一、图概念术语
1.1 基本概念
图是由顶点集合(vertex)及顶点间的关系集合(边edge)组成的一种数据结构。
这里的图并非指代数中的图。图可以对事物以及事物之间的关系建模,图可以用来表示自然发生的连接数据,如:社交网络、互联网web页面
常用的应用有:在地图应用中找到最短路径、基于与他人的相似度图,推荐产品、服务、人际关系或媒体
1.2 术语
1.2.1顶点和边
一般关系图中,事物为顶点,关系为边
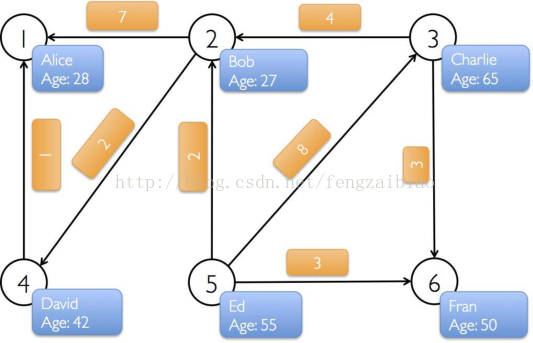
1.2.2有向图和无向图
在有向图中,一条边的两个顶点一般扮演者不同的角色,比如父子关系、页面A连接向页面B;
在一个无向图中,边没有方向,即关系都是对等的,比如qq中的好友。
GraphX中有一个重要概念,所有的边都有一个方向,那么图就是有向图,如果忽略边的方向,就是无向图。
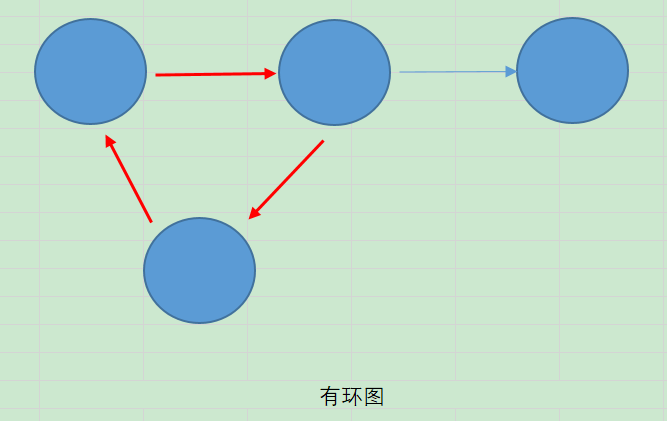
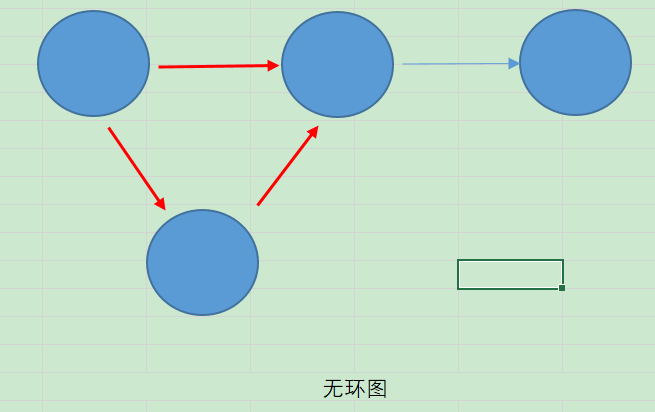
1.2.3有环图和无环图
有环图是包含循环的,一系列顶点连接成一个环。无环图没有环。在有环图中,如果不关心终止条件,算法可能永远在环上执行,无法退出。
1.2.4度、出边、入边、出度、入度
度表示一个顶点的所有边的数量
出边是指从当前顶点指向其他顶点的边
入边表示其他顶点指向当前顶点的边
出度是一个顶点出边的数量
入度是一个顶点入边的数量
1.2.5超步
图进行迭代计算时,每一轮的迭代叫做一个超步
二、图处理技术
图处理技术包括图数据库、图数据查询、图数据分析和图数据可视化。
2.1 图数据库
Neo4j、Titan、OrientDB、DEX和InfiniteGraph等基于遍历算法的、实时的图数据库;
2.2 图数据查询
对图数据库中的内容进行查询
2.3 图数据分析
Google Pregel、Spark GraphX、GraphLab等图计算软件。传统的数据分析方法侧重于事物本身,即实体,例如银行交易、资产注册等等。而图数据不仅关注事物,还关注事物之间的联系。例如,如果在通话记录中发现张三曾打电话给李四,就可以将张三和李四关联起来,这种关联关系提供了与两者相关的有价值的信息,这样的信息是不可能仅从两者单纯的个体数据中获取的。
2.4 图数据可视化
OLTP风格的图数据库或者OLAP风格的图数据分析系统(或称为图计算软件),都可以应用图数据库可视化技术。需要注意的是,图可视化与关系数据可视化之间有很大的差异,关系数据可视化的目标是对数据取得直观的了解,而图数据可视化的目标在于对数据或算法进行调试。
三、图存储模式
在了解GraphX之前,需要先了解关于通用的分布式图计算框架的两个常见问题:图存储模式和图计算模式。
巨型图的存储总体上有边分割和点分割两种存储方式。2013年,GraphLab2.0将其存储方式由边分割变为点分割,在性能上取得重大提升,目前基本上被业界广泛接受并使用。
3.1 边分割(Edge-Cut)
每个顶点都存储一次,但有的边会被打断分到两台机器上。这样做的好处是节省存储空间;坏处是对图进行基于边的计算时,对于一条两个顶点被分到不同机器上的边来说,要跨机器通信传输数据,内网通信流量大。
3.2 点分割(Vertex-Cut)
每条边只存储一次,都只会出现在一台机器上。邻居多的点会被复制到多台机器上,增加了存储开销,同时会引发数据同步问题。好处是可以大幅减少内网通信量。
3.3 对比
虽然两种方法互有利弊,但现在是点分割占上风,各种分布式图计算框架都将自己底层的存储形式变成了点分割。主要原因有以下两个。
磁盘价格下降,存储空间不再是问题,而内网的通信资源没有突破性进展,集群计算时内网带宽是宝贵的,时间比磁盘更珍贵。这点就类似于常见的空间换时间的策略。
在当前的应用场景中,绝大多数网络都是“无尺度网络”,遵循幂律分布,不同点的邻居数量相差非常悬殊。而边分割会使那些多邻居的点所相连的边大多数被分到不同的机器上,这样的数据分布会使得内网带宽更加捉襟见肘,于是边分割存储方式被渐渐抛弃了。
四、图计算模式
目前的图计算框架基本上都遵循BSP(Bulk Synchronous Parallell)计算模式。Bulk Synchronous Parallell,即整体同步并行,它将计算分成一系列的超步(superstep)的迭代(iteration)。从纵向上看,它是一个串行模型,而从横向上看,它是一个并行的模型,每两个superstep之间设置一个栅栏(barrier),即整体同步点,确定所有并行的计算都完成后再启动下一轮superstep。
