
论文原址:https://arxiv.org/pdf/1808.01244.pdf
github:https://github.com/princeton-vl/CornerNet
摘要
本文提出了目标检测算法的新的模型结构,利用单个卷积网络将框的左上角及右下角两个点组成一对关键点,进而不需要设计在单阶段检测中大量的anchor boxes,同时,引入了corner pooling用于提升角点定位效果。
介绍
单阶段检测通过密集的anchor box及后续的增强定位来获得好的检测效果,但使用anchor存在以下几点问题:(1)需要大量的anchor box,然而只有一小部分的anchor box与ground truth 存在较大的重叠,这就会造成类别不平衡问题,而且不利于训练。(2)使用anchor 引入了大量人为的超参数及设计方法(数量?大小?比例?)。
本文引入了新的单阶段检测方法,其并未依赖于anchor box。本文将框的左上角及右下角两个角点看作一组关键点。用一个卷积网络预测所有同一类别的样本的左上角点的heatmap,及右下角点的heatmap,及一个检测到角点的embeding vector。embeding用于组合属于同一个目标的一对角点,网络预测其相似的embedings。本模型简化了模型的输出,同时移除了anchor的设计步骤。本文受人体关键点检测思想启发,整个思路图如下
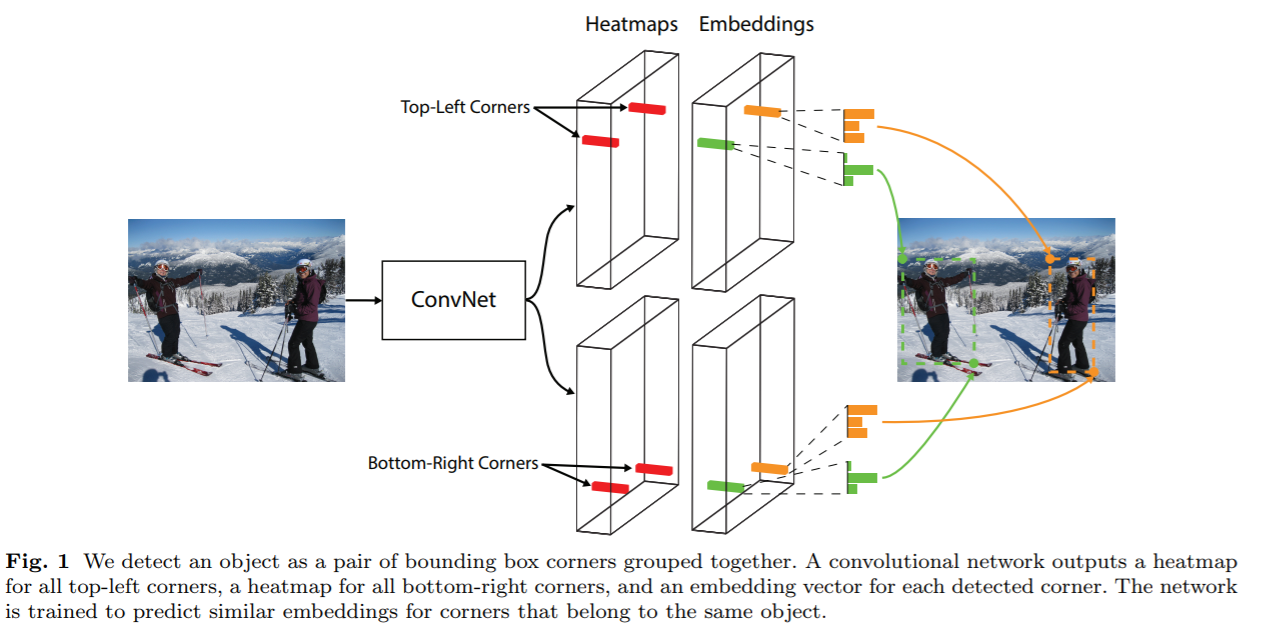
Cornernet的另一个创新点是corner pooling,有利于卷积网络定位边界框的角点。如下图所示,一个边界框的角点经常在目标物的外边。这种情况下,一个角点无法根据局部特征进行定位。为了确定一个像素点处是否存在左上角的角点,需要从右侧观察边界框其顶部水平方向,同时,从下观察边界框的最左边。

