
论文源址:https://arxiv.org/abs/1704.05776
开源代码:https://github.com/xiaohaoChen/rrc_detection
摘要
大多数目标检测及定位算法基于R-CNN类型的两阶段处理方法,第一阶段生成可行区域框,第二步对决策进行增强。尽管简化了训练过程,但在benchmark获得较高mAP的结果下,单阶段的检测方法仍无法匹敌两阶段的方法。
本文提出了一个新的单阶段的目标检测网络用于克服上述缺点,称为循环滚动卷积结构,在多尺寸feature maps上构建目标分类器及边界框回归器。其在语义信息上较深。
介绍
在许多现实世界的应用中,高精度定位,但粗检测物体意味着以较高的IOU预测边界框进行定位。目前,目标检测依赖于前向卷积网络的成功应用,大致可分为两个分支,其中一个是R-CNN类型的两阶段方法。另一个是消除区域候选框阶段直接训练得到一个单阶段的检测器。单阶段检测器更易于训练而且更有效的部署生产中。然而,在benchmark的测试中,考虑较高IOU的条件下,其优势并不明显,而两阶段的方法在benchmark上的表现要优于单阶段的。本文后文会介绍,上述弱势并不是在复杂场景中无法目标识别的原因,但会导致无法生成高质量的边界框。如下图所示。

实验发现大多数低质量的边界框来自于小目标及重叠目标的失败定位。在任意情形下,传统的框回归变得越来越不可利用,由于正确边界框的准确定位必须由文本信息决定(像封闭区域附近的多尺度信息及特征),因此,通过利用一些上下文信息的形式来增强处理,进而有效的消除错误。Faster R-CNN的RoI Pooling及分类阶段可以看作是通过采样feature maps从而利用上下文信息的一种简便方式。
本文展示了在单阶段网络中通过融合上下文信息增强处理过程也是可能的。通过RRC结构可以实现deep in context。有必要时,上下文信息可以逐渐地,有选择性的引入边界框回归器中。整个处理过程是数据驱动,而且是端到端的训练方式。
本文贡献如下:(1)端对端的训练一个单阶段的网络在满足高精度定位的要求下产生一个非常准确的定位结果。(2)改进单阶段检测器的关键是通过RRC结构循环的引入上下文信息到边界框回归器中。
方法分析
当前方法的不足之处:
一个鲁棒性较强的检测系统必定可以检测不同尺寸及大小的物体。在Faster R-CNN中,依赖于在最后一层卷积层上进行3x3的重叠区域的较大的感受野同时检测大尺寸及小尺寸的物体。由于pooling 层的使用,最后一层的Feature map要比输入图片的分辨率要小的多。这对小目标的检测是存在问题的。因为,低分辨率的feature map对小目标的细节表示是薄弱的。将多尺寸的图片送入网络是解决上述问题的一种方式,但计算效率仍不足。
SSD提出了一种有效的替换措施。利用大多数CNN网络中存在的一种情况进行目标检测,不同层的中间feature maps由于pooling操作从而具有不同的尺寸。因此,可以,利用高分辨率的feature maps检测相对小的目标,而利用低分辨率的feature maps检测相对较大的目标。这种方法的优点在于不仅可以通过在高分辨率的feature map上进行分类和框回归操作从而对小目标进行更高精度的定位,而且作为单阶段的处理方法,要比以前的两阶段处理方法要快的多,因为,这种多尺寸的处理方式相比于原始的backone 网络并未增加额外的计算量。
然而,SSD仍无法超越两阶段的处理方法。实际上当在较高IOU的比较上,二者之间的差距还会加大。下文对SSD的限制进行解释,并提出解决方法,SSD的数学定义可以用下式表示。

上式等式(2)可以发现其依赖较强的假设。由于每层中的feature map都只负责对应尺寸的输出,因此,对于每个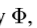 自身要足够的复杂,以至于可以用于对感兴趣物体的检测及精确定位。这意味着以下几个条件(1)要有足够的分辨率来表示物体的细节信息。(2)将输入图片变为feature maps的函数要足够的深从而可以在feature map中构建足够多的抽象信息。(3)feature maps中包含适量的上下文信息。可以鲁棒的确定重叠对象,遮挡对象及小目标,模糊物体的准确定位。从上式可以观察到,当k很大时,
自身要足够的复杂,以至于可以用于对感兴趣物体的检测及精确定位。这意味着以下几个条件(1)要有足够的分辨率来表示物体的细节信息。(2)将输入图片变为feature maps的函数要足够的深从而可以在feature map中构建足够多的抽象信息。(3)feature maps中包含适量的上下文信息。可以鲁棒的确定重叠对象,遮挡对象及小目标,模糊物体的准确定位。从上式可以观察到,当k很大时,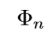 要比
要比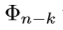 深得多。结果是
深得多。结果是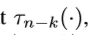 将第(n-k)层的feature maps变为检测输出,相比
将第(n-k)层的feature maps变为检测输出,相比 要弱一些,同时,要更难训练一点。而Faster R-CNN并没有深度问题,因为region proposals从最后一层的featue map上得到。
要弱一些,同时,要更难训练一点。而Faster R-CNN并没有深度问题,因为region proposals从最后一层的featue map上得到。

