论文链接:https://arxiv.org/abs/1802.02611
tensorflow 官方实现: https: //github.com/tensorflow/models/tree/master/research/deeplab
实验代码:https://github.com/fourmi1995/IronSegExperiment-Deeplabv3_PLUS.git
摘要
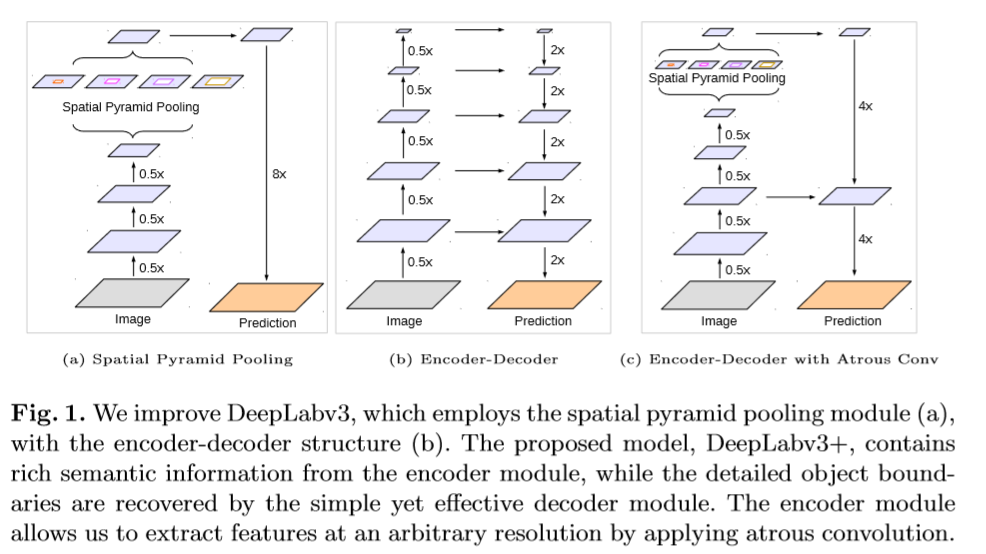
分割任务中常见的结构有空间池化模型与编码-解码结构,前者主要通过不同的卷积和不同rate的池化操作和感受野对输入的feature map编码多尺寸信息。编码-解码结构可以通过逐渐恢复空间信息获得物体的边缘信息。该文的改进:(1)结合了上述两种结构的优点。DeepLabv3+ 在DeepLabv3的基础上增加了一个decoder 模型来是增强物体边缘的分割。(2)引用了Xception中的深度可分卷积,应用在ASPP与decoder提高了网络的训练速度。
介绍
通过引入空洞卷积可以生成更加密集的feature map,然而由于GPU内存的限制,提取输入图片分辨率小4倍甚至8倍的feature map在计算上是不被允许的。而decoder层由于没有卷积核没有被扩张,因此计算速度上可以提高很多。本文的贡献如下。
(1)让DeepLabv3作为encoder,用一个简单有效的decoder模型,形成encoder-decoder结构。
(2)可以通过空洞卷积随意控制编码层feature map的分辨率。
(3)将Xception的深层可分卷积应用在ASPP与decoder模型中,使网络更快速。
(4)在PASCAL VOC2012与Cityscapes上得到stae-of-art的效果。
相关工作
