| 现今互联网界,分布式系统和微服务架构盛行。一个简单操作,在服务端非常可能是由多个服务和数据库实例协同完成的。在一致性要求较高的场景下,多个独立操作之间的一致性问题显得格外棘手。基于水平扩容能力和成本考虑,传统的强一致的解决方案(e.g.单机事务)纷纷被抛弃。其理论依据就是响当当的CAP原理。往往为了可用性和分区容错性,忍痛放弃强一致支持,转而追求最终一致性。分布式系统的特性在分布式系统中,同时满足... | ||||
|
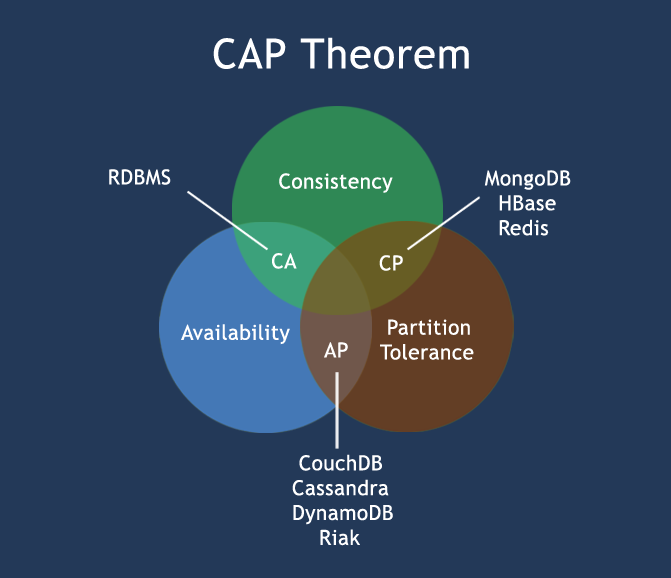
现今互联网界,分布式系统和微服务架构盛行。一个简单操作,在服务端非常可能是由多个服务和数据库实例协同完成的。在一致性要求较高的场景下,多个独立操作之间的一致性问题显得格外棘手。 基于水平扩容能力和成本考虑,传统的强一致的解决方案(e.g.单机事务)纷纷被抛弃。其理论依据就是响当当的CAP原理。往往为了可用性和分区容错性,忍痛放弃强一致支持,转而追求最终一致性。 分布式系统的特性 在分布式系统中,同时满足CAP定律中的一致性 Consistency、可用性 Availability和分区容错性 Partition Tolerance三者是不可能的。在绝大多数的场景,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证最终一致性。
CAP理解:
ACID理解:
分布式事务的基本介绍 分布式事务服务(Distributed Transaction Service,DTS)是一个分布式事务框架,用来保障在大规模分布式环境下事务的最终一致性。 CAP理论告诉我们在分布式存储系统中,最多只能实现上面的两点。而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的,所以我们只能在一致性和可用性之间进行权衡。 为了保障系统的可用性,互联网系统大多将强一致性需求转换成最终一致性的需求,并通过系统执行幂等性的保证,保证数据的最终一致性。 数据一致性理解:
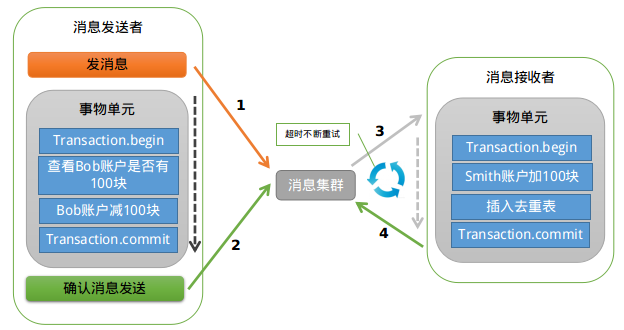
常用的分布式技术说明 1. 本地消息表 这种实现方式的思路是源于ebay,其基本的设计思想是将远程分布式事务拆分成一系列的本地事务。 举个经典的跨行转账的例子来描述。 第一步伪代码如下,扣款1W,通过本地事务保证了凭证消息插入到消息表中。
第二步,通知对方银行账户上加1W了,通常采用两种方式:
2. 消息中间件 非事务性的消息中间件 还是以上述提到的跨行转账为例,我们很难保证在扣款完成之后对MQ投递消息的操作就一定能成功。这样一致性似乎很难保证。
我们来分析下可能的情况:
从上面分析的几种情况来看,基本上能保证发送者发送消息的可靠性。我们再来分析下消费者端面临的问题:
支持事务的消息中间件 除了上面介绍的通过异常捕获和回滚的方式外,还有没有其他的思路呢? 阿里巴巴的RocketMQ中间件就支持一种事务消息机制,能够确保本地操作和发送消息达到本地事务一样的效果。
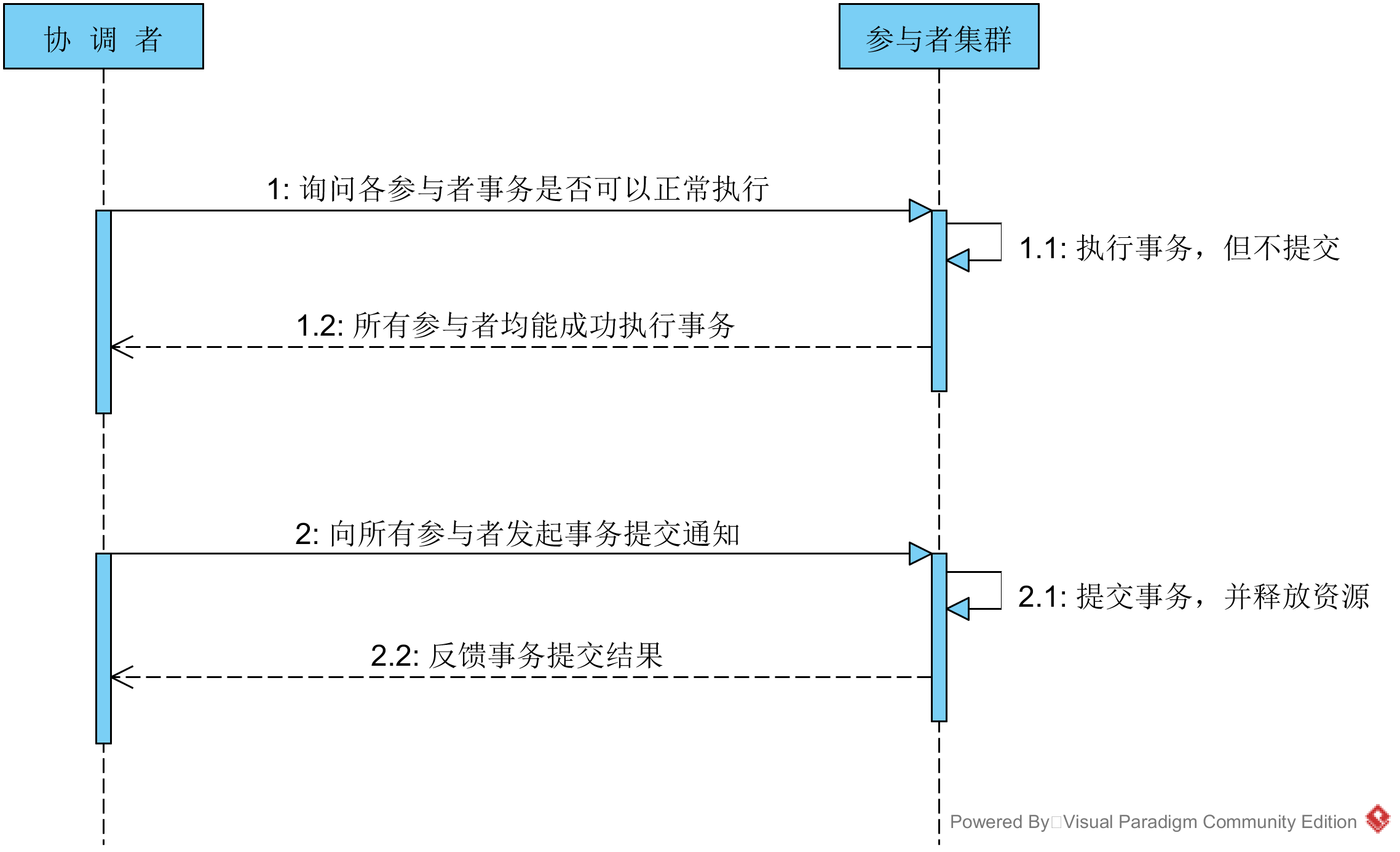
但是如果第三阶段的确认消息发送失败了怎么办?RocketMQ会定期扫描消息集群中的事物消息,如果发现了prepare状态的消息,它会向消息发送者确认本地事务是否已执行成功,如果成功是回滚还是继续发送确认消息呢。RocketMQ会根据发送端设置的策略来决定是回滚还是继续发送确认消息。这样就保证了消息发送与本地事务同时成功或同时失败。 目前主流的开源MQ(ActiveMQ、RabbitMQ、Kafka)均未实现对事务消息的支持,比较遗憾的是,RocketMQ事务消息部分的代码也并未开源,需要自己去实现。 理解2PC和3PC协议 为了解决分布式一致性问题,前人在性能和数据一致性的反反复复权衡过程中总结了许多典型的协议和算法。其中比较著名的有二阶提交协议(2 Phase Commitment Protocol),三阶提交协议(3 Phase Commitment Protocol)。 2PC 分布式事务最常用的解决方案就是二阶段提交。