总结
1.Redis的LRU
- 实现思路
- 最初思路:随机选三个Key,把idle time(距离最后一次被命令程序访问的时间)最大的那个Key移除。后来,把3改成可配置的一个参数,默认为N=5:
maxmemory-samples 5。该方法虽简单有效,但它还是有缺点的:每次随机选择的时候,并没有利用历史信息。其实每一轮在移除时,其实是知道了N个Key的idle time的情况的。如果有效利用这些信息,可以改进其准确性。 - 优化思路:采用缓冲池(pooling),把一个全局排序问题 转化成为了 局部的比较问题。当每一轮移除Key时,拿到了这个N个Key的idle time,如果它的idle time比 pool 里面的 Key的idle time还要大,就把它添加到pool里面去。这样一来,每次移除的Key并不仅仅是随机选择的N个Key里面最大的,而且还是pool里面idle time最大的,并且:pool 里面的Key是经过多轮比较筛选的,它的idle time 在概率上比随机获取的Key的idle time要大,可以这么理解:pool 里面的Key 保留了"历史经验信息"。
- 最初思路:随机选三个Key,把idle time(距离最后一次被命令程序访问的时间)最大的那个Key移除。后来,把3改成可配置的一个参数,默认为N=5:
- 数据结构
- Redis的LRU没有使用双向链表数据结构,它嫌LinkedList占用的空间太大了。
- Redis并不是直接基于字符串、链表、字典等数据结构来实现KV数据库,而是在这些数据结构上创建了一个对象系统Redis Object。在redisObject结构体中定义了一个长度24bit的unsigned类型的字段,用来存储对象最后一次被命令程序访问的时间。
2.非Redis的普通情况下,使用 HashMap + 双向链表 实现LRU的原因:
- 使用 HashMap [存储 key],这样可以做到 save 和 get key的时间都是 O(1)
- 双向链表可以让 [移除 key] 的时间也是 O(1)
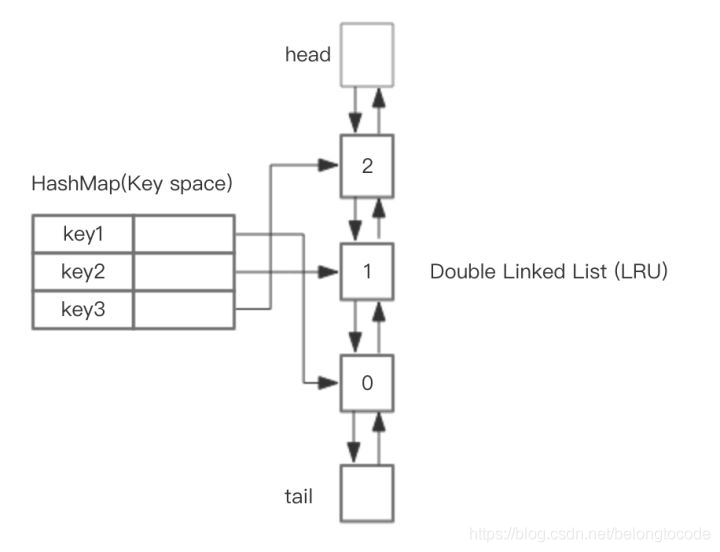
使用 HashMap 的 Value 指向双向链表实现的 LRU 的 Node 节点
一、LRU 原理(Least Recently Used)
在一般标准的操作系统教材里,会用下面的方式来演示 LRU 原理,假设内存只能容纳3个页大小,按照 7 0 1 2 0 3 0 4 的次序访问页。假设内存按照栈的方式来描述访问时间,在上面的,是最近访问的,在下面的是,最远时间访问的,LRU就是这样工作的。
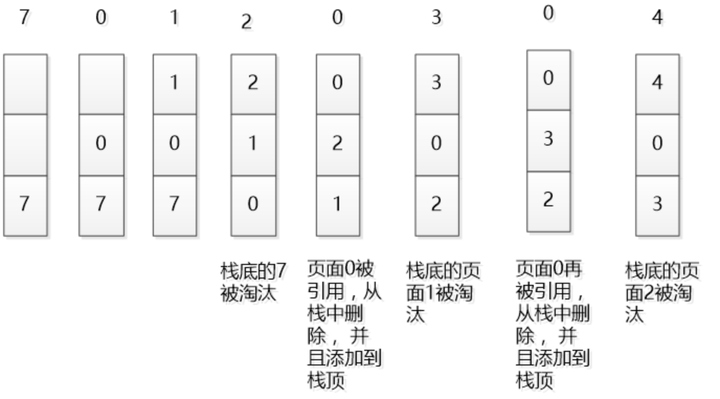
但是如果让我们自己设计一个基于 LRU 的缓存,这样设计可能问题很多,这段内存按照访问时间进行了排序,会有大量的内存拷贝操作,所以性能肯定是不能接受的。
那么如何设计一个LRU缓存,使得放入和移除都是 O(1) 的,我们需要把访问次序维护起来,但是不能通过内存中的真实排序来反应,有一种方案就是使用双向链表。
二、基于 HashMap 和 双向链表 实现 LRU
Java中的LinkedHashmap对哈希链表已经有了很好实现了,需要注意的是,这段不是线程安全的,要想做到线程安全,需要加上synchronized修饰符。
整体的设计思路是,可以使用 HashMap 存储 key,这样可以做到 save 和 get key的时间都是 O(1),而 HashMap 的 Value 指向双向链表实现的 LRU 的 Node 节点,如图所示。
RU 存储是基于双向链表实现的,下面的图演示了它的原理。其中 h 代表双向链表的表头,t 代表尾部。首先预先设置 LRU 的容量,如果存储满了,可以通过 O(1) 的时间淘汰掉双向链表的尾部,每次新增和访问数据,都可以通过 O(1)的效率把新的节点增加到对头,或者把已经存在的节点移动到队头。
下面展示了,预设大小是 3 的,LRU存储的在存储和访问过程中的变化。为了简化图复杂度,图中没有展示 HashMap部分的变化,仅仅演示了上图 LRU 双向链表的变化。我们对这个LRU缓存的操作序列如下:
save(“key1”, 7)
save(“key2”, 0)
save(“key3”, 1)
save(“key4”, 2)
get(“key2”)
save(“key5”, 3)
get(“key2”)
save(“key6”, 4)
相应的 LRU 双向链表部分变化如下:

总结一下核心操作的步骤:
save(key, value),首先在 HashMap 找到 Key 对应的节点,如果节点存在,更新节点的值,并把这个节点移动队头。如果不存在,需要构造新的节点,并且尝试把节点塞到队头,如果LRU空间不足,则通过 tail 淘汰掉队尾的节点,同时在 HashMap 中移除 Key。
get(key),通过 HashMap 找到 LRU 链表节点,把节点插入到队头,返回缓存的值。
