分布式事务梳理
概念澄清
- 事务补偿机制
- 在事务链中的任何一个正向事务操作, 都必须存在一个完全符合回滚规则的可逆事务.
- CAP理论
- C:Consistency 一致性
同一数据的多个副本是否实时相同。
A:Availability 可用性
可用性:一定时间内 & 系统返回一个明确的结果 则称为该系统可用。
P:Partition tolerance 分区容错性 - CAP(Consistency, Availability, Partition Tolerance), 阐述了一个分布式系统的三个主要方面, 只能同时择其二进行实现. 常见的有CP系统, AP系统.
- C:Consistency 一致性
- 幂等性
- 简单的说, 业务操作支持重试, 不会产生不利影响. 常见的实现方式: 为消息额外增加唯一ID.
- BASE(Basically avaliable, soft state, eventually consistent):
- 是分布式事务实现的一种理论标准.
- CAP理论告诉我们一个悲惨但不得不接受的事实——我们只能在C、A、P中选择两个条件。而对于业务系统而言,我们往往选择牺牲一致性来换取系统的可用性和分区容错性。不过这里要指出的是,所谓的“牺牲一致性”并不是完全放弃数据一致性,而是牺牲强一致性换取弱一致性。下面来介绍下BASE理论。
- BA:Basic Available 基本可用
整个系统在某些不可抗力的情况下,仍然能够保证“可用性”,即一定时间内仍然能够返回一个明确的结果。只不过“基本可用”和“高可用”的区别是: “一定时间”可以适当延长 ,当举行大促时,响应时间可以适当延长,给部分用户返回一个降级页面 ,给部分用户直接返回一个降级页面,从而缓解服务器压力。但要注意,返回降级页面仍然是返回明确结果。
S:Soft State:柔性状态
同一数据的不同副本的状态,可以不需要实时一致。
E:Eventual Consisstency:最终一致性
同一数据的不同副本的状态,可以不需要实时一致,但一定要保证经过一定时间后仍然是一致的。
- 酸碱平衡
- ACID能够保证事务的强一致性,即数据是实时一致的。这在本地事务中是没有问题的,在分布式事务中,强一致性会极大影响分布式系统的性能,因此分布式系统中遵循BASE理论即可。但分布式系统的不同业务场景对一致性的要求也不同。如交易场景下,就要求强一致性,此时就需要遵循ACID理论,而在注册成功后发送短信验证码等场景下,并不需要实时一致,因此遵循BASE理论即可。因此要根据具体业务场景,在ACID和BASE之间寻求平衡。
柔性事务 vs. 刚性事务
- 刚性事务
- 指严格遵循ACID原则的事务, 例如单机环境下的数据库事务.
- 柔性事务
- 指遵循BASE理论的事务, 通常用在分布式环境中;
- 常见的实现方式有: 1.两阶段提交(2PC),2. TCC补偿型提交, 3.基于消息的异步确保型,4. 最大努力通知型.
- 场景区别
- 通常对本地事务采用刚性事务, 分布式事务使用柔性事务.
事务详解
-
两阶段提交(2PC)
- XA是一个分布式事务协议,由Tuxedo提出。XA中大致分为两部分:事务管理器和本地资源管理器。其中本地资源管理器往往由数据库实现,比如Oracle、DB2这些商业数据库都实现了XA接口,而事务管理器作为全局的调度者,负责各个本地资源的提交和回滚

- XA协议比较简单,而且一旦商业数据库实现了XA协议,使用分布式事务的成本也比较低,尽量保证了数据的强一致。但是,XA也有致命的缺点,那就是性能不理想,特别是在交易下单链路,往往并发量很高,XA无法满足高并发场景。XA目前在商业数据库支持的比较理想,在mysql数据库中支持的不太理想,mysql的XA实现,没有记录prepare阶段日志,主备切换回导致主库与备库数据不一致。许多nosql也没有支持XA,这让XA的应用场景变得非常狭隘。
-
消息事务+最终一致性
- 所谓的消息事务就是基于消息中间件的两阶段提交,本质上是对消息中间件的一种特殊利用,它是将本地事务和发消息放在了一个分布式事务里,保证要么本地操作成功成功并且对外发消息成功,要么两者都失败。然后另外一个系统根据消息消费区执行本地事务,最终实现一致。
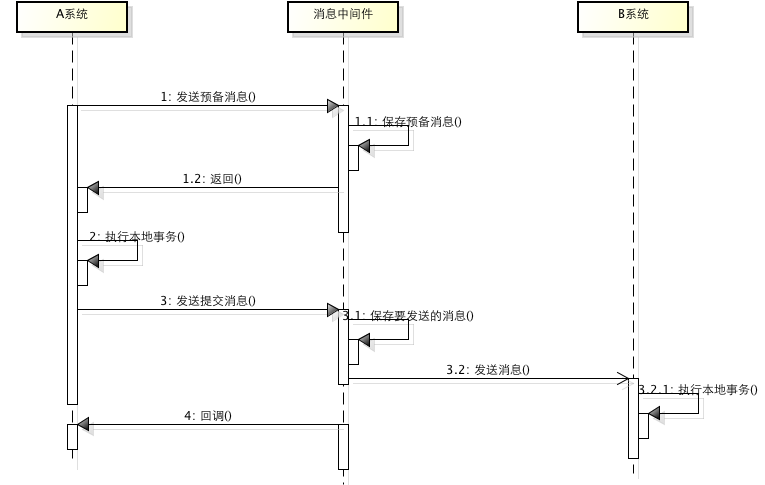
- 执行流程:
- A系统向消息中间件发送一条预备消息
- 2、消息中间件保存预备消息并返回成功
- 3、A执行本地事务
- 4、A发送提交消息给消息中间件
- 通过以上4步完成了一个消息事务。对于以上的4个步骤,每个步骤都可能产生错误,下面一一分析:
- 步骤一出错,则整个事务失败,不会执行A的本地操作
- 步骤二出错,则整个事务失败,不会执行A的本地操作
- 步骤三出错,这时候需要回滚预备消息,怎么回滚?答案是A系统实现一个消息中间件的回调接口,消息中间件会去不断执行回调接口,检查A事务执行是否执行成功,如果失败则回滚预备消息