Corner pooling受上述启发,如下图,输入两个feature maps,对第一个Feature map的所有向量的左侧进行max pool操作,对第二个feature map所有向量的顶部进行max pool,最后将二者的结果进行相加处理。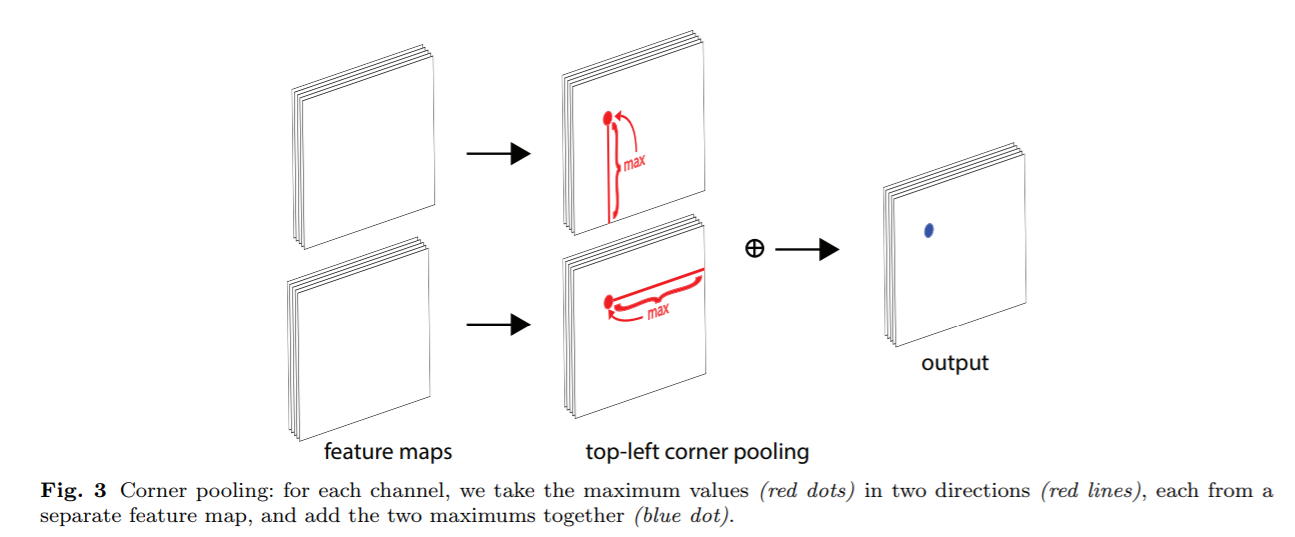
本文认为基于Corner 的目标检测要优于proposals的检测方法主要有两点:(1)由于框的中心依赖于四个边很难进行定位。而定位角点只需要定位两条边,同时引入了coner pool的先验,因此,定位更加简单。(2)角点高效的离散了框的解空间,只需要O(wh)的角点可以表示O(w^2h^2)的anchor box的数量。
CornerNet
整体流程:将检测框的左上及右下的点作为一组角点。一个单一结构的卷积网络用于预测两组不同目标类别的heatmaps,一组heatmaps用于预测左上角的点,另一组用于预测右下角的点,同时预测一个embedings向量,比如来自同一目标类别的两个角点之间的距离很小。为了得到更加紧密的边框,网络同时预测一个偏差用于调整角点的位置。有了,两个角点的heatmaps,embeding vectors,及Offset,后面通过使用一个后处理的方法来获得最终的边框。如下图所示,使用hourglass 网络作为backbone,其后接着两个预测模型,一个用于预测左上角的点,另一个用于预测右下角的点。每个模型都有自己的corner pool层,在进行预测heatmaps,embeding vector,offset之前pool hourglass 网络的feature maps.本文并使用不同的尺寸检测目标物,只借助模型的两个输出角点进行目标检测。

角点的检测:预测两组heatmaps,每组heatmaps的尺寸为HxWxC。C代表目标物的类别。没有背景这个类别,每个通道的feature map为二值型的mask,代表是否为该类别。对于每个角点,存在一个ground truth positive location,其余的位置为negative.本文降低了对正样本附近圆周位置的负样本的惩罚,因为,一对距离对应ground truth很近的负样本角点也可以产生一个较好的边界框,包围目标物。如下图所示。

本文通过确保半径内的一对点将生成与ground truth box重叠度至少为0.3的框来确定对象大小的半径。有了半径,惩罚度由unnormalized的高斯分布生成。等式如下

