
论文原址:https://arxiv.org/pdf/1904.08900.pdf
github:https://github.com/princeton-vl/CornerNet-Lite
摘要
基于关键点模式进行目标检测是一种新的方法,他并不需要依赖于anchor boxes,是一种精简的检测网络,但需要大量的预处理才能得到较高的准确率。本文提出CornerNet-Lite,是CornerNet两种变形的组合,一个是CornerNet-Saccade,基于attention机制,从而并不需要对图片中的每个像素做详尽的处理。另一个是CornerNet-Squeeze,引入了新的复杂的backbone结构。结合这两个变形可以应用到两个重要情景中:(1)在不降低准确率的情况下挺高效率,同时,在实时检测过程中提高了准确率,CornerNet-Saccade即适合做离线处理,也适用于实时的检测。
介绍
CornerNet的推理速度是其一个缺点,对于任意目标检测模型可以从两个方向提高其inference效率,一个是降低处理的像素量,另一个是减少每个像素的处理过程。针对这两个方向,分别提出了CornerNet-Saccade及CornerNet-Squeeze,统称为CornerNet-Lite.
CornerNet-Saccade通过减少处理的像素的个数来提高inference的效率。利用一种类似于人眼扫视的注意力机制,首先经过一个下采样后的输入图片,生成一个attention map,然后再将其进行放大处理,接着进行后续模型的处理。这与之前原始的CornerNet在不同尺寸上使用全卷积是有区别的,CornerNet-Saccade通过选择一系列高分辨率的裁剪图来提高效率及准确率。
CornerNet-Squeeze通过减少每个像素的处理过程来加速inference,其结合了SqueezeNet及MobileNet的思想,同时,引入了一个新的backbone hourglass,利用了1x1的卷积,bottlenec层及深度分离卷积。
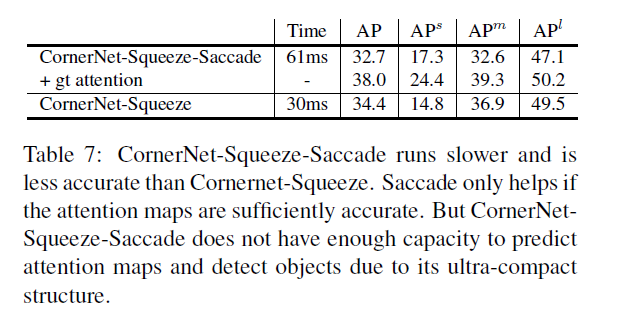
在CornerNet-Squeeze基础上增加saccades并不会进一步提高其效率,这是因为有saccade的存在,网络需要能够产生足够准确的注意力maps。但是CornerNet-Squeeze的结构并没有额外的计算资源。另外原始的CornerNet作用在多个尺寸中,提供了足够的空间来进行扫视操作,进而减少了处理像素的个数。相对的,CornerNet-Squeeze由于及其有限的inference负担,因此,只能在单尺寸上进行应用,因此,提高扫视的空间更少。
CornerNet-Saccade用于离线处理,在准确率不降的情况下,提高了效率。CornerNet-Squeeze用于实时处理,在不牺牲效率的前提下提升其准确率。CornerNet-Saccade是首个将saccades与keypoint-based 目标检测结合的方法,与先前工作的关键不同点在于每个crop处理的方法。以前基于saccade的工作要么对每个crop只检测一个目标,像faster r-cnn,要么在每个crop上产生多种检测器,双阶段的网络包含额外的sub-crops。相对的,CornerNet-Saccade在单阶段网络中每个crop产生多个检测器。
CornerNet-Squeeze首次将SqueezeNet与Hourglass网络结构进行组合,并应用到目标检测任务中。Hourglass结构在准确率上表现较好,但不清楚在效率上是否也有较好的效果。但本文证实了这种情况的可能性是存在的。
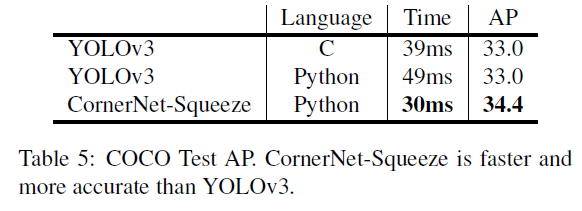
贡献:(1)提出了CornerNet-Saccade 及 CornerNet-Squeeze,用于提高基于关键点目标检测的效率。(2)COCO,提高了6倍检测效率,AP从42.2%提升至43.2%(3)将目标检测较好的算法YOLOv3的准确率及性能由33.0%39ms提升至34.4% 30ms。
相关工作
目标检测中的扫视功能,人类视觉中的扫描指的是在固定的不同区域中进行一系列的快速扫描。在目标检测算法中,使用这个方法以顺序或者并行的方式进行有选择的进行裁剪及处理图片区域。可以有效的提升inference的速度,在R-CNN,Fast-RCNN,Faster R-CNN中裁剪的图片中存在潜在的目标物。经过分类和回归操作后,每个剪裁后的图片要么被丢弃,要么转换为一个单一带标签的框。Cascade R-CNN在Faster R-CNN的基础上增加了分类器及回归器进而进一步的筛选增强边框。saccade在这些R-CNN变形中处理的crop只有一种类型,而且每个crop最多只包含一个目标物。然而在CornerNet-Saccade中,saccades是单类型,同时是多目标的。因此,通过CornerNet-Saccade产生的crop的数量会比目标的数量少很多。
CornerNet-Saccade
在一张图片中,cornerNet-Saccade在可能存在目标物proposal的小区域范围内进行目标检测。利用下采样后的图片进行attention maps及大致边界框的预测,这两个都可以大致提出目标物可能存在位置。CornerNet-Saccade接下来会通过在高分辨率图片上检测该区域的中心进而检测到目标物。通过控制每张图片处理的最大数量的目标物的位置来达到准确率及效率的权衡。 CornerNet-Saccade的流程如下所示。