在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事务的ACID特性,需要引入一个作为协调者的组件来统一掌控所有参与者节点的操作结果并最终指示这些节点是否要把操作结果进行真正的提交。 因此,二阶段提交的算法思路可以概括为:参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。 所谓的两个阶段是指:第一阶段:准备阶段(投票阶段)和第二阶段:提交阶段(执行阶段)。 第一阶段:投票阶段 该阶段的主要目的在于打探数据库集群中的各个参与者是否能够正常的执行事务,具体步骤如下: 1. 协调者向所有的参与者发送事务执行请求,并等待参与者反馈事务执行结果。 2. 事务参与者收到请求之后,执行事务,但不提交,并记录事务日志。 3. 参与者将自己事务执行情况反馈给协调者,同时阻塞等待协调者的后续指令。 第二阶段:事务提交阶段 在第一阶段协调者的询盘之后,各个参与者会回复自己事务的执行情况,这时候存在三种可能: 1. 所有的参与者回复能够正常执行事务。 2. 一个或多个参与者回复事务执行失败。 3. 协调者等待超时。 对于第一种情况,协调者将向所有的参与者发出提交事务的通知,具体步骤如下: 1. 协调者向各个参与者发送commit通知,请求提交事务。 2. 参与者收到事务提交通知之后,执行commit操作,然后释放占有的资源。 3. 参与者向协调者返回事务commit结果信息。
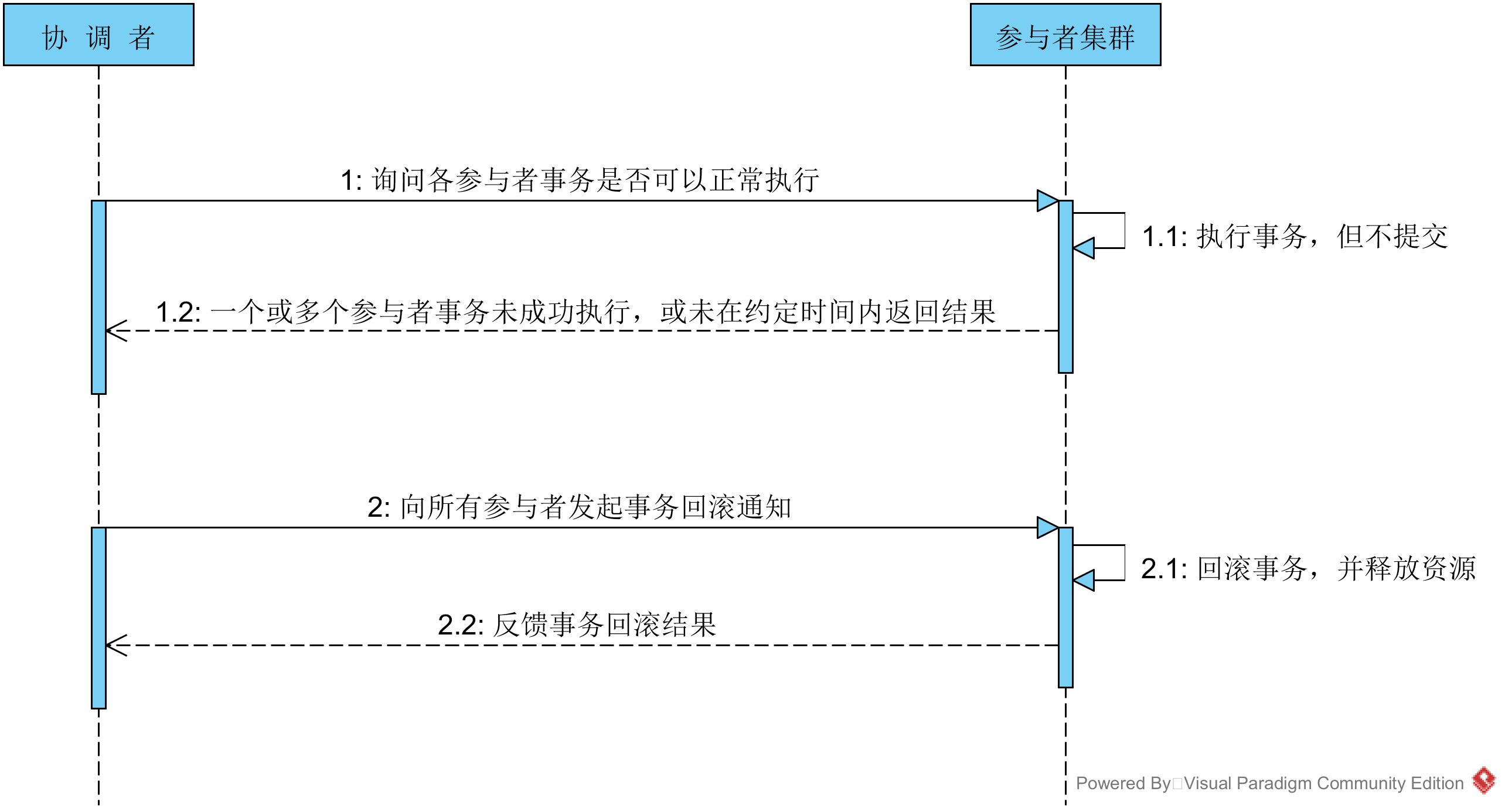