Pcij代表第(i,j)类别为c的概率,ycij代表对应的经过unnormalized 高斯分布增强过的ground truth 标签,定义了新的Focal Loss如下。

在下采样阶段中,(x,y)位置的像素被映射为(x/n,y/n),而对其还原时,会存在一定精度上的损失,对IOU造成影响,因此,在对其remap到输入尺寸之前,预测位置偏移对角点的位置进行微调。

角点组合:一张图中可能会存在多个目标,因此,可能会检测到多组角点。这里需要确定,一组左上角及右下角的点是否是来自同一个边界框的。本文借鉴人体关键点检测中基于一组embeding 向量来确定是否将关键点进行组合,本文也预测了embeding vectors。通过,基于左上角点的embeding vectors及右下角点embeding vectors的距离来决定是否将两个点进行组合。重要的是二者之间的距离,而向量中的具体数值却不是很重要。本文使用1-D的embeding 向量,etk代表目标k左上角点的embeding ,ebk代表其右下角点的embeding。定义"pull"损失用于组合角点,“push”损失用于分离角点。如下,

Corner Pooling:角点的表示没有任何局部视觉信息,因此要确定一个像素是否为左上角的点,需要从框的顶部水平的向右观察,同时,在框的左边从下观察。提出了corner pooling基于先验以更好的对框进行定位。
假设判断(i,j)位置的像素是否为左上角的点,ft,fl为两个输入corner pooling 的feature maps,ftij,flij分别为feature map上(i,j)位置的向量。对于一个HxW的feature map,corner pool首先max pool,ft中(i,j)到(i,H)之间所有的特征向量得到向量tij,同理,max pool fl中(i,j)至(W,j)之间所有的特征向量得到向量lij,最后,将tij与lij进行相加操作。表达式如下,基于elementwise max 操作,右下角的定义同理,处理(0,j)->(i,j),(i,0)->(i,j)之间的特征向量。


预测模型结构如下,模型的第一部分为修改的残差块,将第一个3x3的卷积替换为corner pooing,首先通过2个3x3x128的卷积核来处理来自backbone的feature map,后接一个corner pool层,将Pooled后的feature map送入3x3x256的conv-BN层中,同时增加了一个映射短链接,修正的残差块后接一个3x3x256的卷积及三个conv-BN-ReLU模块用于预测heatmaps,embedings,offsets。

