图示

1. 服务雪崩
1.1 什么是服务雪崩?
雪崩效应:是一种因服务"提供者"的不可用导致服务"调用者"的不可用,并将不可用逐渐放大的过程
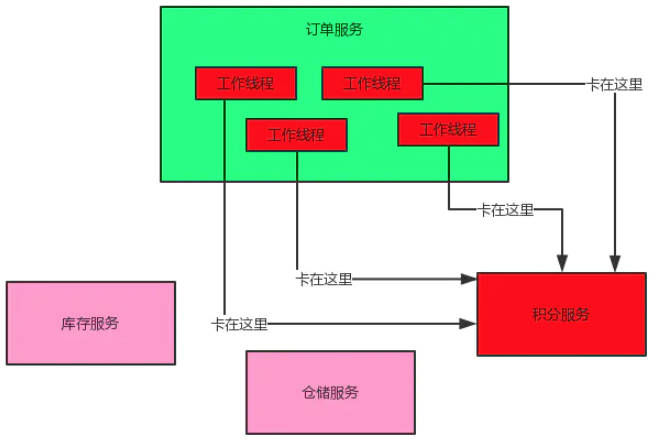
1.2 怎么产生服务雪崩?
1)服务提供者不可用
- a)硬件故障:硬件损坏造成的服务器主机宕机, 网络硬件故障造成的服务提供者的不可访问
- b)程序Bug:
- c) 缓存击穿:缓存击穿一般发生在缓存应用重启, 所有缓存被清空时,以及短时间内大量缓存失效时. 大量的缓存不命中, 使请求直击后端,造成服务提供者超负荷运行,引起服务不可用
- d)用户大量请求:在秒杀和大促开始前,如果准备不充分,用户发起大量请求也会造成服务提供者的不可用
2)重试加大流量
- a)用户重试:在服务提供者不可用后, 用户由于忍受不了界面上长时间的等待,而不断刷新页面甚至提交表单
- b)代码逻辑重试: 服务调用端的会存在大量服务异常后的重试逻辑
3)服务调用者不可用
- a)同步等待造成的资源耗尽:当服务调用者使用同步调用 时, 会产生大量的等待线程占用系统资源. 一旦线程资源被耗尽,服务调用者提供的服务也将处于不可用状态, 于是服务雪崩效应产生了。
2. Hystrix整体调用流程
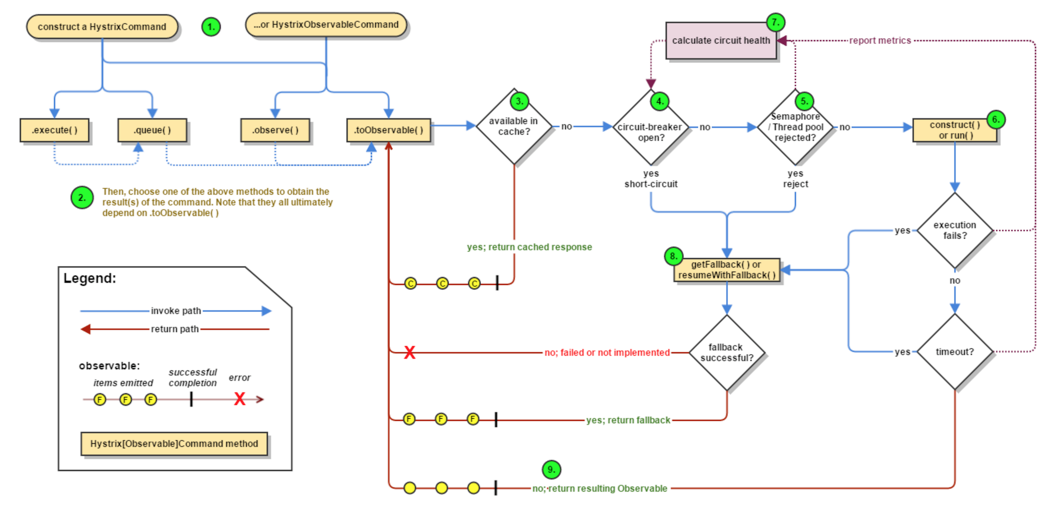
流程说明:1:每次调用创建一个新的HystrixCommand,把依赖调用封装在run()方法中。2:执行execute()/queue做同步或异步调用。3:判断熔断器(circuit-breaker)是否打开,如果打开跳到步骤8,进行降级策略,如果关闭进入步骤。4:判断线程池/队列/信号量是否跑满,如果跑满进入降级步骤8,否则继续后续步骤。5:调用HystrixCommand的run方法。运行依赖逻辑5a:依赖逻辑调用超时,进入步骤8。6:判断逻辑是否调用成功6a:返回成功调用结果6b:调用出错,进入步骤8。7:计算熔断器状态,所有的运行状态(成功, 失败, 拒绝,超时)上报给熔断器,用于统计从而判断熔断器状态。8:getFallback()降级逻辑。 以下四种情况将触发getFallback调用: (1):run()方法抛出非HystrixBadRequestException异常 (2):run()方法调用超时 (3):熔断器开启拦截调用 (4):线程池/队列/信号量是否跑满8a:没有实现getFallback的Command将直接抛出异常8b:fallback降级逻辑调用成功直接返回8c:降级逻辑调用失败抛出异常9:返回执行成功结果