零散小记
id(对象) ----> 查看内存地址
type(对象) ----> 查看对象的类
bytes(s, encoding='utf-8') ----> 将字符串s转换成字节, 默认16进制
str(x, encoding='utf-8') ----> 将字节码x转换成字符串
bin() ----> 10进制转为2进制
UTF-8 编码, 1 个汉字 3 个字节 ,1 个字节 8 位
GBK 编码, 1 个汉字 2 个字节
python3.5 中按字符来处理,比如在for循环中,len("请问")=2
python2.7 中按字节来处理,len("请问")=6 (utf8)
list(): 可以将字符串,元组,字典dic.values() dic.items() dic 转为列表
s = '你好' l = list(s) #for循环s的每一个元素作为列表中的元素 print(l) #结果为: ['你', '好']
dic = {
'k1': 'popo',
'k2': 'qwqw',
'k3': 'qweqwe'
}
li = list(dic)
print(li)
#结果为
['k3', 'k2', 'k1']
dic = {
'k1': 'popo',
'k2': 'qwqw',
'k3': 'qweqwe'
}
li = list(dic.items())
print(li)
#结果为
[('k3', 'qweqwe'), ('k1', 'popo'), ('k2', 'qwqw')]
dic = {
'k1': 'popo',
'k2': 'qwqw',
'k3': 'qweqwe'
}
li = list(dic.values())
print(li)
#resoult:
['qweqwe', 'qwqw', 'popo']
列表 索引 和 切片 的区别, 可见索引取出单个元素,而切片取出的是集合(跟原类型一致)
>>> li = ["abc", "cde", "fgh"] >>> li[1] 'cde' >>> li[1:2] ['cde']
可以跟其它类型相互嵌套
元组的元素不可修改,但元素的元素可以被修改
>>> tup = ('abc', 'cde', ['aaa', 'bbb', 'ccc'], {'k1': 'v1', 'k2': 'v2'})
>>> print(tup)
('abc', 'cde', ['aaa', 'bbb', 'ccc'], {'k1': 'v1', 'k2': 'v2'})
>>> tup[2].insert(1, 'xxx')
>>> print(tup)
('abc', 'cde', ['aaa', 'xxx', 'bbb', 'ccc'], {'k1': 'v1', 'k2': 'v2'})
在字典中追加键值对
tup = ('abc', 'cde', ('aaa', 'bbb', 'ccc', {'k1': 'v1', 'k2': 'v2'}))
print(tup)
tup[2][3].update({'k3': 'v3'})
print(tup)
tup[2][3]['k4'] = 'v4'
print(tup)
#>>>>>>>
('abc', 'cde', ('aaa', 'bbb', 'ccc', {'k2': 'v2', 'k1': 'v1'}))
('abc', 'cde', ('aaa', 'bbb', 'ccc', {'k2': 'v2', 'k3': 'v3', 'k1': 'v1'}))
('abc', 'cde', ('aaa', 'bbb', 'ccc', {'k4': 'v4', 'k2': 'v2', 'k3': 'v3', 'k1': 'v1'}))
创建字典:
d = dict(k1 = 'v1', k2 = 'v2')
print(d)
#>>>>>>
{'k2': 'v2', 'k1': 'v1'}
l = ['qqq', 'www', 'eee']
di = dict(enumerate(l, 8))
print(di)
#>>>>>>
{8: 'qqq', 9: 'www', 10: 'eee'}
fromkeys() 的特别之处
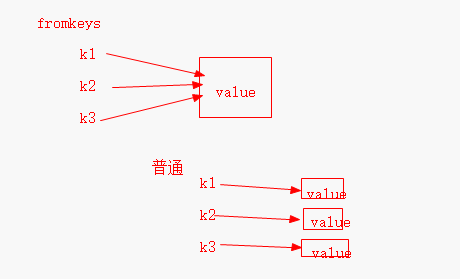
dic = dict.fromkeys(['k1', 'k2', 'k3'], [])
print(dic)
dic['k3'].append('xxx')
print(dic)
#>>>>>>
{'k3': [], 'k2': [], 'k1': []}
{'k3': ['xxx'], 'k2': ['xxx'], 'k1': ['xxx']}
d2 = {'k1': [], 'k2': [], 'k3': []}
print(d2)
d2['k3'].append('xxx')
print(d2)
#>>>>>>
{'k3': [], 'k2': [], 'k1': []}
{'k3': ['xxx'], 'k2': [], 'k1': []}