然而,上式仍存在问题,因为其破坏了上面的第(1)个条件,因此,本文认为定义如下函数用于单阶段的目标检测。函数 满足上述前两个条件,因为
满足上述前两个条件,因为 输出的feature maps不仅共享
输出的feature maps不仅共享 相同分辨率的feature maps,而且结合了更深层网络中的,
相同分辨率的feature maps,而且结合了更深层网络中的, 对等式(2)的改造仍为单阶段的处理方法是值得的。
对等式(2)的改造仍为单阶段的处理方法是值得的。

换言之,如果等式(4)满足第(3)个条件,同时,设计了一个高效的结构可以对其进行训练,就可以克服单阶段的不足,同时,甚至在较高的IOU阈值下超过两阶段的方法。
循环滚动卷积
RNN用于条件特征聚合
本文详细描述![]() ,该函数生成有用的上下文信息用于检测。对于不同的感兴趣物体,
,该函数生成有用的上下文信息用于检测。对于不同的感兴趣物体,![]() 中的上下文信息不同。比如,当检测小目标时,
中的上下文信息不同。比如,当检测小目标时,![]() 应该返回包含该目标高分辨率特征用于表示丢失的细节。当检测有遮挡的物体时,其会返回包含该目标大量抽象信息,使其遮挡时的特征具有相对不变性。当检测重叠物体时,函数应该返回包含边界信息及高层次抽象信息用于区分不同的目标物体。然而,对于像
应该返回包含该目标高分辨率特征用于表示丢失的细节。当检测有遮挡的物体时,其会返回包含该目标大量抽象信息,使其遮挡时的特征具有相对不变性。当检测重叠物体时,函数应该返回包含边界信息及高层次抽象信息用于区分不同的目标物体。然而,对于像![]() 中间层的特征信息,上述的所有上下文信息都可以从其低级层
中间层的特征信息,上述的所有上下文信息都可以从其低级层![]() 或者
或者![]() 上检索到信息。难点在于很难给
上检索到信息。难点在于很难给![]() 人为固定一种规则在H中由
人为固定一种规则在H中由![]() 至
至![]() 来检索合适的feature maps。而且人为选择q及r是困难的。因此,必须从数据中系统的学习特征检索及聚合过程。
来检索合适的feature maps。而且人为选择q及r是困难的。因此,必须从数据中系统的学习特征检索及聚合过程。
然而,![]() 也许会比较麻烦,因为
也许会比较麻烦,因为 为包含不同层多个feature maps的几何,并不明确哪一层应该被包含,对于当前目标应该在feature map上加入什么操作。因此,从
为包含不同层多个feature maps的几何,并不明确哪一层应该被包含,对于当前目标应该在feature map上加入什么操作。因此,从![]() 至有用的
至有用的![]() 建立直接映射,必须要利用具有多层非线性且较深的网络。计算上并不高效,同时单阶段网络也难于训练。替换方法为设计一个迭代的处理过程,每一步都改变一点,但一直保持增长。处理过程可以用如下表达式进行描述。
建立直接映射,必须要利用具有多层非线性且较深的网络。计算上并不高效,同时单阶段网络也难于训练。替换方法为设计一个迭代的处理过程,每一步都改变一点,但一直保持增长。处理过程可以用如下表达式进行描述。