Encoder-Decoder:(1)Encoder模型用于减少feature map的分辨率并捕捉更抽象的分割信息。(2)Decoder模型用于恢复空间信息。
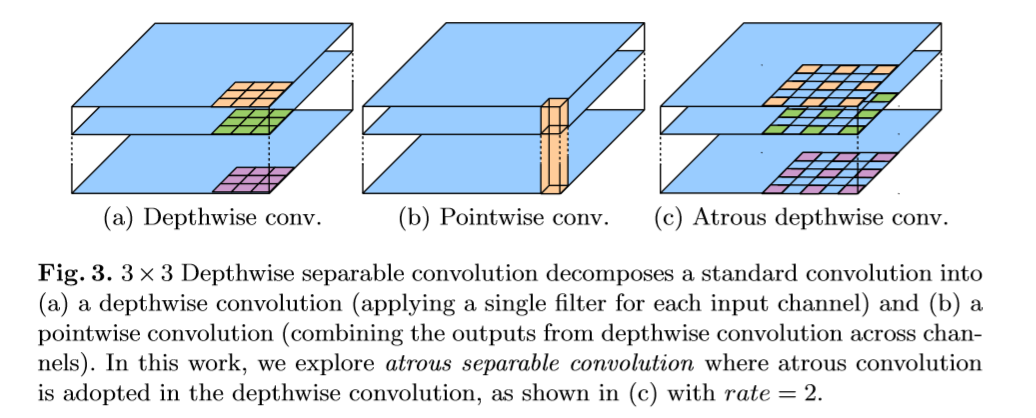
深度可分卷积(group 卷积):该卷积的一个优势是可以在保证性能相近的条件下尽可能的减少计算量和大量的可训练参数。
(参考博客:https://medium.com/@chih.sheng.huang821/%E6%B7%B1%E5%BA%A6%E5%AD%B8%E7%BF%92-mobilenet-depthwise-separable-convolution-f1ed016b3467)
方法
深度可分卷积,将标准的卷积拆为深度卷积,后接一个pointwise卷积(1x1卷积),极大的减少了计算量。深度卷积的功能是对每一个通道进行空间卷积,而pointwise卷积的功能是将深度卷积的输出进行融合。
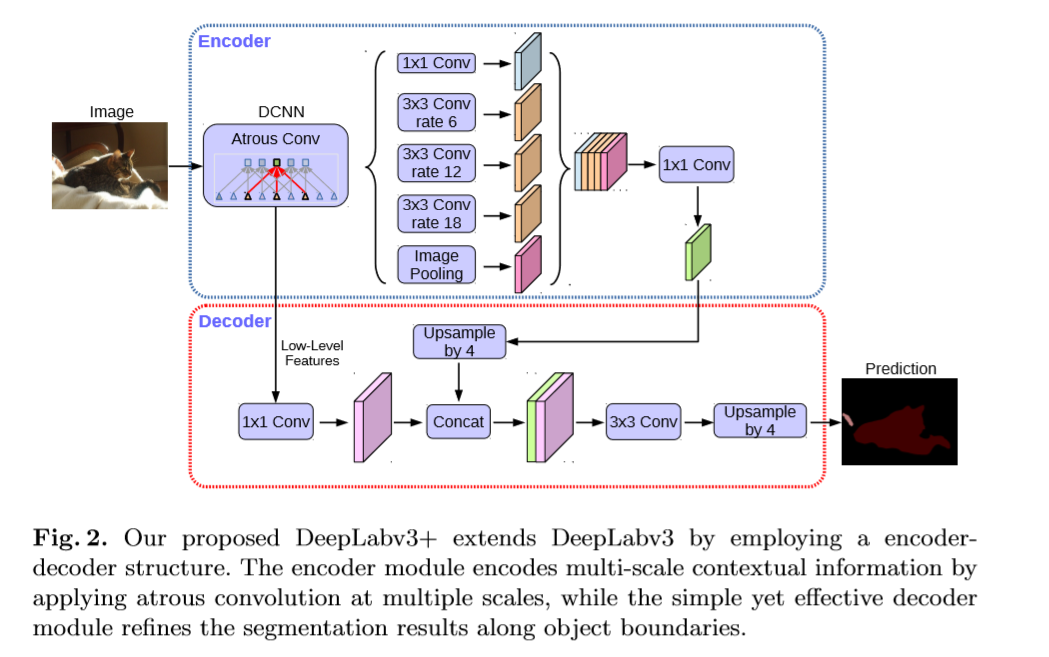
该文使用DeepLabv3中logits前最后一层的feature map作为encoder的输出。通常得到的out_stride为16,基于双线性插值上采样16倍作为decoder层比较常用,但有时可能得不到理想的效果(边界信息仍不准确)。该文提出如下模型。(1)首先通过双线性插值恢复4倍大小的分辨率。(2)然后与对应的低层次的feature map进行拼接,低层次的feature map首先用1x1的卷积处理降低通道数。(3)后接一个大小为3x3的卷积来增强feature maps(4)在通过一个插值来进一步恢复4倍分辨率至原图大小。
该文对Xception模型的改进,(1)加深了Xception(2)用深度可分卷积替换所有max pooling 减少了计算量,进而可以使用空洞卷积来提取feature(另一种方式是直接在max pooling 中应用空洞卷积)(3)在每个3x3的深度可分卷积后后接,BN层和ReLU。
