zookeeper
使用场景
- Zookeeper作为一个分布式协调系统提供了一项基本服务:分布式锁服务,分布式锁是分布式协调技术实现的核心内容。像配置管理、任务分发、组服务、分布式消息队列、分布式通知/协调等,这些应用实际上都是基于这项基础服务由用户自己摸索出来的。
- 数据发布与订阅实现配置管理:发布与订阅即所谓的配置管理,顾名思义就是将数据发布到zk节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。例如全局的配置信息,地址列表等就非常适合使用。
- NameService:作为分布式命名服务,通过调用zk的create node api,能够很容易创建一个全局唯一的path,这个path就可以作为一个名称。
- 分布通知/协调:ZooKeeper 中特有watcher注册与异步通知机制,能够很好的实现分布式环境下不同系统之间的通知与协调,实现对数据变更的实时处理。使用方法通常是不同系统都对 ZK上同一个znode进行注册,监听znode的变化(包括znode本身内容及子节点的),其中一个系统update了znode,那么另一个系统能 够收到通知,并作出相应处理。使用zookeeper来进行分布式通知和协调能够大大降低系统之间的耦合。
- 分布式锁:主要得益于ZooKeeper为我们保证了数据的强一致性,即用户只要完全相信每时每刻,zk集群中任意节点(一个zk server)上的相同znode的数据是一定是相同的。锁服务可以分为两类,一个是保持独占,另一个是控制时序。控制时序中Zk的父节点(/distribute_lock)维持一份sequence,保证子节点创建的时序性,从而也形成了每个客户端的全局时序。
数据结构

- ZooKeeper命名空间中的Znode,兼具文件和目录两种特点。既像文件一样维护着数据、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分。
- 每个Znode由3部分组成:
- stat状态信息:描述该Znode的版本, 权限等信息
- data:与该Znode关联的数据(配置文件信息、状态信息、汇集位置),数据大小至多1M
- children:该Znode下的子节点
- ZooKeeper中的每个节点存储的数据要被原子性的操作。也就是说读操作将获取与节点相关的所有数据,写操作也将替换掉节点的所有数据。
- 另外,每一个节点都拥有自己的ACL(访问控制列表),这个列表规定了用户的权限,即限定了特定用户对目标节点可以执行的操作。
watch机制
- ZooKeeper可以为所有的读操作设置watch,包括:exists()、getChildren()及getData()。数据watch(data watches):getData和exists负责设置数据watch,孩子watch(child watches):getChildren负责设置孩子watch
- 当节点状态发生改变时(Znode的增、删、改)将会触发watch所对应的操作。当watch被触发时,ZooKeeper将会向客户端发送且仅发送一条通知,因为watch只能被触发一次,这样可以减少网络流量。
节点类型
- ZooKeeper中的节点有两种,分别为临时节点和永久节点(还可再分为有序无序)。
- 节点的类型在创建时即被确定,并且不能改变。
- 临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话(Session)结束,临时节点将被自动删除,当然可以也可以手动删除。虽然每个临时的Znode都会绑定到一个客户端会话,但他们对所有的客户端还是可见的。另外,ZooKeeper的临时节点不允许拥有子节点。(分布式队列)
- 永久节点:该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能被删除。
zookeeper 架构
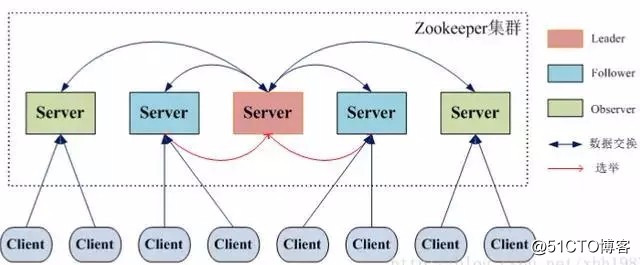
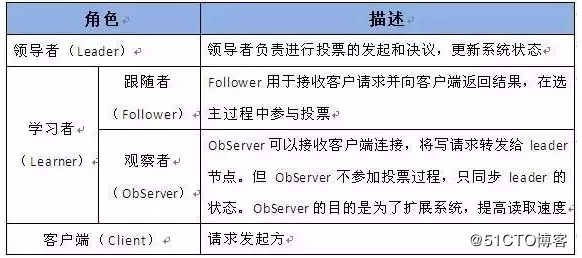
- 当集群节点数目逐渐增大为了支持更多的客户端,需要增加更多Server,然而Server增多,投票阶段延迟增大,影响性能。为了权衡伸缩性和高吞吐率,引入Observer:
- 每个Server在工作过程中有三种状态
- LOOKING:当前Server不知道leader是谁,正在搜寻。
- LEADING:当前Server即为选举出来的leader。