4.1 超步
每一个超步(superstep)包含三部分内容:
1.计算compute,每一个processor利用上一个superstep传过来的消息和本地的数据进行本地计算;
2.消息传递,每一个processor计算完毕后,将消息传递个与之关联的其它processors;
3.整体同步点,用于整体同步,确定所有的计算和消息传递都进行完毕后,进入下一个superstep。
4.2 Pregel模型——像顶点一样思考
Pregel借鉴MapReduce的思想,采用消息在点之间传递数据的方式,提出了“像顶点一样思考”(Think Like A Vertex)的图计算模式,采用消息在点之间传递数据的方式,让用户无需考虑并行分布式计算的细节,只需要实现一个顶点更新函数,让框架在遍历顶点时进行调用即可。
常见的代码模板如下:

上图简要地描述了Pregel的计算模型:
1.master将图进行分区,然后将一个或多个partition分给worker;
2.worker为每一个partition启动一个线程,该线程轮询partition中的顶点,为每一个active状态的顶点调用compute方法;
3.compute完成后,按照edge的信息将计算结果通过消息传递方式传给其它顶点;
4.完成同步后,重复执行2,3操作,直到没有active状态顶点或者迭代次数到达指定数目。
这个模型虽然简洁,但很容易发现它的缺陷。对于邻居数很多的顶点,它需要处理的消息非常庞大,而且在这个模式下,它们是无法被并发处理的。所以对于符合幂律分布的自然图,这种计算模型下很容易发生假死或者崩溃。
作为第一个通用的大规模图处理系统,pregel已经为分布式图处理迈进了不小的一步,这点不容置疑,但是pregel在一些地方也不尽如人意:
1.在图的划分上,采用的是简单的hash方式,这样固然能够满足负载均衡,但是hash方式并不能根据图的连通特性进行划分,导致超步之间的消息传递开销可能会是影响性能的最大隐患。
2.简单的checkpoint机制只能向后式地将状态恢复到当前S超步的几个超步之前,要到达S还需要重复计算,这其实也浪费了很多时间,因此如何设计checkpoint,使得只需重复计算故障worker的partition的计算节省计算甚至可以通过checkpoint直接到达故障发生前一超步S,也是一个很需要研究的地方。
3.BSP模型本身有其局限性,整体同步并行对于计算快的worker长期等待的问题无法解决。
4.由于pregel目前的计算状态都是常驻内存的,对于规模继续增大的图处理可能会导致内存不足,如何解决尚待研究。
4.3 GAS模型——邻居更新模型
相比Pregel模型的消息通信范式,GraphLab的GAS模型更偏向共享内存风格。它允许用户的自定义函数访问当前顶点的整个邻域,可抽象成Gather、Apply和Scatter三个阶段,简称为GAS。相对应,用户需要实现三个独立的函数gather、apply和scatter。常见的代码模板如下所示:

由于gather/scatter函数是以单条边为操作粒度,所以对于一个顶点的众多邻边,可以分别由相应的worker独立调用gather/scatter函数。这一设计主要是为了适应点分割的图存储模式,从而避免Pregel模型会遇到的问题。
1.Gather阶段
工作顶点的边(可能是所有边,也有可能是入边或者出边)从领接顶点和自身收集数据,记为gather_data_i,各个边的数据graphlab会求和,记为sum_data。这一阶段对工作顶点、边都是只读的。
2.Apply阶段
Mirror将gather计算的结果sum_data发送给master顶点,master进行汇总为total。Master利用total和上一步的顶点数据,按照业务需求进行进一步的计算,然后更新master的顶点数据,并同步mirror。Apply阶段中,工作顶点可修改,边不可修改。
3.Scatter阶段
工作顶点更新完成之后,更新边上的数据,并通知对其有依赖的邻结顶点更新状态。这scatter过程中,工作顶点只读,边上数据可写。
在执行模型中,graphlab通过控制三个阶段的读写权限来达到互斥的目的。在gather阶段只读,apply对顶点只写,scatter对边只写。并行计算的同步通过master和mirror来实现,mirror相当于每个顶点对外的一个接口人,将复杂的数据通信抽象成顶点的行为。