上式描述过程如下图,输入为I,输出特征图为![]() ,当
,当![]() 函数应用于分类及边界回归,输出仅限于
函数应用于分类及边界回归,输出仅限于![]() 。
。![]() 函数可以执行特征融合用于生成足够的上下文信息。同时,在第2步中得到
函数可以执行特征融合用于生成足够的上下文信息。同时,在第2步中得到![]() ,函数
,函数 输出一个基于更新后的feature map
输出一个基于更新后的feature map![]() 的一个增强的结果。值得注意的是可以在训练的每一步引入一个监督信号从而可以在特征聚合中找到有用的上下文信息,从而可以提高检测效果。如果
的一个增强的结果。值得注意的是可以在训练的每一步引入一个监督信号从而可以在特征聚合中找到有用的上下文信息,从而可以提高检测效果。如果![]() 和
和 中权重在每一步都是共享的,这是一个循环网络。由于循环用于确保每个步骤都进行特征聚合,因此无法被忽略。使每步的特征融合都很平滑。否则,极易发生过拟合进而导致意想不到的偏差。
中权重在每一步都是共享的,这是一个循环网络。由于循环用于确保每个步骤都进行特征聚合,因此无法被忽略。使每步的特征融合都很平滑。否则,极易发生过拟合进而导致意想不到的偏差。
RRC模型细节
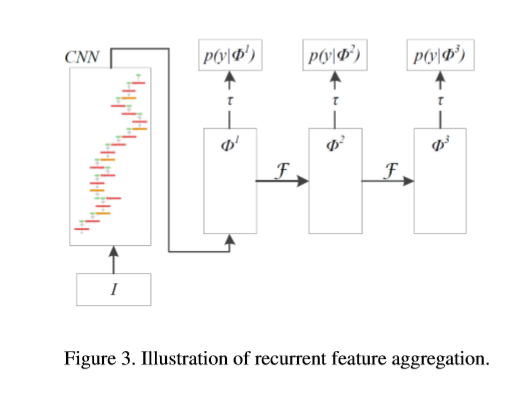
RRC模型细节
如果对每个feature map ![]() 应用上式(5),就是本文提出的RRC结构。值得一提的是,
应用上式(5),就是本文提出的RRC结构。值得一提的是,![]() 是
是![]() 的一个函数,同时其直接相关层为
的一个函数,同时其直接相关层为![]() ,
,![]() ,如果对于前面两个feature map有独立的
,如果对于前面两个feature map有独立的![]() ,在迭代足够多次以后,
,在迭代足够多次以后,![]() 中的值将会被
中的值将会被![]() 中的所有feature maps所影响。提出的RRC模型如下图所示。使用精简后的vgg-16作为backbone。
中的所有feature maps所影响。提出的RRC模型如下图所示。使用精简后的vgg-16作为backbone。

网络的输入大小为1272x375x3,原始的conv4_3层及FC7层的尺寸为159x47x512 ,80x24x1024,另外,在特征融合前。使用额外的3x3的卷积层来进一步降低通道数至256。类似于SSD,使用conv8_2,conv9_2及conv10_2用于多尺寸的检测,不同点在于RRC中conv8_2层的通道数为256而不是512。本文通过实验发现,多尺度特征图中处理后的通道数可以促进特征聚合。
本文使用一个卷积层及反卷积层来进行特征聚合。比如,对于conv8_2带1x1的卷积层用于生成大小为40x12x19的feature maps,然后,经过ReLU及反卷积层后拼接在FC7层的后面。上图中所有左箭头代表进行向下操作,使用,一个卷积层及最大池化层来执行向上特征融合操作。以conv8-2举例,一个1x1的卷积跟在ReLU及最大池化层的后面,生成20x6x19大小的feature maps 接在conv9_2。相似的是,所有图中的右箭头代表向上操作。由于左箭头及右箭头的操作,将特征聚合过程为"rolling"。
RRC 讨论
RRC是一个循环的处理过程,每次迭代过程中收集聚合用于检测的相关特征。这些重要特征包含对具有挑战性的目标有重要的上下文信息。对于每个RRC,都有一个单独的损失函数对其进行指导学习。这可以确保逐渐导入相关特征,并在每次迭代中实现期望中的进展。由于RRC可以执行多次,因此,得到的特征是"deep in context"。RRC并不是针对特定边界框制定的。因此,可以利用上下文信息中的深度来检测每个目标物体。
损失函数
训练时,每次迭代都有自己loss 函数,遵从SSD,对目标类别分类的损失函数为交叉熵损失。Smooth L1 loss用于边界框的回归。
边界框回归及空间离散化
一层中的一组feature maps用于固定边界框大小的回归。由于边界框的回归为一个重要的线性过程,如果范围过大或者feature 过于复杂,边界框回归的稳健性将会受到很大的影响。由于RRC结构增加了feature maps中大量的上下信息,将不可避免的丰富feature maps,而基于此feature map,对于原目标区域,边界框的回归会更加困难。为了克服这个问题,并使边界框的回归更加稳健,通过给特定的feature map增加大量的回归器来进一步离散化边界框的回归空间,是每个回归器对应更简单的任务。
实验



Reference
[1] D.Bahdanau,K.Cho,andY.Bengio. Neuralmachinetranslation by jointly learning to align and translate. In ICLR, 2015. 2
[2] Z. Cai, Q. Fan, R. S. Feris, and N. Vasconcelos. A unified multi-scaledeepconvolutionalneuralnetworkforfastobject detection. In ECCV, 2016. 7
[3] X.Chen,K.Kundu,Z.Zhang,H.Ma,S.Fidler,andR.Urtasun. Monocular 3d object detection for autonomous driving. In CVPR, 2016. 7
[4] X.Chen,K.Kundu,Y.Zhu,A.Berneshawi,H.Ma,S.Fidler, andR.Urtasun. 3dobjectproposalsforaccurateobjectclass detection. In NIPS, 2015. 7
[5] J. Dai, Y. Li, K. He, and J. Sun. R-fcn: Object detection via region-basedfullyconvolutionalnetworks. InNIPS,2016. 2
[6] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In CVPR, 2012. 1, 6