Estimating Object Locations:首先是要获得一张图片中可能存在目标物的位置信息。本文在一张下采样后的图片上得到attention maps,用于代表目标物的位置以及对应位置上目标物的大致大小。给定一张图片,缩小2倍,至边长为255或者为192,将边长为192的进行padding操作使其大小与255的相同,因此,可以进行并行处理。使用低分辨率图片的原因有两个:(1)这样操作会减少inference时间上的消耗(2)网络可以很容易得到图片中的上下文信息进而进行attention maps的预测。
对于下采样后的图片,CornerNet-Saccade预测出3个attention maps,其中一个用于小目标,一个用于中等目标,剩下一个作用于大的目标。如果一个目标物的较长边的像素小于32,则被视为小目标,32到96的视为中等目标,大于96的是大目标。针对不同尺寸的物体的位置进行独立的预测,可以更好的控制CornerNet-Saccade对每个位置的重视程度。相比于中等目标,可以更多的关注小目标。
通过在不同尺寸的feature maps上预测出attention maps。feature maps由CornerNet-Saccade的backbone hourglass网络得到。每一个hourglass模型通过一系列的卷积及下采样操作对输入图片进行缩小,然后,通过一系列的上采样及转置卷积将feature map恢复到输入图片大小的分辨率。而attention maps由上采样的层得到。对于尺寸较精细的feature maps用于预测小目标,而粗糙尺寸的框用于检测较大的目标。本文通过在每个feature map后面更上一个3x3的conv-ReLU+1x1的conv-sigmoid模型来得到attention maps。在测试过程中,只处理分数大于0.3的位置。
当CornerNet-Saccade处理下采样后的图片,极有可能会检测到一些目标物,同时,产生一些边界框,单由于分辨率较低,因此,这些框可能并不是很准确,因此,需要在高分辨率上进行评估,进而得到更好的边界框。
训练时,将对应attention map上的边界框的中心设置为positive,其余为negative,然后,使用![]() 的Focal loss。
的Focal loss。
目标检测:CornerNet-Saccade利用从downsized image中得到的位置来确定哪里需要进行处理。如果直接从downsized图片中裁剪,则一些目标物可能会太小以至于无法准确的进行检测。因此,需要刚开始就在高分辨率的feature map上得到尺寸信息。
对于从attention maps得到的位置,可以针对不同尺寸的目标设置不同的放大尺寸。Ss代表小目标的缩放尺寸,Sm代表中等目标的缩放尺寸,Sl代表大目标的缩放尺寸。整体三者之间存在一种关系,Ss>Sm>sl,因为,我们需要对小目标进缩放的成都要大一些。本文设置如下,Ss=4,sm=2,sl=1.对于可能存在的位置(x,y),根据大致的目标尺寸,按照si的比例对downsized图片进行放大,![]() ,然后,将CornerNet-Saccade应用到255x255窗口的中心位置处。
,然后,将CornerNet-Saccade应用到255x255窗口的中心位置处。
从预测的边界框中得到的位置包含更多目标物的尺寸信息。可以利用得到的边界框的尺寸来确定缩放大小。确定缩放比例后,使小目标的长边为24,中等目标的为64,大目标的为192。
在可能的位置处检测到目标物后,基于soft-NMS处理对于的检测结果。在对图片进行裁剪时,裁剪区域的边界可能会包含目标物的部分区域,如下图所示。产生的边界框可能包含目标物很少的区域,而无法倍soft-NMS处理掉,因此,删除了距离裁剪边界很近的边界框。训练时,采用与CornerNet相似的损失,用于预测corner heatmaps,embedings 及offsets。