完整基于 Java 的代码参考如下:
class DLinkedNode { String key; int value; DLinkedNode pre; DLinkedNode post; }
LRU Cache
public class LRUCache { private Hashtable<Integer, DLinkedNode> cache = new Hashtable<Integer, DLinkedNode>(); private int count; private int capacity; private DLinkedNode head, tail; public LRUCache(int capacity) { this.count = 0; this.capacity = capacity; head = new DLinkedNode(); head.pre = null; tail = new DLinkedNode(); tail.post = null; head.post = tail; tail.pre = head; } public int get(String key) { DLinkedNode node = cache.get(key); if(node == null){ return -1; // should raise exception here. } // move the accessed node to the head; this.moveToHead(node); return node.value; } public void set(String key, int value) { DLinkedNode node = cache.get(key); if(node == null){ DLinkedNode newNode = new DLinkedNode(); newNode.key = key; newNode.value = value; this.cache.put(key, newNode); this.addNode(newNode); ++count; if(count > capacity){ // pop the tail DLinkedNode tail = this.popTail(); this.cache.remove(tail.key); --count; } }else{ // update the value. node.value = value; this.moveToHead(node); } } /** * Always add the new node right after head; */ private void addNode(DLinkedNode node){ node.pre = head; node.post = head.post; head.post.pre = node; head.post = node; } /** * Remove an existing node from the linked list. */ private void removeNode(DLinkedNode node){ DLinkedNode pre = node.pre; DLinkedNode post = node.post; pre.post = post; post.pre = pre; } /** * Move certain node in between to the head. */ private void moveToHead(DLinkedNode node){ this.removeNode(node); this.addNode(node); } // pop the current tail. private DLinkedNode popTail(){ DLinkedNode res = tail.pre; this.removeNode(res); return res; } }
三、Redis 中如何实现 LRU
最直观的想法:LRU啊,记录下每个key 最近一次的访问时间(比如unix timestamp),unix timestamp最小的Key,就是最近未使用的,把这个Key移除。看下来一个HashMap就能搞定啊。是的,但是首先需要存储每个Key和它的timestamp。其次,还要比较timestamp得出最小值。代价很大,不现实啊。
第二种方法:换个角度,不记录具体的访问时间点(unix timestamp),而是记录idle time:idle time越小,意味着是最近被访问的。
The LRU algorithm evicts the Least Recently Used key, which means the one with the greatest idle time.

