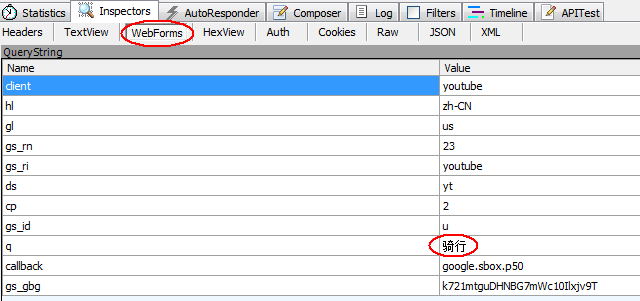
从上2图来看,在输入“骑行”后,浏览器发送一个查询请求到google查询与输入内容相匹配的热度查询关键字组合有哪些并返回。从response来看,返回了6个热度最高的关键字组合,与页面上显示的结果一致。
第二个数据包,仍然是发送google,不过这次发送的请求如下:
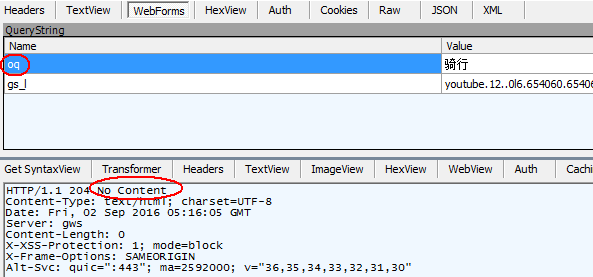
并没有什么内容返回,具体原因不明,估计是刚刚查询过这个关键字,client端已经获取到内容,无需再次搜索查询。
第三个数据包是由Youtube服务的,数据解析如下:

从request可以看出,此时搜索“骑行”的方法为:GET,URL为: https://www.youtube.com/results?search_query=%E9%AA%91%E8%A1%8C&spf=navigate
搜索的关键字信息如下:

response是一个json结构,其中包含每个资源的获取URL。于是从抓的包来看,从第4行开始都是去ytimg.com获取资源的request。解析各个request得到的response,如果是图片资源的话,可以从ImageView中看到网页展示的图片资源。如下:

5 点击视频数据分析
经过了上面操作后,现在页面上已经罗列出了按关键字查询出来的视频列表,随机选一个视频后获取视频的title和description信息。
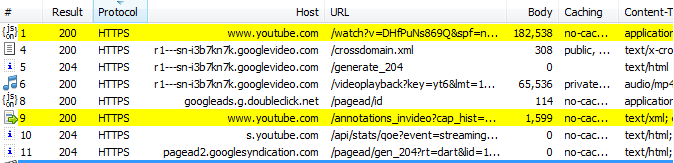
按关键字“骑行26天”搜索所有的response数据包,可以搜索出2个交互里是含有视频title信息。这其中就包含有视频的title和description等信息。
6 总结
这篇文章只是一个网站访问数据解析初学者的总结所得。得力于Fiddler的强大才使得分析起来如此容易。再次验证了那句古话:君子,性非异也,善假于物也!有错误之处,敬请指正。