准确率及效率的权衡:通过控制处理每张图片中目标位置的最大数量来进行准确率及效率上的平衡。本文更倾向于更有可能包含目标物的位置。在得到目标物的位置后,根据其分数及由边界框得到的先验位置来对位置进行排序,给定处理的crops的最大数量kmax,在前kmax的目标物的位置上进行物体检测。
Suppressing Redundant Object Locations:当目标物之间距离很近,如下图,会产生彼此重叠度较高的区域。两个区域都进行处理并不可取,因为,处理一个proposal会肯能检测到另一个proposal的目标。本文采用类似于NMS的方法用于移除冗余位置,首先将目标物的位置进行排序,由attention maps得到的边界框的位置的优先级较高。保留最好的目标物位置,同时移除与之相类似的位置,重复此操作。

Backbone Network:本文设计了一个新的hourglass网络,包含三个hourglass模型,深度为54层,称为Hourglass-54。每个hourglass 模型的参数较少而且网络较浅。本文将feature downsize 2倍。在每个下采样层的后面用了一个参差层及跳跃结构。每个hourglass模型将feature map减小3倍,同时通道数增加(384,384,512),在hourglass模型的中部 有一个通道数为512的残差模块,同时,在上采样的每一层都有一个参数模块。在每个Hourglass模型前对输入图片进行2倍的downsize。
训练细节:优化方法:Adam,inputSize:255x255,batchsize:48
CornerNet-Squeeze
CornerNet-Saccade通过关注子区域的像素来减少处理量。CornerNet-Squeeze减少每个像素处理过程中的计算量。CornerNet中,计算量主要消耗在Hourglass-104上,其由包含两个3x3的卷积及一个跳跃连接的残差块组成。虽然Hourglass-104的性能好,但是,其参数量大,而且inference时间长。本文借鉴了SqueezeNet及MobileNet的思想来设计一个轻量级的Hourglass结构。
Ideas:SqueezeNet通过将3x3的卷积替换为1x1的卷积,减少3x3卷积的通道数,以及后续的下采样操作来减少网络的参数量。SqueezeNet中的building block及fire module包含前两个思想,Fire Module首先会通过包含一系列1x1卷积核来减少输入的通道数,然后,将结果送到包含1x1及3x3卷积核的扩张层中。
本文将CornerNet-Squeeze中的参差块替换为fire module。将其中第二层的3x3的标准卷积替换为深度可分离卷积。变换前后操作数量的对比如下。上述Squeeze的第三条特点,并未考虑,因为,hourglass为沙漏型对称结构。后续的下采样的结果会在上采样过程中得到更高的分辨率,而在高分辨率的feature map上进行卷积操作会占用大量的计算资源,不利于实时检测。本文通过在hourglass模型之前增加更多的下采样层,移除每个hourglass模型中的一个下采样层来进一步减少Hourglass 模型中的最大分辨率数。CornerNet-Squeeze在hourglass 模型之前减少3倍的尺寸,而CornerNet只减少两倍。将CornerNet预测模型中的3x3卷积替换为1x1的卷积。最后,将hourglass网络中最相邻的上采样层替换为4x4的转置卷积。

实验





Reference
[1] A. T. Bahill, M. R. Clark, and L. Stark. The main sequence,a tool for studying human eye movements. Mathematical
Biosciences, 24(3-4):191–204, 1975.
[2] N. Bodla, B. Singh, R. Chellappa, and L. S. Davis. Softnms–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, pages 5561–5569, 2017.
[3] Z. Cai, Q. Fan, R. S. Feris, and N. Vasconcelos. A unified multi-scale deep convolutional neural network for fast object
detection. In European conference on computer vision, pages 354–370. Springer, 2016.
[4] Z. Cai and N. Vasconcelos. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6154–6162, 2018