对于第二、三种情况,协调者均认为参与者无法正常成功执行事务,为了整个集群数据的一致性,所以要向各个参与者发送事务回滚通知,具体步骤如下: 1. 协调者向各个参与者发送事务rollback通知,请求回滚事务。 2. 参与者收到事务回滚通知之后,执行rollback操作,然后释放占有的资源。 3. 参与者向协调者返回事务rollback结果信息。
两阶段提交协议解决的是分布式数据库数据强一致性问题,其原理简单,易于实现,但是缺点也是显而易见的,主要缺点如下:
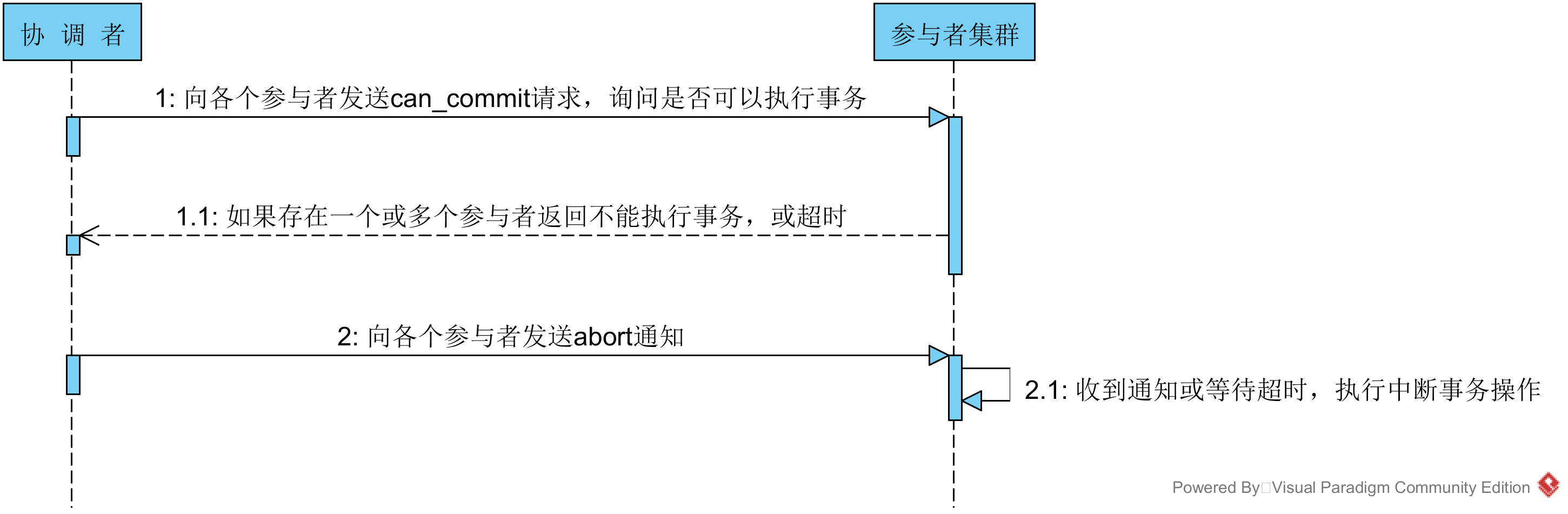
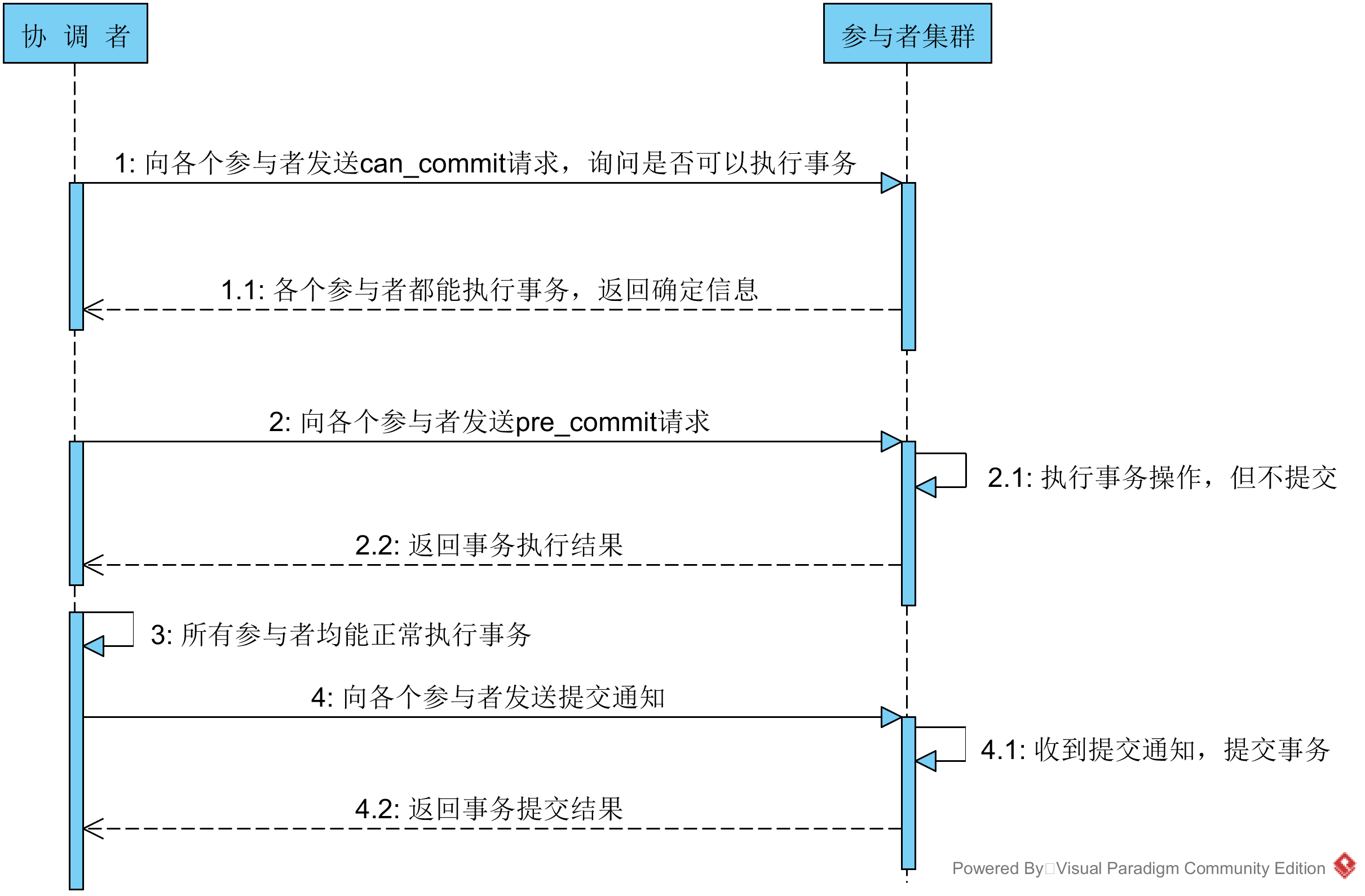
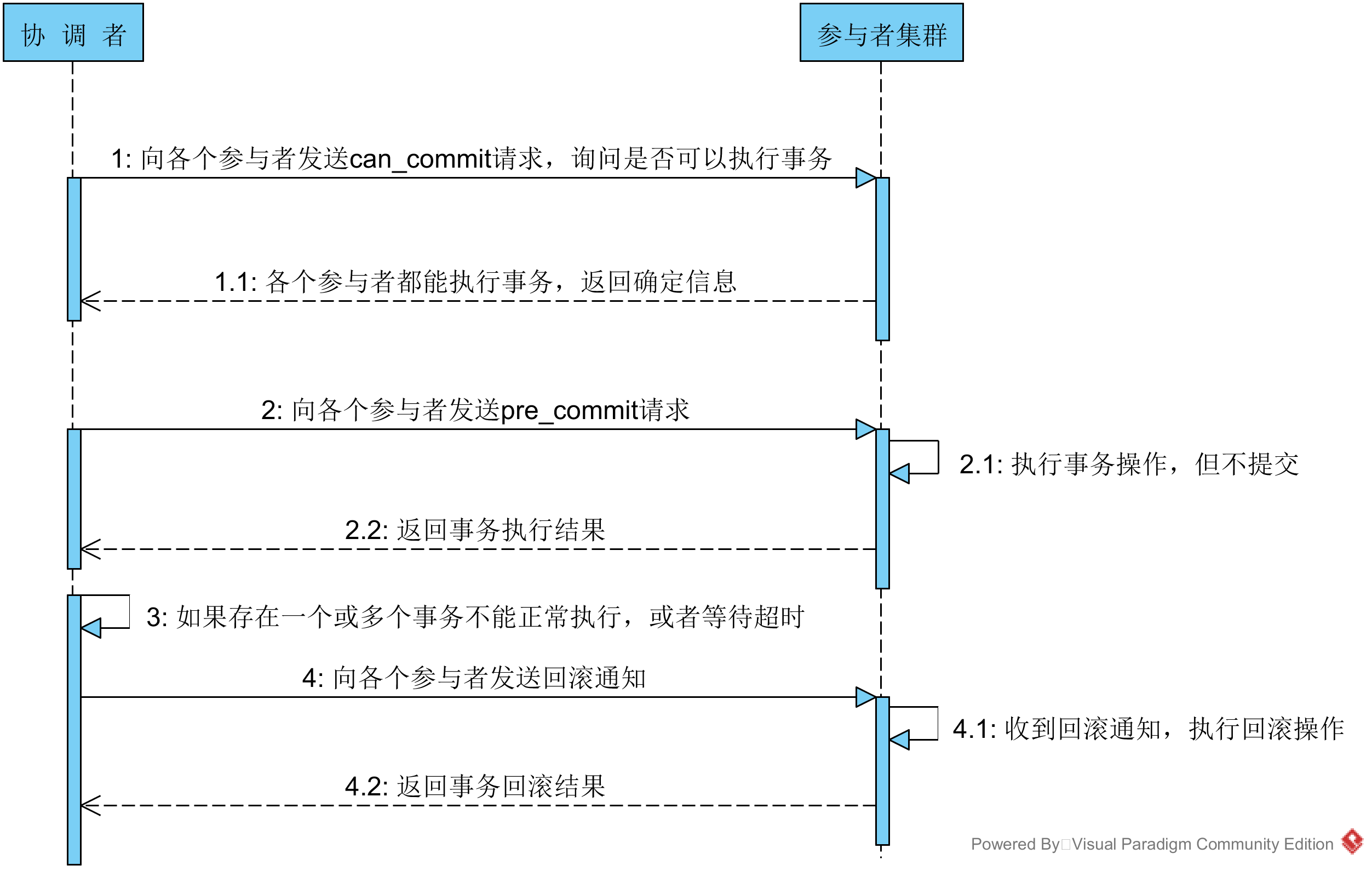
3PC 针对两阶段提交存在的问题,三阶段提交协议通过引入一个“预询盘”阶段,以及超时策略来减少整个集群的阻塞时间,提升系统性能。三阶段提交的三个阶段分别为:can_commit,pre_commit,do_commit。 第一阶段:can_commit 该阶段协调者会去询问各个参与者是否能够正常执行事务,参与者根据自身情况回复一个预估值,相对于真正的执行事务,这个过程是轻量的,具体步骤如下: 1. 协调者向各个参与者发送事务询问通知,询问是否可以执行事务操作,并等待回复。 2. 