- 步骤四出错,这时候A的本地事务是成功的,那么消息中间件要回滚A吗?答案是不需要,其实通过回调接口,消息中间件能够检查到A执行成功了,这时候其实不需要A发提交消息了,消息中间件可以自己对消息进行提交,从而完成整个消息事务。
- 虽然上面的方案能够完成A和B的操作,但是A和B并不是严格一致的,而是最终一致的,我们在这里牺牲了一致性,换来了性能的大幅度提升。当然,这种玩法也是有风险的,如果B一直执行不成功,那么一致性会被破坏,具体要不要玩,还是得看业务能够承担多少风险。
-
补偿事务TCC编程模式
- TCC 其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。它分为三个阶段:
- Try 阶段主要是对业务系统做检测及资源预留
- Confirm 阶段主要是对业务系统做确认提交,Try阶段执行成功并开始执行 Confirm阶段时,默认 Confirm阶段是不会出错的。即:只要Try成功,Confirm一定成功。
- Cancel 阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。
- 举个例子,假入 Bob 要向 Smith 转账,思路大概是:
我们有一个本地方法,里面依次调用
1、首先在 Try 阶段,要先调用远程接口把 Smith 和 Bob 的钱给冻结起来。
2、在 Confirm 阶段,执行远程调用的转账的操作,转账成功进行解冻。
3、如果第2步执行成功,那么转账成功,如果第二步执行失败,则调用远程冻结接口对应的解冻方法 (Cancel)。 - 优点: 跟2PC比起来,实现以及流程相对简单了一些,但数据的一致性比2PC也要差一些
- 缺点: 缺点还是比较明显的,在2,3步中都有可能失败。TCC属于应用层的一种补偿方式,所以需要程序员在实现的时候多写很多补偿的代码,在一些场景中,一些业务流程可能用TCC不太好定义及处理。
- TCC 其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。它分为三个阶段:
-
最大努力通知(定期校对)
- 上游系统在完成任务后,向消息中间件同步地发送一条消息,确保消息中间件成功持久化这条消息,然后上游系统可以去做别的事情了;
- 消息中间件收到消息后负责将该消息同步投递给相应的下游系统,并触发下游系统的任务执行;
- 当下游系统处理成功后,向消息中间件反馈确认应答,消息中间件便可以将该条消息删除,从而该事务完成。
- 上面是一个理想化的过程,但在实际场景中,往往会出现如下几种意外情况:
- 消息中间件向下游系统投递消息失败
- 上游系统向消息中间件发送消息失败
- 对于第一种情况,消息中间件具有重试机制,我们可以在消息中间件中设置消息的重试次数和重试时间间隔,对于网络不稳定导致的消息投递失败的情况,往往重试几次后消息便可以成功投递,如果超过了重试的上限仍然投递失败,那么消息中间件不再投递该消息,而是记录在失败消息表中,消息中间件需要提供失败消息的查询接口,下游系统会定期查询失败消息,并将其消费,这就是所谓的“定期校对”。
- 如果重复投递和定期校对都不能解决问题,往往是因为下游系统出现了严重的错误,此时就需要人工干预。
- 对于第二种情况,需要在上游系统中建立消息重发机制。可以在上游系统建立一张本地消息表,并将 任务处理过程 和 向本地消息表中插入消息 这两个步骤放在一个本地事务中完成。如果向本地消息表插入消息失败,那么就会触发回滚,之前的任务处理结果就会被取消。如果这量步都执行成功,那么该本地事务就完成了。接下来会有一个专门的消息发送者不断地发送本地消息表中的消息,如果发送失败它会返回重试。当然,也要给消息发送者设置重试的上限,一般而言,达到重试上限仍然发送失败,那就意味着消息中间件出现严重的问题,此时也只有人工干预才能解决问题。
- 对于不支持事务型消息的消息中间件,如果要实现分布式事务的话,就可以采用这种方式。它能够通过重试机制+定期校对实现分布式事务,但相比于第二种方案,它达到数据一致性的周期较长,而且还需要在上游系统中实现消息重试发布机制,以确保消息成功发布给消息中间件,这无疑增加了业务系统的开发成本,使得业务系统不够纯粹,并且这些额外的业务逻辑无疑会占用业务系统的硬件资源,从而影响性能。
- 因此,尽量选择支持事务型消息的消息中间件来实现分布式事务,如RocketMQ。
最佳实践
- 如果业务场景需要强一致性, 那么尽量避免将它们放在不同服务中, 也就是尽量使用本地事务, 避免使用强一致性的分布式事务.
- 如果业务场景能够接受最终一致性, 那么最好是使用基于消息的最终一致性的方案(异步确保型)来解决.
- 如果业务场景需要强一致性, 并且只能够进行分布式服务部署, 那么最好是使用TCC方案而不是2PC方案来解决.