一.介绍
1.基于libevent的事件处理
libevent是一套跨平台的事件处理接口的封装,能够兼容包括这些操作系统:Windows/Linux/BSD/Solaris 等操作系统的的事件处理。
包装的接口包括:poll、select(Windows)、epoll(Linux)、kqueue(BSD)、/dev/pool(Solaris)
Memcached 使用libevent来进行网络并发连接的处理,能够保持在很大并发情况下,仍旧能够保持快速的响应能力。
libevent: http://www.monkey.org/~provos/libevent/
2.内置内存存储方式
为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重启memcached、重启操作系统会导致全部数据消失。另外,内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。
数据存储方式:Slab Allocation
结构图如下:
Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块(chunk),并把尺寸相同的块分成组,以完全解决内存碎片问题。但由于分配的是特定长度的内存,因此无法有效利用分配的内存。比如将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费了。
Page:分配给Slab的内存空间,默认是1MB。分配给Slab之后根据slab的大小切分成chunk。
Chunk:用于缓存记录的内存空间。
Slab Class:特定大小的chunk的组。
memcached根据收到的数据的大小,选择最适合数据大小的slab。
memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。
数据过期方式:Lazy Expiration + LRU
Lazy Expiration
memcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过
期。这种技术被称为lazy(惰性)expiration。因此,memcached不会在过期监视上耗费CPU时间。
LRU
memcached会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不
足的情况,此时就要使用名为 Least Recently Used(LRU)机制来分配空间。当memcached的内存空间不足时(无法从slab class 获取到新的空间时),就从最近未被使用的记录中搜索,并将其空间分配给新的记录。
http://www.ttlsa.com/memcache/memcached-description/
二.处理流程
1. memcached采用事件驱动+状态驱动的方式来进行整个业务的处理,针对每一个tcp/udp连接,都有对应的状态,状态可能的取值为:
/** * Possible states of a connection. */ enum conn_states { conn_listening, /**< the socket which listens for connections */ conn_new_cmd, /**< Prepare connection for next command */ conn_waiting, /**< waiting for a readable socket */ conn_read, /**< reading in a command line */ conn_parse_cmd, /**< try to parse a command from the input buffer */ conn_write, /**< writing out a simple response */ conn_nread, /**< reading in a fixed number of bytes */ conn_swallow, /**< swallowing unnecessary bytes w/o storing */ conn_closing, /**< closing this connection */ conn_mwrite, /**< writing out many items sequentially */ conn_closed, /**< connection is closed */ conn_max_state /**< Max state value (used for assertion) */ };
2.针对客户端的命令,连接的状态为设置为conn_parse_cmd,这样就可以对客户端的命令进行解析处理,支持的命令如下:
/** * Definition of the different command opcodes. * See section 3.3 Command Opcodes */ typedef enum { PROTOCOL_BINARY_CMD_GET = 0x00, PROTOCOL_BINARY_CMD_SET = 0x01, PROTOCOL_BINARY_CMD_ADD = 0x02, PROTOCOL_BINARY_CMD_REPLACE = 0x03, PROTOCOL_BINARY_CMD_DELETE = 0x04, PROTOCOL_BINARY_CMD_INCREMENT = 0x05, PROTOCOL_BINARY_CMD_DECREMENT = 0x06, PROTOCOL_BINARY_CMD_QUIT = 0x07, PROTOCOL_BINARY_CMD_FLUSH = 0x08, PROTOCOL_BINARY_CMD_GETQ = 0x09, PROTOCOL_BINARY_CMD_NOOP = 0x0a, PROTOCOL_BINARY_CMD_VERSION = 0x0b, PROTOCOL_BINARY_CMD_GETK = 0x0c, PROTOCOL_BINARY_CMD_GETKQ = 