各个参与者依据自身状况回复一个预估值,如果预估自己能够正常执行事务就返回确定信息,并进入预备状态,否则返回否定信息。 第二阶段:pre_commit 本阶段协调者会根据第一阶段的询盘结果采取相应操作,询盘结果主要有三种: 1. 所有的参与者都返回确定信息。 2. 一个或多个参与者返回否定信息。 3. 协调者等待超时。 针对第一种情况,协调者会向所有参与者发送事务执行请求,具体步骤如下: 1. 协调者向所有的事务参与者发送事务执行通知。 2. 参与者收到通知后,执行事务,但不提交。 3. 参与者将事务执行情况返回给客户端。 在上面的步骤中,如果参与者等待超时,则会中断事务。 针对第二、三种情况,协调者认为事务无法正常执行,于是向各个参与者发出abort通知,请求退出预备状态,具体步骤如下: 1. 协调者向所有事务参与者发送abort通知 2. 参与者收到通知后,中断事务
第三阶段:do_commit 如果第二阶段事务未中断,那么本阶段协调者将会依据事务执行返回的结果来决定提交或回滚事务,分为三种情况: 1. 所有的参与者都能正常执行事务。 2. 一个或多个参与者执行事务失败。 3. 协调者等待超时。 针对第一种情况,协调者向各个参与者发起事务提交请求,具体步骤如下: 1. 协调者向所有参与者发送事务commit通知。 2. 所有参与者在收到通知之后执行commit操作,并释放占有的资源。 3. 参与者向协调者反馈事务提交结果。
针对第二、三种情况,协调者认为事务无法正常执行,于是向各个参与者发送事务回滚请求,具体步骤如下: 1. 协调者向所有参与者发送事务rollback通知。 2. 所有参与者在收到通知之后执行rollback操作,并释放占有的资源。 3. 参与者向协调者反馈事务提交结果。
在本阶段如果因为协调者或网络问题,导致参与者迟迟不能收到来自协调者的commit或rollback请求,那么参与者将不会如两阶段提交中那样陷入阻塞,而是等待超时后继续commit。相对于两阶段提交虽然降低了同步阻塞,但仍然无法避免数据的不一致性。 Reference https://zhuanlan.zhihu.com/p/25933039 http://www.infoq.com/cn/articles/solution-of-distributed-system-transaction-consistency http://blog.csdn.net/jasonsungblog/article/details/49017955 http://blog.csdn.net/suifeng3051/article/details/52691210 https://my.oschina.net/wangzhenchao/blog/736909 转载请并标注: “本文转载自 linkedkeeper.com (文/张松然)” |