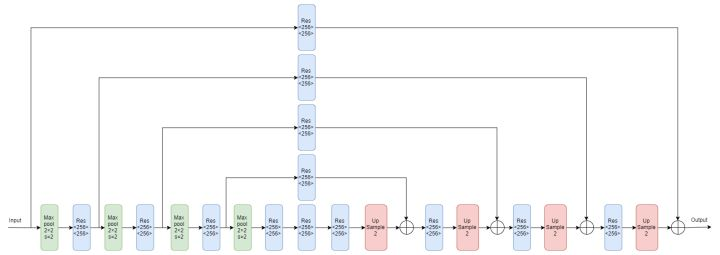
Hourglass Network:CornerNet将Hourglass 网络作为backbone,Hourglass网络被首次用于人体姿态估计任务,包含多个hourglass模型,hourglass模型首先会对输入图片通过一系列卷积池化操作进行降采样,然后通过一系列上采样,反卷积等操作恢复至输入的分辨率。为了弥补最大池化过程中丢失的细节信息,增加了跳跃结构,来恢复上采样的细节信息。hourglass在单一结构中同时捕捉了局部及全局特征信息。当多个hourglass模型组合在一起时可以获得更高级别的特征信息。本文的hourglass网络包含两个hourglass模块,并对其结构做了适当的更改。使用stride 2的卷积操作替换max pooling进行尺寸缩小,本文将分辨率减小5倍,通道数为{256,384,384,384,512},在对特征进行上采样时,在最近的相邻上采样块中添加了两个残差模型。每个跳跃连接也由两个残差模型组成。在一个hourglass模型的中间存在四个残差模型,通道数为512,在hourglass模型之前,使用7x7x128,stride=2的卷积将输入分辨率降4倍。同时接一个stride 为2通道数为256的残差模块。在训练过程中增加了中间监督,但其预测结果并未返回网络,因为对最终结果产生不良影响。在hourglass模型的输入及输出使用1x1的conv-BN模型,对结果通过后接ReLU及通道数为256的残差块进行像素级相加进行特征融合作为下一个hourglass的输入。hourglass网络的深度为104,只用网络的最后一层特征作预测。原始hourglass网络如下:
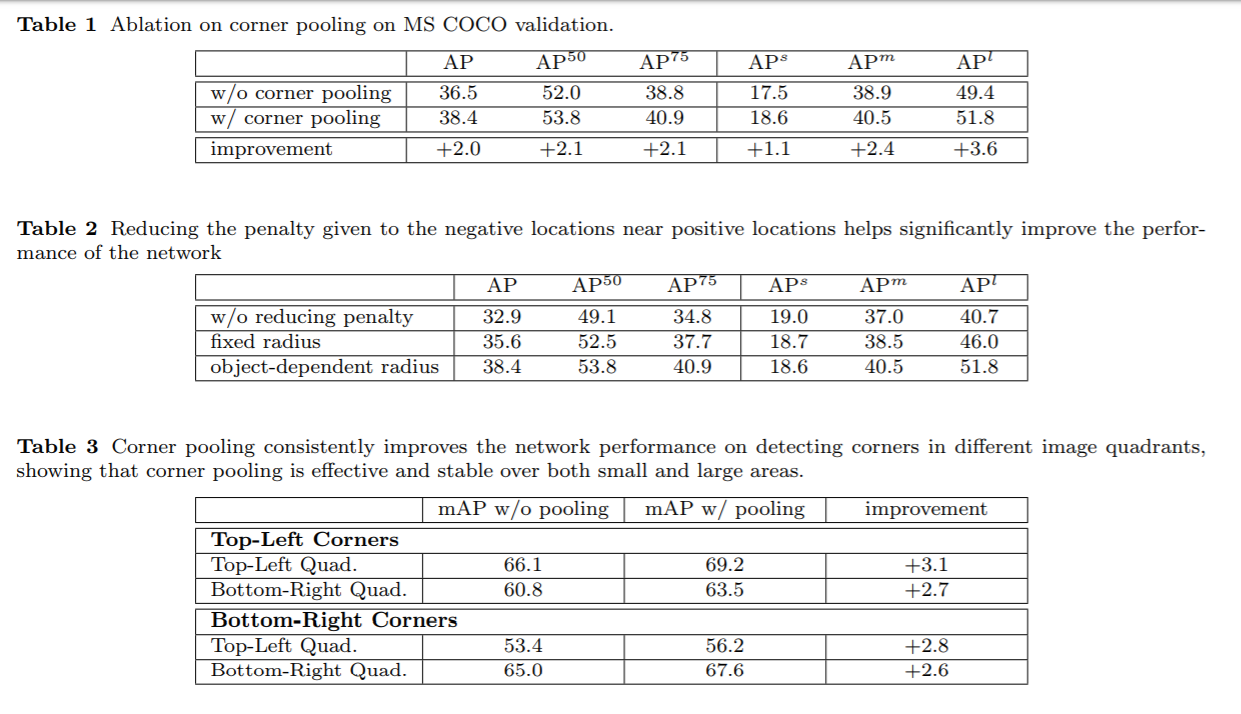
实验