比如A、B、C、D四个Key,A每5s访问一次,B每2s访问一次,C和D每10s访问一次。(一个波浪号代表1s),从上图中可看出:A的空闲时间是2s,B的idle time是1s,C的idle time是5s,D刚刚访问了所以idle time是0s
这里,用一个双向链表(linkedlist)把所有的Key链表起来,如果一个Key被访问了,将就这个Key移到链表的表头,而要移除Key时,直接从表尾移除。
It is simple to implement because all we need to do is to track the last time a given key was accessed, or sometimes this is not even needed: we may just have all the objects we want to evict linked in a linked list.
但是在redis中,并没有采用这种方式实现,它嫌LinkedList占用的空间太大了。Redis并不是直接基于字符串、链表、字典等数据结构来实现KV数据库,而是在这些数据结构上创建了一个对象系统Redis Object。在redisObject结构体中定义了一个长度24bit的unsigned类型的字段,用来存储对象最后一次被命令程序访问的时间:
By modifying a bit the Redis Object structure I was able to make 24 bits of space. There was no room for linking the objects in a linked list (fat pointers!)
毕竟,并不需要一个完全准确的LRU算法,就算移除了一个最近访问过的Key,影响也不太。
To add another data structure to take this metadata was not an option, however since LRU is itself an approximation of what we want to achieve, what about approximating LRU itself?
最初Redis是这样实现的:
随机选三个Key,把idle time最大的那个Key移除。后来,把3改成可配置的一个参数,默认为N=5:maxmemory-samples 5
when there is to evict a key, select 3 random keys, and evict the one with the highest idle time
就是这么简单,简单得让人不敢相信了,而且十分有效。但它还是有缺点的:每次随机选择的时候,并没有利用历史信息。在每一轮移除(evict)一个Key时,随机从N个里面选一个Key,移除idle time最大的那个Key;下一轮又是随机从N个里面选一个Key...有没有想过:在上一轮移除Key的过程中,其实是知道了N个Key的idle time的情况的,那我能不能在下一轮移除Key时,利用好上一轮知晓的一些信息?
However if you think at this algorithm across its executions, you can see how we are trashing a lot of interesting data. Maybe when sampling the N keys, we encounter a lot of good candidates, but we then just evict the best, and start from scratch again the next cycle.
start from scratch太傻了。于是Redis又做出了改进:采用缓冲池(pooling)
当每一轮移除Key时,拿到了这个N个Key的idle time,如果它的idle time比 pool 里面的 Key的idle time还要大,就把它添加到pool里面去。这样一来,每次移除的Key并不仅仅是随机选择的N个Key里面最大的,而且还是pool里面idle time最大的,并且:pool 里面的Key是经过多轮比较筛选的,它的idle time 在概率上比随机获取的Key的idle time要大,可以这么理解:pool 里面的Key 保留了"历史经验信息"。
Basically when the N keys sampling was performed, it was used to populate a larger pool of keys (just 16 keys by default). This pool has the keys sorted by idle time, so new keys only enter the pool when they have an idle time greater than one key in the pool or when there is empty space in the pool.
采用"pool",把一个全局排序问题 转化成为了 局部的比较问题。(尽管排序本质上也是比较,囧)。要想知道idle time 最大的key,精确的LRU需要对全局的key的idle time排序,然后就能找出idle time最大的key了。但是可以采用一种近似的思想,即随机采样(samping)若干个key,这若干个key就代表着全局的key,把samping得到的key放到pool里面,每次采样之后更新pool,使得pool里面总是保存着随机选择过的key的idle time最大的那些key。需要evict key时,直接从pool里面取出idle time最大的key,将之evict掉。这种思想是很值得借鉴的。
参考文献
全面讲解LRU算法 https://blog.csdn.net/belongtocode/article/details/102989685
Redis的LRU实现 https://www.cnblogs.com/hapjin/archive/2019/06/07/10933405.html