0x0d, PROTOCOL_BINARY_CMD_APPEND = 0x0e, PROTOCOL_BINARY_CMD_PREPEND = 0x0f, PROTOCOL_BINARY_CMD_STAT = 0x10, PROTOCOL_BINARY_CMD_SETQ = 0x11, PROTOCOL_BINARY_CMD_ADDQ = 0x12, PROTOCOL_BINARY_CMD_REPLACEQ = 0x13, PROTOCOL_BINARY_CMD_DELETEQ = 0x14, PROTOCOL_BINARY_CMD_INCREMENTQ = 0x15, PROTOCOL_BINARY_CMD_DECREMENTQ = 0x16, PROTOCOL_BINARY_CMD_QUITQ = 0x17, PROTOCOL_BINARY_CMD_FLUSHQ = 0x18, PROTOCOL_BINARY_CMD_APPENDQ = 0x19, PROTOCOL_BINARY_CMD_PREPENDQ = 0x1a, PROTOCOL_BINARY_CMD_TOUCH = 0x1c, PROTOCOL_BINARY_CMD_GAT = 0x1d, PROTOCOL_BINARY_CMD_GATQ = 0x1e, PROTOCOL_BINARY_CMD_GATK = 0x23, PROTOCOL_BINARY_CMD_GATKQ = 0x24, PROTOCOL_BINARY_CMD_SASL_LIST_MECHS = 0x20, PROTOCOL_BINARY_CMD_SASL_AUTH = 0x21, PROTOCOL_BINARY_CMD_SASL_STEP = 0x22, /* These commands are used for range operations and exist within * this header for use in other projects. Range operations are * not expected to be implemented in the memcached server itself. */ PROTOCOL_BINARY_CMD_RGET = 0x30, PROTOCOL_BINARY_CMD_RSET = 0x31, PROTOCOL_BINARY_CMD_RSETQ = 0x32, PROTOCOL_BINARY_CMD_RAPPEND = 0x33, PROTOCOL_BINARY_CMD_RAPPENDQ = 0x34, PROTOCOL_BINARY_CMD_RPREPEND = 0x35, PROTOCOL_BINARY_CMD_RPREPENDQ = 0x36, PROTOCOL_BINARY_CMD_RDELETE = 0x37, PROTOCOL_BINARY_CMD_RDELETEQ = 0x38, PROTOCOL_BINARY_CMD_RINCR = 0x39, PROTOCOL_BINARY_CMD_RINCRQ = 0x3a, PROTOCOL_BINARY_CMD_RDECR = 0x3b, PROTOCOL_BINARY_CMD_RDECRQ = 0x3c /* End Range operations */ } protocol_binary_command;
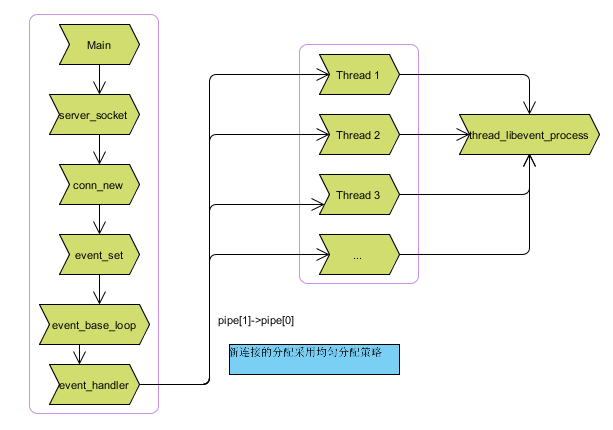
3.memcached处理框架示意图:
三.redis、memcached、mongoDB 对比
1)性能
都比较高,性能对我们来说应该都不是瓶颈
总体来讲,TPS方面redis和memcache差不多,要大于mongodb
2)操作的便利性
memcache数据结构单一
redis丰富一些,数据操作方面,redis更好一些,较少的网络IO次数
mongodb支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富
3)内存空间的大小和数据量的大小
redis在2.0版本后增加了自己的VM特性,突破物理内存的限制;可以对key value设置过期时间(类似memcache)
memcache可以修改最大可用内存,采用LRU算法
mongoDB适合大数据量的存储,依赖操作系统VM做内存管理,吃内存也比较厉害,服务不要和别的服务在一起
4)可用性(单点问题)
对于单点问题,
redis,依赖客户端来实现分布式读写;主从复制时,每次从节点重新连接主节点都要依赖整个快照,无增量复制,因性能和效率问题,
所以单点问题比较复杂;不支持自动sharding,需要依赖程序设定一致hash 机制。
一种替代方案是,不用redis本身的复制机制,采用自己做主动复制(多份存储),或者改成增量复制的方式(需要自己实现),一致性问题和性能的权衡
Memcache本身没有数据冗余机制,也没必要;对于故障预防,采用依赖成熟的hash或者环状的算法,解决单点故障引起的抖动问题。
mongoDB支持master-slave,replicaset(内部采用paxos选举算法,自动故障恢复),auto sharding机制,对客户端屏蔽了故障转移和切分机制。
5)可靠性(持久化)
对于数据持久化和数据恢复:
redis支持(快照、AOF):依赖快照进行持久化,aof增强了可靠性的同时,对性能有所影响
memcache不支持,通常用在做缓存,提升性能;
MongoDB从1.8版本开始采用binlog方式支持持久化的可靠性
6)数据一致性(事务支持)
Memcache 在并发场景下,用cas保证一致性
redis事务支持比较弱,只能保证事务中的每个操作连续执行
mongoDB不支持事务
7)数据分析
mongoDB内置了数据分析的功能(mapreduce),其他不支持
8)应用场景
redis:数据量较小的更性能操作和运算上
memcache:用于在动态系统中减少数据库负载,提升性能;做缓存,提高性能(适合读多写少,对于数据量比较大,可以采用sharding)
MongoDB:主要解决海量数据的访问效率问题
http://www.blogjava.net/paulwong/archive/2013/09/06/403746.html