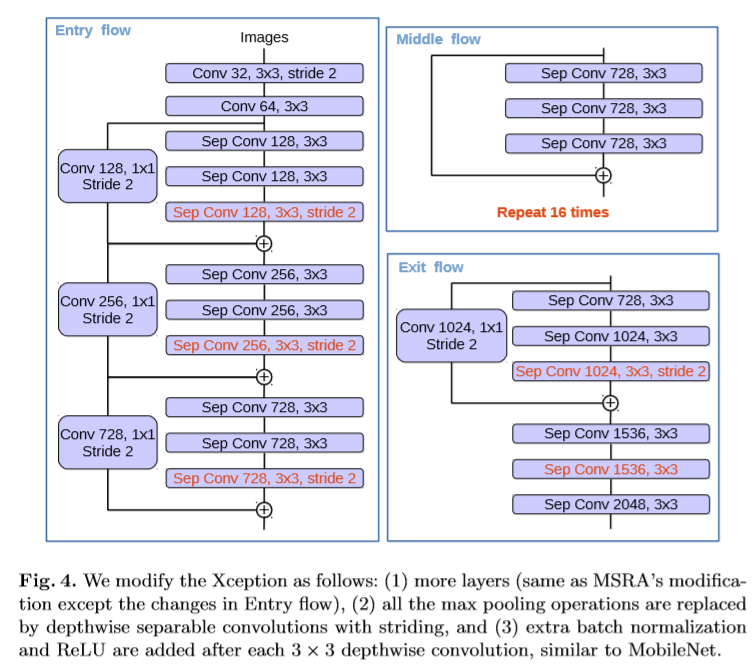
实验
该文使用了预训练的ResNet-101和改进后的Xception通过空洞卷积来提取密集的特征。
learning rate policy: "poly" , learning rate: 0.007, crop size: 513x513 , output_stride = 16,random scale data augmentation

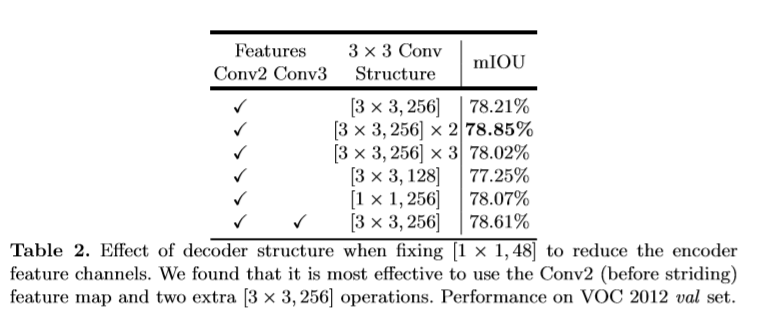
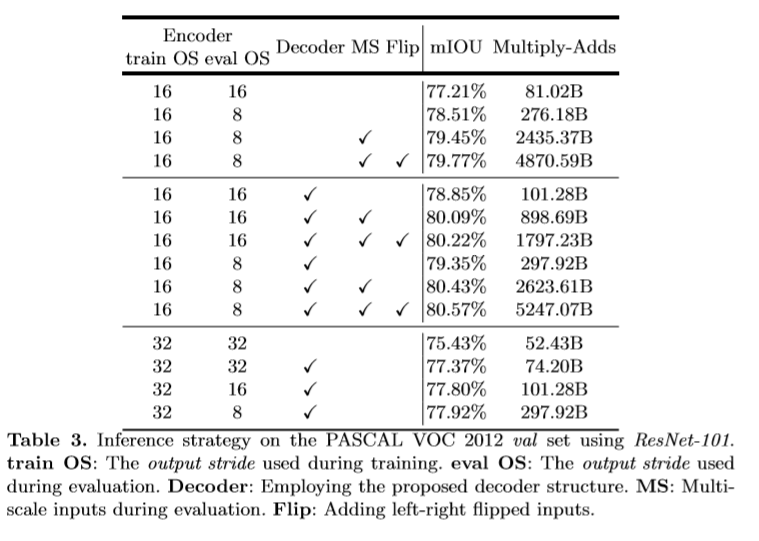

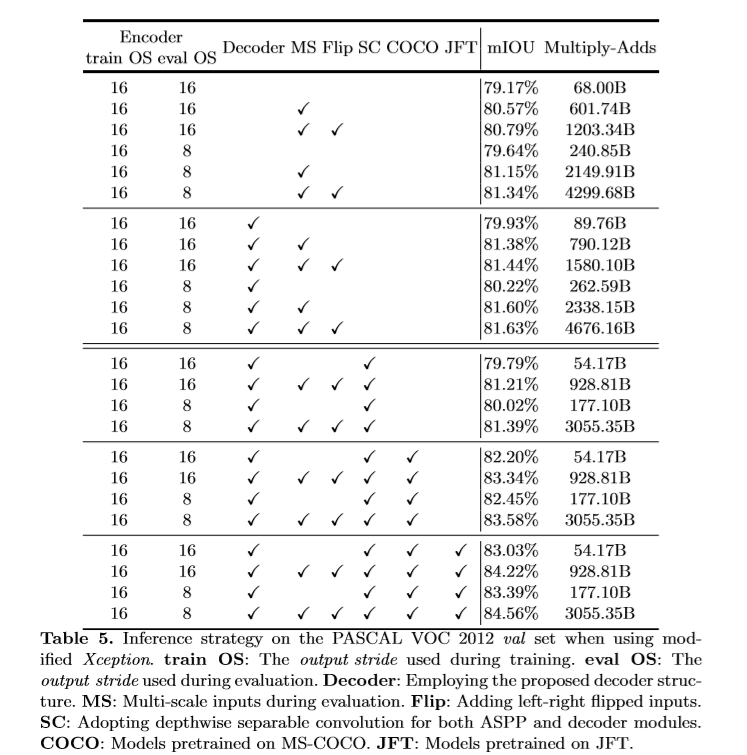
参考
1. Everingham, M., Eslami, S.M.A., Gool, L.V., Williams, C.K.I., Winn, J., Zisserman, A.: The pascal visual object classes challenge a retrospective. IJCV (2014)
2. Mottaghi, R., Chen, X., Liu, X., Cho, N.G., Lee, S.W., Fidler, S., Urtasun, R., Yuille, A.: The role of context for object detection and semantic segmentation in the wild. In: CVPR. (2014)
3. Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: CVPR. (2016)
个人实验结果