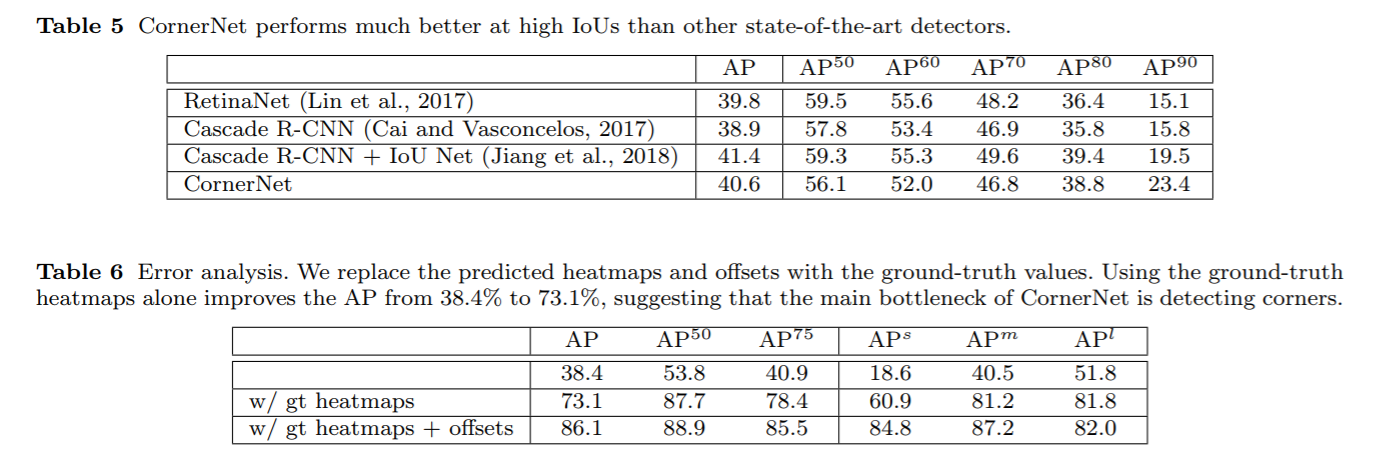

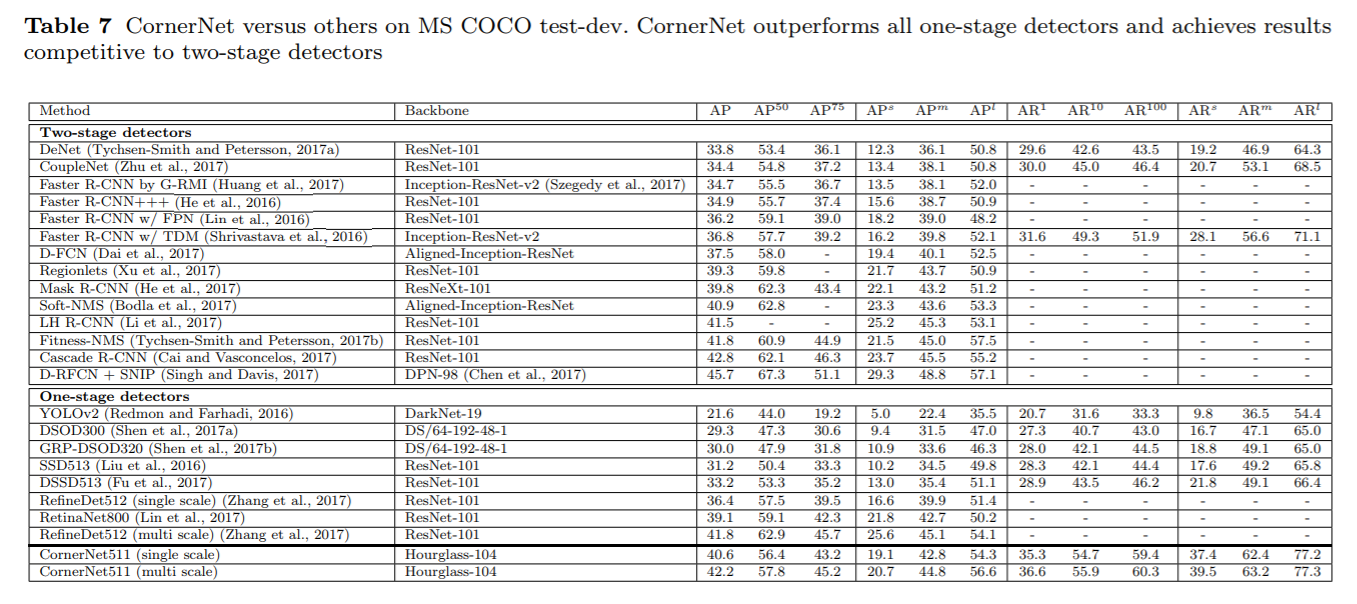


Reference
1.Bell, S., Lawrence Zitnick, C., Bala, K., and Girshick, R. (2016). Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2874–2883.
2.Bodla, N., Singh, B., Chellappa, R., and Davis, L. S. (2017). Soft-nmsimproving object detection with one line of code. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 5562– 5570. IEEE.
3.Cai, Z., Fan, Q., Feris, R. S., and Vasconcelos, N. (2016). A unified multi-scale deep convolutional neural network for fast object detection. In European Conference on Computer Vision, pages 354– 370. Springer.
4.Cai, Z. and Vasconcelos, N. (2017). Cascade r-cnn: Delving into high quality object detection. arXiv preprint arXiv:1712.00726.