- FOLLOWING:leader已经选举出来,当前Server与之同步。
zookeeper工作原理
- 为了保证各个Server之间的同步, Zookeeper的核心是采用原子广播,实现这个原子广播的协议叫做Zab协议。
- 状态同步保证了leader和Server具有相同的系统状态。
- Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)
zab什么时候会进入恢复模式
- 当整个服务框架在启动过程中
- 当Leader服务器出现网络中断崩溃退出与重启等异常情况
- 当有新的服务器加入到集群中且集群处于正常状态(广播模式),新服会与leader进行数据同步,然后进入消息广播模式
zab恢复模式干了什么
- 选举产生新的Leader服务器,同时集群中已有的过半的机器会与该Leader完成状态同步,这些工作完成后,ZAB协议就会退出崩溃恢复模式
zab恢复模式选主过程
- 当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的 Server都恢复到一个正确的状态。
- Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。
- Basic paxos:当前Server发起选举的线程,向所有Server发起询问,选举线程收到所有回复,计算zxid最大Server,并推荐此为leader,若此提议获得n/2+1票通过,此为leader,否则重复上述流程,直到leader选出。
- Fast paxos:某Server首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决epoch和 zxid的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出Leader。(即提议方解决其他所有epoch和 zxid的冲突,即为leader)。
zk读写
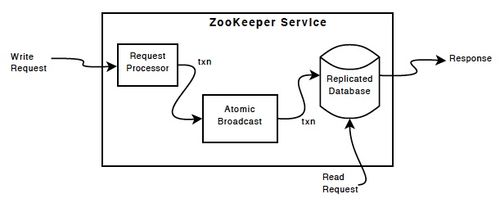
同步流程
- (1)Leader等待server连接;
- (2)Follower连接leader,将最大的zxid发送给leader;
- (3)Leader根据follower的zxid确定同步点,完成同步后通知follower 已经成为uptodate状态;
- (4)Follower收到uptodate消息后,又可以重新接受client的请求进行服务了

同步过程中的事务
- 为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
什么时候进入广播模式
- 集群状态稳定,有了leader且过半机器状态同步完成,退出崩溃恢复模式后进入消息广播模式
广播模式干了什么
- 正常的消息同步,把日常产生数据从leader同步到learner的过程
zk四字操作命令
- nc为netcat命令的简写
echo stat | nc localhost 2181
conf: 输出相关服务配置的详细信息。
cons: 列出所有连接到服务器的客户端的完全的连接 / 会话的详细信息。包括“接受 / 发送”的包数量、会话 id 、操作延迟、最后的操作执行等等信息。
dump: 列出未经处理的会话和临时节点。
envi: 输出关于服务环境的详细信息(区别于 conf 命令)。
reqs: 列出未经处理的请求
ruok: 测试服务是否处于正确状态。如果确实如此,那么服务返回“ imok ”,否则不做任何相应。
stat: 输出关于性能和连接的客户端的列表。
wchs: 列出服务器 watch 的详细信息。
wchc: 通过 session 列出服务器 watch 的详细信息,它的输出是一个与 watch 相关的会话的列表。
wchp: 通过路径列出服务器 watch 的详细信息。它输出一个与 session 相关的路径。
crst: 重置当前这台服务器所有连接/会话的统计信息
srst: 重置服务器的统计信息
srvr: 输出服务器的详细信息。zk版本、接收/发送包数量、连接数、模式(leader/follower)、节点总数。
还可以使用telnet查看是否启动成功
telnet 10.1.101.162 2181连接后按回车,然后输入四字命令
zk异常
- 在Java API中的每一个ZooKeeper操作都在其throws子句中声明了两种类型的异常,分别是InterruptedException和KeeperException。